超啟髮式演演算法
超啟髮式演演算法
超啟髮式演演算法與已有的啟髮式演演算法既有一定的相似性,又有顯著的不同。通過分析超啟髮式演演算法與啟髮式演演算法的異同點,可以更加深入地理解超啟髮式演演算法。表2從多個視角,對超啟髮式演演算法與啟髮式演演算法進行了對比,從中我們可以發現以下現象:
超啟髮式演演算法
定義1. 超啟髮式演演算法提供了某種高層策略(High-Level Strategy,HLS),通過操縱或管理一組低層啟髮式演演算法(Low-Level Heuristics, LLH),以獲得新啟髮式演演算法。這些新啟髮式演演算法則被運用於求解各類NP-難解問題。
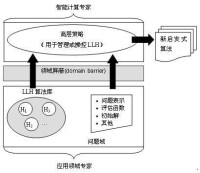
上圖給出了超啟髮式演演算法的概念模型示意圖。從圖中可以看出,超啟髮式演演算法分為兩個層面:在問題域層面上應用領域專家需根據本人的背景知識,提供問題的定義、評估函數等信息和一系列LLH;而在高層策略層面上,智能計算專家則通過設計高效的操縱管理機制,利用問題域所提供的問題特徵信息和LLH演演算法庫,構造新的啟髮式演演算法。因為這兩個層面之間實現了嚴格的領域屏蔽,僅僅需要修改問題域的問題定義和LLH、評估函數等領域有關信息,一種超啟髮式演演算法就可以被快速地遷移到新的問題上。因此,超啟髮式演演算法特別適合求解跨領域的問題。需要引起注意的是,研究超啟髮式演演算法的目標並不是取代智能計算專家,而是如何將智能計算技術更快地推廣到更多的應用領域,同時有效地降低啟髮式演演算法的設計難度,從而將領域專家和智能計算專家的研究重點有效地劃分開。根據圖1 可知,智能計算專家在超啟髮式演演算法設計中主要關注於高層策略,而領域專家則重點研究問題的目標函數和LLH等。
由於超啟髮式演演算法的研究尚處於起步階段,對於已有的各種超啟髮式演演算法,國際上尚未形成一致的分類方法。按照高層策略的機制不同,現有超啟髮式演演算法可以大致分為4類:基於隨機選擇、基於貪心策略、基於元啟髮式演演算法和基於學習的超啟髮式演演算法。
基於隨機選擇的超啟髮式演演算法
該類超啟髮式演演算法是從給定的集合中隨機選擇LLH,組合形成新的啟髮式演演算法。這類超啟髮式演演算法的特點是結構簡單、容易實現。同時,這類超啟髮式演演算法也經常被用作基準(benchmark),以評價其他類型的超啟髮式演演算法性能。該類超啟髮式演演算法可以進一步細分為純隨機(pure random)、帶延遲接受條件的隨機(random with late acceptance)等。
基於貪心(greedy)策略的超啟髮式演演算法
該類超啟髮式演演算法在構造新啟髮式演演算法時,每次都挑選那些能夠最大化改進當前(問題實例)解的LLH。由於每次挑選LLH時需要評估所有LLH,故此該類方法的執行效率低於基於隨機選擇的超啟髮式演演算法。
基於元啟髮式演演算法的超啟髮式演演算法
該類超啟髮式演演算法採用現有的元啟髮式演演算法(作為高層策略)來選擇LLH。由於元啟髮式演演算法研究相對充分,因此這類超啟髮式演演算法的研究成果相對較多。根據所採用的元啟髮式演演算法,該類超啟髮式演演算法可以細分為基於禁忌搜索、基於遺傳演演算法、基於遺傳編程、基於蟻群演演算法和基於GRASP with path-relinking等。
基於學習的超啟髮式演演算法
該類超啟髮式演演算法在構造新啟髮式演演算法時,採用一定學習機制,根據現有各種LLH的歷史信息來決定採納哪一個LLH。根據LLH歷史信息來源的不同,該類超啟髮式演演算法可以進一步分為在線學習(on-line learning)和離線學習(off-line learning)兩種:前者是指LLH的歷史信息是在求解當前實例過程中積累下來的;後者通常將實例集合分為訓練實例和待求解實例兩部分,訓練實例主要用於積累LLH的歷史信息,而待求解實例則可以根據這些歷史信息來決定LLH的取捨
(1)超啟髮式演演算法與啟髮式演演算法均是為了求解問題實例而提出的。因此,問題實例可以視為超啟髮式演演算法和啟髮式演演算法兩者共同的處理對象。
(2)超啟髮式演演算法與啟髮式演演算法都可能包含有參數。在傳統的啟髮式演演算法中,可能有大量的參數需要調製。比如遺傳演演算法中的種群規模、交叉率、變異率、迭代次數等。而超啟髮式演演算法的參數來源有兩個層面,在LLH和高層啟髮式方法中均可能有參數需要調製。
(3)超啟髮式演演算法與啟髮式演演算法都是運行在搜索空間上,但是各自的搜索空間構成不同:傳統啟髮式演演算法是工作在由問題實例的解構成的搜索空間上;而超啟髮式演演算法運行在一個由啟髮式演演算法構成的搜索空間上,該搜索空間上的每一個頂點代表一系列LLH的組合。因此,超啟髮式演演算法的抽象程度高於傳統啟髮式演演算法。
(4)超啟髮式演演算法與啟髮式演演算法均可以應用到各種不同的領域,但是它們各自對於問題領域知識的需求是不同的。啟髮式演演算法設計通常需要依賴於問題的特徵;而超啟髮式演演算法的高層啟髮式方法部分則幾乎不依賴於問題的領域知識,LLH則是與問題的領域知識緊密相關的。目前啟髮式演演算法的應用已經十分廣泛,而超啟髮式演演算法由於歷史較短,還主要局限在部分常見的組合優化問題上。
超啟髮式演演算法與啟髮式演演算法多視角對比
| 啟髮式演演算法 | 超啟髮式演演算法 | |
| 處理對象 | 問題實例 | 問題實例 |
| 參數 | 可能有 | 可能有 |
| 搜索空間 | 由實例的解構成 | 由LLH串(啟髮式演演算法)構成 |
| 應用領域 | 廣泛 | 有待拓展 |