FP-growth
FP-growth
FP-Growth演演算法是韓嘉煒等人在2000年提出的關聯分析演演算法,它採取如下分治策略:將提供頻繁項集的資料庫壓縮到一棵頻繁模式樹(FP-tree),但仍保留項集關聯信息。
在演演算法中使用了一種稱為頻繁模式樹(Frequent Pattern Tree)的數據結構。FP-tree是一種特殊的前綴樹,由頻繁項頭表和項前綴樹構成。FP-Growth演演算法基於以上的結構加快整個挖掘過程。
眾所周知,Apriori演演算法在產生頻繁模式完全集前需要對資料庫進行多次掃描,同時產生大量的候選頻繁集,這就使Apriori演演算法時間和空間複雜度較大。但是Apriori演演算法中有一個很重要的性質:頻繁項集的所有非空子集都必須也是頻繁的。但是Apriori演演算法在挖掘額長頻繁模式的時候性能往往低下,Jiawei Han提出了FP-Growth演演算法。
FP-Tree:將事務數據表中的各個事務數據項按照支持度排序后,把每個事務中的數據項按降序依次插入到一棵以 NULL為根結點的樹中,同時在每個結點處記錄該結點出現的支持度。
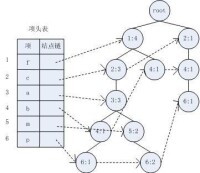
FP-Tree結構圖
條件樹:將條件模式基按照FP-Tree的構造原則形成的一個新的FP-Tree
基本思路:不斷地迭代FP-tree的構造和投影過程
演演算法描述如下:
1、對於每個頻繁項,構造它的條件投影資料庫和投影FP-tree。
2、對每個新構建的FP-tree重複這個過程,直到構造的新FP-tree為空,或者只包含一條路徑。
3、當構造的FP-tree為空時,其前綴即為頻繁模式;當只包含一條路徑時,通過枚舉所有可能組合併與此樹的前綴連接即可得到頻繁模式。
構造FP-Tree
挖掘頻繁模式前首先要構造FP-Tree,演演算法偽碼如下:
輸入:一個交易資料庫DB和一個最小支持度threshold.
輸出:它的FP-tree.
步驟:
1.掃描資料庫DB一遍。得到頻繁項的集合F和每個頻繁項的支持度。把F按支持度遞降排序,結果記為L.
根據L中的順序,選出並排序Trans中的事務項。把Trans中排好序的事務項列表記為[p|P],其中p是第一個元素,P是列表的剩餘部分。調用insert_tree([p|P],T).
函數insert_tree([p|P],T)的運行如下.
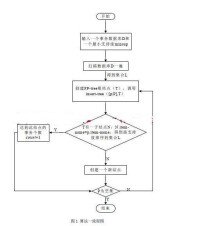
FP-Tree創建的演演算法流程圖
註:構造FP-Tree的演演算法理解上相對簡單,所以不過多描述
挖掘頻繁模式
對FP-Tree進行挖掘,演演算法如下:
輸入:一棵用演演算法一建立的樹Tree
輸出:所有的頻繁集
步驟:
調用FP-growth(Tree,null).
procedure FP-Growth ( Tree, x)
{
(1) if (Tree只包含單路徑P) then
(2) 對路徑P中節點的每個組合(記為B)
(3) 生成模式B並x,支持數=B中所有節點的最小支持度
(4) else 對Tree頭上的每個ai, do
{
(5) 生成模式B= ai 並 x,支持度=ai.support;
(6) 構造B的條件模式庫和B的條件FP樹TreeB;
(7) if TreeB != 空集
(8) then call FP-Growth ( TreeB , B )
}
}
下圖給出了整個演演算法的演示過程:
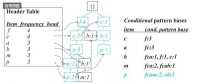
FP-Growth演演算法實例演示圖
基本信息
- 外文名
- FP-Growth
- 別名
- Frequent Pattern
- 類型
- 數據結構
- 基本思路
- 不斷地迭代FP-tree的構造和投影
- 好處
- 比Apriori演算法簡單