共找到2條詞條名為高速緩衝存儲器的結果 展開
- 高速緩衝存儲器
- CPU緩存
高速緩衝存儲器
高速緩衝存儲器
高速緩衝存儲器(Cache)其原始意義是指存取速度比一般隨機存取記憶體(RAM)來得快的一種RAM,一般而言它不像系統主記憶體那樣使用DRAM技術,而使用昂貴但較快速的SRAM技術,也有快取記憶體的名稱。
高速緩衝存儲器是存在於主存與CPU之間的一級存儲器,由靜態存儲晶元(SRAM)組成,容量比較小但速度比主存高得多,接近於CPU的速度。在計算機存儲系統的層次結構中,是介於中央處理器和主存儲器之間的高速小容量存儲器。它和主存儲器一起構成一級的存儲器。高速緩衝存儲器和主存儲器之間信息的調度和傳送是由硬體自動進行的。
高速緩衝存儲器最重要的技術指標是它的命中率。
主要由三徠大部分組成:
Cache存儲體:存放由主存調入的指令與數據塊。
地址轉換部件:建立目錄表以實現主存地址到緩存地址的轉換。
替換部件:在緩存已滿時按一定策略進行數據塊替換,並修改地址轉換部件。
在計算機存儲系統的層次結構中,介於中央處理器和主存儲器之間的高速小容量存儲器。程序員感覺不到高速緩衝存儲器的存在,因而它對程序員是透明的。
一種特殊的存儲器子系統,其中複製了頻繁使用的數據以利於快速訪問。存儲器的高速緩衝存儲器存儲了頻繁訪問的RAM位置的內容及這些數據項的存儲地址。當處理器引用存儲器中的某地址時,高速緩衝存儲器便檢查是否存有該地址。如果存有該地址,則將數據返回處理器;如果沒有保存該地址,則進行常規的存儲器訪問。因為高速緩衝存儲器總是比主RAM存儲器速度快,所以當RAM的訪問速度低於微處理器的速度時,常使用高速緩衝存儲器。另見waitstate。
Cache的出現是基於兩種因素:首先,是由於CPU的速度和性能提高很快而主存速度較低且價格高,第二就是程序執行的局部性特點。因此,才將速度比較快而容量有限的SRAM構成Cache,目的在於儘可能發揮CPU的高速度。很顯然,要儘可能發揮CPU的高速度就必須用硬體實現其全部功能。
Cache與主存之間可採取多種地址映射方式,直接映射方式是其中的一種。在這種映射方式下,主存中的每一頁只能複製到某一固定的Cache頁中。由於Cache塊(頁)的大小為16B,而Cache容量為16KB。因此,此Cache可分為1024頁。可以看到,Cache的頁內地址只需4位即可表示;而Cache的頁號需用10位二進位數來表示;在映射時,是將主存地址直接複製,現主存地址為1234E8F8(十六進位),則最低4位為Cache的頁內地址,即1000,中間10位為Cache的頁號,即1010001111。Cache的容量為16KB決定用這14位編碼即可表示。題中所需求的Cache的地址為10100011111000。
Cache中的內容隨命中率的降低需要經常替換新的內容。替換演演算法有多種,例如,先入后出(FILO)演演算法、隨機替換(RAND)演演算法、先入先出(FIFO)演演算法、近期最少使用(LRU)演演算法等。這些替換演演算法各有優缺點,就以命中率而言,近期最少使用(LRU)演演算法的命中率最高。
高速緩衝存儲器
高速緩衝存儲器的容量一般只有主存儲器的幾百分之一,但它的存取速度能與中央處理器相匹配。根據程序局部性原理,正在使用的主存儲器某一單元鄰近的那些單元將被用到的可能性很大。因而,當中央處理器存取主存儲器某一單元時,計算機硬體就自動地將包括該單元在內的那一組單元內容調入高速緩衝存儲器,中央處理器即將存取的主存儲器單元很可能就在剛剛調入到高速緩衝存儲器的那一組單元內。於是,中央處理器就可以直接對高速緩衝存儲器進行存取。在整個處理過程中,如果中央處理器絕大多數存取主存儲器的操作能為存取高速緩衝存儲器所代替,計算機系統處理速度就能顯著提高。
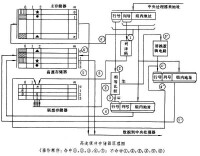
高速緩衝存儲器通常由高速存儲器、聯想存儲器、替換邏輯電路和相應的控制線路組成(見圖)。在有高速緩衝存儲器的計算機系統中,中央處理器存取主存儲器的地址劃分為行號、列號和組內地址三個欄位。於是,主存儲器就在邏輯上劃分為若干行;每行劃分為若干的存儲單元組;每組包含幾個或幾十個字。高速存儲器也相應地劃分為行和列的存儲單元組。二者的列數相同,組的大小也相同,但高速存儲器的行數卻比主存儲器的行數少得多。聯想存儲器用於地址聯想,有與高速存儲器相同行數和列數的存儲單元。當主存儲器某一列某一行存儲單元組調入高速存儲器同一列某一空著的存儲單元組時,與聯想存儲器對應位置的存儲單元就記錄調入的存儲單元組在主存儲器中的行號。當中央處理器存取主存儲器時,硬體首先自動對存取地址的列號欄位進行解碼,以便將聯想存儲器該列的全部行號與存取主存儲器地址的行號欄位進行比較:若有相同的,表明要存取的主存儲器單元已在高速存儲器中,稱為命中,硬體就將存取主存儲器的地址映射為高速存儲器的地址並執行存取操作;若都不相同,表明該單元不在高速存儲器中,稱為脫靶,硬體將執行存取主存儲器操作並自動將該單元所在的那一主存儲器單元組調入高速存儲器相同列中空著的存儲單元組中,同時將該組在主存儲器中的行號存入聯想存儲器對應位置的單元內。
當出現脫靶而高速存儲器對應列中沒有空的位置時,便淘汰該列中的某一組以騰出位置存放新調入的組,這稱為替換。確定替換的規則叫替換演演算法,常用的替換演演算法有:最近最少使用法(LRU)、先進先出法(FIFO)和隨機法(RAND)等。替換邏輯電路就是執行這個功能的。另外,當執行寫主存儲器操作時,為保持主存儲器和高速存儲器內容的一致性,對命中和脫靶須分別處理:①寫操作命中時,可採用寫直達法(即同時寫入主存儲器和高速存儲器)或寫回法(即只寫入高速存儲器並標記該組修改過。淘汰該組時須將內容寫回主存儲器);②寫操作脫靶時,可採用寫分配法(即寫入注存儲器並將該組調入高速存儲器)或寫不分配法(即只寫入主存儲器但不將該組調入高速存儲器)。
高速緩衝存儲器的性能常用命中率來衡量。影響命中率的因素是高速存儲器的容量、存儲單元組的大小、組數多少、地址聯想比較方法、替換演演算法、寫操作處理方法和程序特性等。採用高速緩衝存儲器技術的計算機已相當普遍。有的計算機還採用多個高速緩衝存儲器,如系統高速緩衝存儲器、指令高速緩衝存儲器和地址變換高速緩衝存儲器等,以提高系統性能。隨著主存儲器容量不斷增大,高速緩衝存儲器的容量也越來越大。
緩存用於存儲一些臨時的文件。在瀏覽網頁的過程中,網頁會自動存儲在用戶的硬碟上。下次再瀏覽相同的網站的時候,系統會自動從硬碟中調出該網頁,既節省了時間也減少了網路的交換。用戶可以自行設定緩存方便其上網的需要。電腦中還存在高速緩衝存儲器和硬碟緩存。緩存的種類:本地伺服器緩存、網頁緩存、硬碟緩存、一級高速緩存、二級高速緩存。
cache是一個高速小容量的臨時存儲器,可以用高速的靜態存儲器晶元實現,或者集成到CPU晶元內部,存儲CPU最經常訪問的指令或者操作數據。
CPU與cache之間的數據交換是以字為單位,而cache與主存之間的數據交換是以塊為單位。一個塊由若干定長字組成的。當CPU讀取主存中一個字時,便發出此字的內存地址到cache和主存。此時cache控制邏輯依據地址判斷此字當前是否在cache中:若是,此字立即傳送給CPU;若非,則用主存讀周期把此字從主存讀出送到CPU,與此同時,把含有這個字的整個數據塊從主存讀出送到cache中。由始終管理cache使用情況的硬體邏輯電路來實現LRU替換演演算法。
由於主存容量遠大於高速緩存的容量,因此兩者之間就必須按一定的規則對應起來。高速緩存的地址鏡像就是指按什麼規則把主存塊裝入高速緩存中。地址變換是指當按某種鏡像方式把主存塊裝入高速緩存后,每次訪問高速緩存時,如何把主存的物理地址或虛擬地址變換成高速緩存的地址,從而訪問高速緩存中的數據。
鏡像和變換的方式有四種:直接鏡像、全相連鏡像、組相連鏡像、區段相連鏡像。
buffer與cache操作的對象就不一樣。
buffer(緩衝)是為了提高內存和硬碟(或其他I/0設備)之間的數據交換的速度而設計的。
cache(緩存)是為了提高cpu和內存之間的數據交換速度而設計,也就是平常見到的一級緩存、二級緩存、三級緩存。
cpu在執行程序所用的指令和讀數據都是針對內存的,也就是從內存中取得的。由於內存讀寫速度慢,為了提高cpu和內存之間數據交換的速度,在cpu和內存之間增加了cache,它的速度比內存快,但是造價高,又由於在cpu內不能集成太多集成電路,所以一般cache比較小,以後intel等公司為了進一步提高速度,又增加了二級cache,甚至三級cache,它是根據程序的局部性原理而設計的,就是cpu執行的指令和訪問的數據往往在集中的某一塊,所以把這塊內容放入cache后,cpu就不用在訪問內存了,這就提高了訪問速度。當然若cache中沒有cpu所需要的內容,還是要訪問內存的。
緩衝(buffers)是根據磁碟的讀寫設計的,把分散的寫操作集中進行,減少磁碟碎片和硬碟的反覆尋道,從而提高系統性能。linux有一個守護進程定期清空緩衝內容(即寫入磁碟),也可以通過sync命令手動清空緩衝。舉個例子吧:我這裡有一個ext2的U盤,我往裡面cp一個3M的MP3,但U盤的燈沒有跳動,過了一會兒(或者手動輸入sync)U盤的燈就跳動起來了。卸載設備時會清空緩衝,所以有些時候卸載一個設備時要等上幾秒鐘。
修改/etc/sysctl.conf中的vm.swappiness右邊的數字可以在下次開機時調節swap使用策略。該數字範圍是0~100,數字越大越傾向於使用swap。默認為60,可以改一下試試。--兩者都是RAM中的數據。
簡單來說,buffer是即將要被寫入磁碟的,而cache是被從磁碟中讀出來的。
buffer是由各種進程分配的,被用在如輸入隊列等方面。一個簡單的例子如某個進程要求有多個欄位讀入,在所有欄位被讀入完整之前,進程把先前讀入的欄位放在buffer中保存。
cache經常被用在磁碟的I/O請求上,如果有多個進程都要訪問某個文件,於是該文件便被做成cache以方便下次被訪問,這樣可提高系統性能。
CPU在Cache中找到有用的數據被稱為命中,當Cache中沒有CPU所需的數據時(這時稱為未命中),CPU才訪問內存。從理論上講,在一顆擁有2級Cache的CPU中,讀取L1Cache的命中率為80%。也就是說CPU從L1Cache中找到的有用數據占數據總量的80%,剩下的20%從L2Cache讀取。由於不能準確預測將要執行的數據,讀取L2的命中率也在80%左右(從L2讀到有用的數據佔總數據的16%)。那麼還有的數據就不得不從內存調用,但這已經是一個相當小的比例了。在一些高端領域的CPU中,我們常聽到L3Cache,它是為讀取L2Cache后未命中的數據設計的—種Cache,在擁有L3Cache的CPU中,只有約5%的數據需要從內存中調用,這進一步提高了CPU的效率。
為了保證CPU訪問時有較高的命中率,Cache中的內容應該按一定的演演算法替換。一種較常用的演演算法是“最近最少使用演演算法”(LRU演演算法),它是將最近一段時間內最少被訪問過的行淘汰出局。因此需要為每行設置一個計數器,LRU演演算法是把命中行的計數器清零,其他各行計數器加1。當需要替換時淘汰行計數器計數值最大的數據行出局。這是一種高效、科學的演演算法,其計數器清零過程可以把一些頻繁調用后再不需要的數據淘汰出Cache,提高Cache的利用率。
Cache的替換演演算法對命中率的影響。當新的主存塊需要調入Cache並且它的可用空間位置又被佔滿時,需要替換掉Cache的數據,這就產生了替換策略(演演算法)問題。根據程序局部性規律可知:程序在運行中,總是頻繁地使用那些最近被使用過的指令和數據。這就提供了替換策略的理論依據。替換演演算法目標就是使Cache獲得最高的命中率。Cache替換演演算法是影響代理緩存系統性能的一個重要因素,一個好的Cache替換演演算法可以產生較高的命中率。常用演演算法如下:
(1)隨機法(RAND法)隨機替換演演算法就是用隨機數發生器產生一個要替換的塊號,將該塊替換出去,此演演算法簡單、易於實現,而且它不考慮Cache塊過去、現在及將來的使用情況,但是沒有利用上層存儲器使用的“歷史信息”、沒有根據訪存的局部性原理,故不能提高Cache的命中率,命中率較低。
(2)先進先出法(FIFO法)先進先出(First-In-First-Out,FIFO)演演算法。就是將最先進入Cache的信息塊替換出去。FIFO演演算法按調入Cache的先後決定淘汰的順序,選擇最早調入Cache的字塊進行替換,它不需要記錄各字塊的使用情況,比較容易實現,系統開銷小,其缺點是可能會把一些需要經常使用的程序塊(如循環程序)也作為最早進入Cache的塊替換掉,而且沒有根據訪存的局部性原理,故不能提高Cache的命中率。因為最早調入的信息可能以後還要用到,或者經常要用到,如循環程序。此法簡單、方便,利用了主存的“歷史信息”,但並不能說最先進入的就不經常使用,其缺點是不能正確反映程序局部性原理,命中率不高,可能出現一種異常現象。
(3)近期最少使用法(LRU法)近期最少使用(Least Recently Used,LRU)演演算法。這種方法是將近期最少使用的Cache中的信息塊替換出去。該演演算法較先進先出演演算法要好一些。但此法也不能保證過去不常用將來也不常用。 LRU法是依據各塊使用的情況,總是選擇那個最近最少使用的塊被替換。這種方法雖然比較好地反映了程序局部性規律,但是這種替換方法需要隨時記錄Cache中各塊的使用情況,以便確定哪個塊是近期最少使用的塊。LRU演演算法相對合理,但實現起來比較複雜,系統開銷較大。通常需要對每一塊設置一個稱為計數器的硬體或軟體模塊,用以記錄其被使用的情況。

基本信息
- 中文名
- 高速緩衝存儲器
- 外文名
- Cache
- 所屬科目
- 計算機
- 所屬領域
- 硬體