共找到2條詞條名為堆棧的結果 展開
- 一個特定的存儲區或寄存器
- 先入后出隊列
堆棧
一個特定的存儲區或寄存器
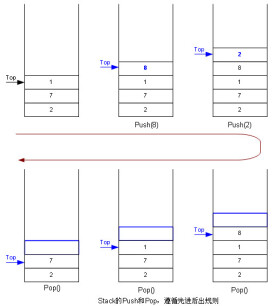
在計算機領域,堆棧是一個不容忽視的概念,堆棧是一種數據結構。堆棧都是一種數據項按序排列的數據結構,只能在一端(稱為棧頂(top))對數據項進行插入和刪除。在單片機應用中,堆棧是個特殊的存儲區,主要功能是暫時存放數據和地址,通常用來保護斷點和現場。要點對比:指令隊列,先進先出(FIFO—firstinfirstout)。
堆棧,先進後出(FILO—First-In/Last-Out)。
堆棧是一個特定的存儲區或寄存器,它的一端是固定的,另一端是浮動的。對這個存儲區存入的數據,是一種特殊的數據結構。所有的數據存入或取出,只能在浮動的一端(稱棧頂)進行,嚴格按照“後進先出”的原則存取,位於其中間的元素,必須在其棧上部(後進棧者)諸元素逐個移出后才能取出。在內存儲器(隨機存儲器)中開闢一個區域作為堆棧,叫軟體堆棧;用寄存器構成的堆棧,叫硬體堆棧。
單片機應用中,堆棧是個特殊存儲區,堆棧屬於RAM空間的一部分,堆棧用於函數調用、中斷切換時保存和恢復現場數據。堆棧中的物體具有一個特性:第一個放入堆棧中的物體總是被最後拿出來,這個特性通常稱為先進後出(FILO—First-In/Last-Out)。堆棧中定義了一些操作,兩個最重要的是PUSH和POP。PUSH(入棧)操作:堆棧指針(SP)加1,然後在堆棧的頂部加入一個元素。POP(出棧)操作相反,出棧則先將SP所指示的內部ram單元中內容送入直接地址定址的單元中(目的位置),然後再將堆棧指針(SP)減1.。這兩種操作實現了數據項的插入和刪除。
堆棧是計算機科學領域重要的數據結構,它被用於多種數值計算領域。表達式求值是編譯程序中較為常見的操作,在算術表達式求值的過程中,需要使用堆棧來保存表達式的中間值和運算符,堆棧使得表達式的中間運算過程的結果訪問具有了一定的自動管理能力。大部分編譯型程序設計語言具有程序遞歸特性,遞歸能夠增強語言的表達能力和降低程序設計難度。遞歸程序的遞歸深度通常是不確定的,需要將子程序執行的返回地址保存到堆棧這種先進後出式的結構中,以保證子程序的返回地址的正確使用順序。函數式程序設計語言中,不同子函數的參數的種類和個數是不相同的,編譯器也是使用堆棧來存儲子程序的參數。
棧(操作系統):由操作系統自動分配釋放,存放函數的參數值,局部變數的值等。其操作方式類似於數據結構中的棧。
堆(操作系統):一般由程序員分配釋放,若程序員不釋放,程序結束時可能由OS回收,分配方式倒是類似於鏈表。
棧使用的是一級緩存,他們通常都是被調用時處於存儲空間中,調用完畢立即釋放。
堆則是存放在二級緩存中,生命周期由虛擬機的垃圾回收演演算法來決定(並不是一旦成為孤兒對象就能被回收)。所以調用這些對象的速度要相對來得低一些。
堆(數據結構):堆可以被看成是一棵樹,如:堆排序。
棧(數據結構):一種先進後出的數據結構。
例如:順序棧AStack的類定義
template
classAStack{
private:
intsize;//數組的規模
T*stackArray;//存放堆棧元素的數組
inttop;//棧頂所在數組元素的下標
public:
AStack(intMaxStackSize)//構造函數
{size=MaxStackSize;stackArray=newT[MaxStackSize];top=-1;}
~AStack(){delete[]stackArray;}//析構函數
boolPush(constT&item);//向棧頂壓入一個元素
boolPop(T&item);//從棧頂彈出一個元素
boolPeek(T&item)const;//存取棧頂元素
intIsEmpty(void)const{returntop==-1;}
//檢測棧是否為空
intIsFull(void)const{returntopsize-1;}
//檢測棧是否為滿
voidclear(void){top-1;}//清空棧
};
1.棧(stack)與堆(heap)都是Java用來在Ram中存放數據的地方。與C++不同,Java自動管理棧和堆,程序員不能直接地設置棧或堆。
2.棧的優勢是,存取速度比堆要快,僅次於直接位於CPU中的寄存器。但缺點是,存在棧中的數據大小與生存期必須是確定的,缺乏靈活性。另外,棧數據在多個線程或者多個棧之間是不可以共享的,但是在棧內部多個值相等的變數是可以指向一個地址的,詳見第3點。堆的優勢是可以動態地分配內存大小,生存期也不必事先告訴編譯器,Java的垃圾收集器會自動收走這些不再使用的數據。但缺點是,由於要在運行時動態分配內存,存取速度較慢。
3.Java中的數據類型有兩種。
一種是基本類型(primitivetypes),共有8種,即int,short,long,byte,float,double,boolean,char(注意,並沒有string的基本類型)。這種類型的定義是通過諸如inta=3;longb=255L;的形式來定義的,稱為自動變數。值得注意的是,自動變數存的是字面值,不是類的實例,即不是類的引用,這裡並沒有類的存在。如inta=3;這裡的a是一個指向int類型的引用,指向3這個字面值。這些字面值的數據,由於大小可知,生存期可知(這些字面值固定定義在某個程序塊裡面,程序塊退出后,欄位值就消失了),出於追求速度的原因,就存在於棧中。
另外,棧有一個很重要的特殊性,就是存在棧中的數據可以共享。假設我們同時定義:
int a=3;int b=3;
編譯器先處理inta=3;首先它會在棧中創建一個變數為a的內存空間,然後查找有沒有字面值為3的地址,沒找到,就開闢一個存放3這個字面值的地址,然後將a指向3的地址。接著處理intb=3;在創建完b的引用變數后,由於在棧中已經有3這個字面值,便將b直接指向3的地址。這樣,就出現了a與b同時均指向3的情況。
特別注意的是,這種字面值的引用與類對象的引用不同。假定兩個類對象的引用同時指向一個對象,如果一個對象引用變數修改了這個對象的內部狀態,那麼另一個對象引用變數也即刻反映出這個變化。相反,通過字面值的引用來修改其值,不會導致另一個指向此字面值的引用的值也跟著改變的情況。如上例,我們定義完a與b的值后,再令a=4;那麼,b不會等於4,還是等於3。在編譯器內部,遇到a=4;時,它就會重新搜索棧中是否有4的字面值,如果沒有,重新開闢地址存放4的值;如果已經有了,則直接將a指向這個地址。因此a值的改變不會影響到b的值。
另一種是包裝類數據,【如Integer,String,Double等將相應的基本數據類型包裝起來的類。這些類數據全部存在於【堆】中】,Java用new()語句來顯示地告訴編譯器,在運行時才根據需要動態創建,因此比較靈活,但缺點是要佔用更多的時間。4.String是一個特殊的包裝類數據。即可以用Stringstr=newString("abc");的形式來創建,也可以用Stringstr="abc";的形式來創建(作為對比,在JDK5.0之前,你從未見過Integeri=3;的表達式,因為類與字面值是不能通用的,除了String。而在JDK5.0中,這種表達式是可以的!因為編譯器在後台進行Integeri=newInteger(3)的轉換)。前者是規範的類的創建過程,即在Java中,一切都是對象,而對象是類的實例,全部通過new()的形式來創建。Java中的有些類,如DateFormat類,可以通過該類的getInstance()方法來返回一個新創建的類,似乎違反了此原則。其實不然。該類運用了單例模式來返回類的實例,只不過這個實例是在該類內部通過new()來創建的,而getInstance()向外部隱藏了此細節。那為什麼在Stringstr="abc";中,並沒有通過new()來創建實例,是不是違反了上述原則?其實沒有。
4.關於Stringstr="abc"的內部工作。Java內部將此語句轉化為以下幾個步驟:【Stringstr="abc",Stringstr不要連著】
(1)先定義一個名為str的對String類的對象引用變數:Stringstr;
(2)【在【棧】中查找有沒有存放值為"abc"的地址,如果沒有,則開闢一個存放字面值為"abc"的地址,接著創建一個新的String類的對象o,並將o的字元串值指向這個地址,而且在棧中這個地址旁邊記下這個引用的對象o。如果已經有了值為"abc"的地址,則查找對象o,並返回o的地址。】【上文說數據時存放在堆中,此文說數據存放在棧中】[因為此處不是通過new()創建的啊]
(3)將str指向對象o的地址。
值得注意的是,一般String類中字元串值都是直接存值的。但像Stringstr="abc";這種場合下,其字元串值卻是保存了一個指向存在棧中數據的引用!
為了更好地說明這個問題,我們可以通過以下的幾個代碼進行驗證。
複製內容到剪貼板代碼:
String str1="abc";String str2="abc";System.out.println(str1==str2);//true
注意,我們這裡並不用str1.equals(str2);的方式,因為這將比較兩個字元串的值是否相等。==號,根據JDK的說明,只有在兩個引用都指向了同一個對象時才返回真值。而我們在這裡要看的是,str1與str2是否都指向了同一個對象。
結果說明,JVM創建了兩個引用str1和str2,但只創建了一個對象,而且兩個引用都指向了這個對象。
我們再來更進一步,將以上代碼改成:
複製內容到剪貼板代碼:
String str1="abc";String str2="abc";str1="bcd";System.out.println(str1+","+str2);//bcd,abcSystem.out.println(str1==str2);//false
這就是說,賦值的變化導致了類對象引用的變化,str1指向了另外一個新對象!而str2仍舊指向原來的對象。上例中,當我們將str1的值改為"bcd"時,JVM發現在棧中沒有存放該值的地址,便開闢了這個地址,並創建了一個新的對象,其字元串的值指向這個地址。
事實上,String類被設計成為不可改變(immutable)的類。如果你要改變其值,可以,但JVM在運行時根據新值悄悄創建了一個新對象,然後將這個對象的地址返回給原來類的引用。這個創建過程雖說是完全自動進行的,但它畢竟佔用了更多的時間。在對時間要求比較敏感的環境中,會帶有一定的不良影響。
再修改原來代碼:
複製內容到剪貼板代碼:
String str1="abc";String str2="abc";str1="bcd";String str3=str1;System.out.println(str3);//bcdString str4="bcd";System.out.println(str1==str4);//true
我們再接著看以下的代碼。
複製內容到剪貼板代碼:
Stringstr1=newString("abc");
Stringstr2="abc";
System.out.println(str1==str2);//false
Stringstr1="abc";
Stringstr2=newString("abc");
System.out.println(str1==str2);//false
創建了兩個引用。創建了兩個對象。兩個引用分別指向不同的兩個對象。
以上兩段代碼說明,只要是用new()來新建對象的,都會在堆中創建,而且其字元串是單獨存值的,即使與棧中的數據相同,也不會與棧中的數據共享。
5.數據類型包裝類的值不可修改。不僅僅是String類的值不可修改,所有的數據類型包裝類都不能更改其內部的值。
6.結論與建議:
(1)我們在使用諸如Stringstr="abc";的格式定義類時,總是想當然地認為,我們創建了String類的對象str。擔心陷阱!對象可能並沒有被創建。可以肯定的是,指向String類的引用被創建了。至於這個引用到底是否指向了一個新的對象,必須根據上下文來考慮,除非你通過new()方法來顯要地創建一個新的對象。因此,更為準確的說法是,我們創建了一個指向String類的對象的引用變數str,這個對象引用變數指向了某個值為"abc"的String類。清醒地認識到這一點對排除程序中難以發現的bug是很有幫助的。
(2)使用Stringstr="abc";的方式,可以在一定程度上提高程序的運行速度,因為JVM會自動根據棧中數據的實際情況來決定是否有必要創建新對象。而對於Stringstr=newString("abc");的代碼,則一概在堆中創建新對象,而不管其字元串值是否相等,是否有必要創建新對象,從而加重了程序的負擔。這個思想應該是享元模式的思想,但JDK的內部在這裡實現是否應用了這個模式,不得而知。
(3)當比較包裝類裡面的數值是否相等時,用equals()方法;當測試兩個包裝類的引用是否指向同一個對象時,用==。
(4)由於String類的immutable性質,當String變數需要經常變換其值時,應該考慮使用StringBuffer類,以提高程序效率
一個由C/C++編譯的程序佔用的內存分為以下幾個部分
1、棧區(stack)—由編譯器自動分配釋放,存放函數的參數名,局部變數的名等。其操作方式類似於數據結構中的棧。
2、堆區(heap)—由程序員分配釋放,若程序員不釋放,程序結束時可能由OS回收。注意它與數據結構中的堆是兩回事,分配方式倒是類似於鏈表。
3、靜態區(static)—全局變數和局部靜態變數的存儲是放在一塊的。程序結束後由系統釋放。
4、文字常量區—常量字元串就是放在這裡的,程序結束後由系統釋放。
5、程序代碼區—存放函數體的二進位代碼。
變數的存儲方式
| 存儲描述 | 持續性 | 作用域 | 鏈接性 | 如何聲明 |
| 自動 | 自動 | 代碼塊 | 無 | 在代碼塊中 |
| 寄存器 | 自動 | 代碼塊 | 無 | 在代碼塊中,使用關鍵字register |
| 靜態,無鏈接性 | 靜態 | 代碼塊 | 無 | 在代碼塊中,使用關鍵字static |
| 靜態,外部鏈接性 | 靜態 | 文件 | 外部 | 不在任何函數內 |
| 靜態,內部鏈接性 | 靜態 | 文件 | 內部 | 不在任何函數內,使用關鍵字static |
首先,定義靜態變數時如果沒有初始化編譯器會自動初始化為0.。接下來,如果是使用常量表達式初始化了變數,則編譯器僅根據文件內容(包括被包含的頭文件)就可以計算表達式,編譯器將執行常量表達式初始化。必要時,編譯器將執行簡單計算。如果沒有足夠的信息,變數將被動態初始化。請看一下代碼:
int global_1=1000;//靜態變數外部鏈接性常量表達式初始化int global_2;//靜態變數外部鏈接性零初始化static int one_file_1=1000;//靜態變數內部鏈接性常量表達式初始化static int one_file_2;//靜態變數內部鏈接性零初始化int main(){static int count_1=1000;//靜態變數無鏈接性常量表達式初始化static int count_2;//靜態變數無鏈接性零初始化return 0;}
所有的靜態持續變數都有下述初始化特徵:未被初始化的靜態變數的所有位都被設為0。這種變數被稱為零初始化。以上代碼說明關鍵字static的兩種用法,但含義有些不同:用於局部聲明,以指出變數是無鏈接性的靜態變數時,static表示的是存儲持續性;而用於代碼塊外聲明時,static表示內部鏈接性,而變數已經是靜態持續性了。有人稱之為關鍵字重載,即關鍵字的含義取決於上下文。
stack:
由系統自動分配。例如,聲明在函數中一個局部變數intb;系統自動在棧中為b開闢空間。
heap:
需要程序員自己申請,並指明大小,在c中malloc函數
如p1=(char*)malloc(10);
在C++中用new運算符
如p2=newchar[10];//(char*)malloc(10);
但是注意p1、p2本身是在棧中的。
棧:只要棧的剩餘空間大於所申請空間,系統將為程序提供內存,否則將報異常提示棧溢出。
堆:首先應該知道操作系統有一個記錄空閑內存地址的鏈表,當系統收到程序的申請時,會遍歷該鏈表,尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閑結點鏈表中刪除,並將該結點的空間分配給程序,另外,對於大多數系統,會在這塊內存空間中的首地址處記錄本次分配的大小,這樣,代碼中的delete語句才能正確的釋放本內存空間。另外,由於找到的堆結點的大小不一定正好等於申請的大小,系統會自動的將多餘的那部分重新放入空閑鏈表中。
棧:在Windows下,棧是向低地址擴展的數據結構,是一塊連續的內存的區域。這句話的意思是棧頂的地址和棧的最大容量是系統預先規定好的,在WINDOWS下,棧的大小是2M(也有的說是1M,總之是一個編譯時就確定的常數),如果申請的空間超過棧的剩餘空間時,將提示overflow。因此,能從棧獲得的空間較小。
堆:堆是向高地址擴展的數據結構,是不連續的內存區域。這是由於系統是用鏈表來存儲的空閑內存地址的,自然是不連續的,而鏈表的遍歷方向是由低地址向高地址。堆的大小受限於計算機系統中有效的虛擬內存。由此可見,堆獲得的空間比較靈活,也比較大。
棧由系統自動分配,速度較快。但程序員是無法控制的。
堆是由new分配的內存,一般速度比較慢,而且容易產生內存碎片,不過用起來最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配內存,他不是在堆,也不是在棧,而是直接在進程的地址空間中保留一塊內存,雖然用起來最不方便。但是速度快,也最靈活
棧:在函數調用時,在大多數的C編譯器中,參數是由右往左入棧的,然後是函數中的局部變數。注意靜態變數是不入棧的。
當本次函數調用結束后,局部變數先出棧,然後是參數,最後棧頂指針指向函數的返回地址,也就是主函數中的下一條指令的地址,程序由該點繼續運行。
堆:一般是在堆的頭部用一個位元組存放堆的大小。堆中的具體內容由程序員安排。
chars1[]="aaaaaaaaaaaaaaa";
char*s2="bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在運行時刻賦值的;
而bbbbbbbbbbb是在編譯時就確定的;
但是,在以後的存取中,在棧上的數組比指針所指向的字元串(例如堆)快。
比如:
#includevoid main(){char a = 1;char c[] = "1234567890";char *p ="1234567890";a = c[1];a = p[1];return;}
對應的彙編代碼
10:a=c[1];
004010678A4DF1movcl,byteptr[ebp-0Fh]
0040106A884DFCmovbyteptr[ebp-4],cl
11:a=p[1];
0040106D8B55ECmovedx,dwordptr[ebp-14h]
004010708A4201moval,byteptr[edx+1]
004010738845FCmovbyteptr[ebp-4],al
第一種在讀取時直接就把字元串中的元素讀到寄存器cl中,而第二種則要先把指針值讀到edx中,再根據edx讀取字元,顯然慢了。
堆和棧的區別可以用如下的比喻來看出:
使用棧就象我們去飯館里吃飯,只管點菜(發出申請)、付錢、和吃(使用),吃飽了就走,不必理會切菜、洗菜等準備工作和洗碗、刷鍋等掃尾工作,他的好處是快捷,但是自由度小。
使用堆就象是自己動手做喜歡吃的菜肴,比較麻煩,但是比較符合自己的口味,而且自由度大。
堆棧處理器是由堆棧式程序設計語言Forth演化而來的一種處理器,它繼承了Forth語言的雙堆棧結構和堆棧操作原語。Forth定義了堆棧處理器的主要體系結構狀態和指令集風格。Forth語言定義了兩個下推式堆棧,它們提供了Forth原語操作所需的源數據、目的數據和程序控制數據,它們是數據棧和返回棧。兩個棧在結構上完全相同,但它們的用途卻大不相同。數據棧指出了算術邏輯運算的源操作數和目標操作數、子程序調用的參數和主調程序的數據現場。返回棧具有輔助堆棧和保存子程序調用的返回地址的功能。
堆棧處理器的指令可以分為四類:算術邏輯運算、堆棧調整、程序分支和存儲器訪問。堆棧指令集與常見的RISC處理器指令集的不同是指令的定址方式,堆棧指令多為默認定址方式,指令操作數的地址被處理器設定為某一個既定的堆棧位置,不需要將地址信息存放於指令中。這種方式增加了堆棧處理器的指令壓縮度,但固定的操作數地址會使得指令的操作數指定不夠靈活,堆棧處理器中設計了能夠調整堆棧中數據存放順序的堆棧調整指令。堆棧調整指令可以在同一堆棧內部和堆棧間調整數據的位置,堆棧調整指令和堆棧的先進後出特性使得堆棧中特定位置的數據可以靈活地改變。
堆棧處理器也是基於簡單性哲學的處理器,但是它更加深入的踐行了簡單性哲學。首先堆棧處理器的具有更簡短的指令格式,一個指令字可以包含的指令條數更多,指令更加緊湊。堆棧指令的操作數大部分是採用默認定址,如:算術運算的操作數為數據堆棧的棧頂和次棧頂,操作數無需直接指定。省略了操作數信息,堆棧指令長度可以變得非常短。其次,堆棧處理器的每一條指令所完成的功能都非常簡單,這使得它的每一條指令都可以在一個機器周期內完成。對於較複雜的功能,堆棧處理器將它分解為多個簡單操作指令來完成,這使得堆棧處理器可以在不使用流水線技術的情況下,依然可以有很高的指令吞吐率。再次,緊湊的指令結構使得堆棧處理器無需使用緩衝技術來緩解處理器與存儲器在速度上的差異。堆棧處理器的指令長度都很短,一個機器字中通常可以存儲兩到三條指令,所以處理器一次可以同時取出多條指令,每執行兩到三條指令才進行一次取指令操作,這就允許堆棧處理器的速度是存儲器的數倍,而不會產生等待訪存的情形。最後,堆棧處理器內置的硬體堆棧和優異的堆棧操作性能使得它具有了快速的子程序調用和返回能力。堆棧處理器的指令操作都是基於堆棧的,它進行子程序調用時,只需要保存子程序的返回地址,不需要進行數據現場保護,因為程序的數據現場就天然地存儲在數據堆棧中。堆棧處理器中的堆棧除了進行程序現場保護和數值運算,它還可被用來存放子程序參數和返回值,堆棧存放參數和返回值的好處是它能適應程序參數和返回值個數的變化。
基本信息
- 中文名
- 堆棧
- 外文名
- Stack
- 特點
- 先進後出
- 學科
- 計算機
- 應用
- 內存分配
- 定義
- 一種數據項按序排列的數據結構