共找到12條詞條名為DOM的結果 展開
DOM
文檔對象模型(Document Object Model)
徠文檔對象模型(Document Object Model,簡稱DOM),是W3C組織推薦的處理可擴展標誌語言的標準編程介面。在網頁上,組織頁面(或文檔)的對象被組織在一個樹形結構中,用來表示文檔中對象的標準模型就稱為DOM。
DOM
DOM實際上是以面向對象方式描述的文檔模型。DOM定義了表示和修改文檔所需的對象、這些對象的行為和屬性以及這些對象之間的關係。可以把DOM認為是頁面上數據和結構的一個樹形表示,不過頁面當然可能並不是以這種樹的方式具體實現。
通過 JavaScript,您可以重構整個 HTML 文檔。您可以添加、移除、改變或重排頁面上的項目。
要改變頁面的某個東西,JavaScript 就需要獲得對 HTML 文檔中所有元素進行訪問的入口。這個入口,連同對 HTML 元素進行添加、移動、改變或移除的方法和屬性,都是通過文檔對象模型來獲得的(DOM)。
在 1998 年,W3C 發布了第一級的 DOM 規範。這個規範允許訪問和操作 HTML 頁面中的每一個單獨的元素。
所有的瀏覽器都執行了這個標準,因此,DOM 的兼容性問題也難覓蹤影了。
DOM 可被 JavaScript 用來讀取、改變 HTML、XHTML 以及 XML 文檔。
DOM 被分為不同的部分(核心、XML及HTML)和級別(DOM Level 1/2/3):
DOM 是遵循 W3C(萬維網聯盟)的標準。
DOM 定義了訪問 HTML 和 XML 文檔的標準:
"W3C 文檔對象模型(DOM)是中立於平台和語言的介面,它允許程序和腳本動態地訪問和更新文檔的內容、結構和樣式。"
W3C DOM 標準被分為 3 個不同的部分:
• 核心 DOM - 針對任何結構化文檔的標準模型
• XML DOM - 針對 XML 文檔的標準模型
• HTML DOM - 針對 HTML 文檔的標準模型
XML DOM 是:
• 用於 XML 的標準對象模型
• 用於 XML 的標準編程介面
• 中立於平台和語言
• W3C 標準
XML DOM 定義了所有 XML 元素的 對象和屬性,以及訪問它們的 方法(介面)。
換句話說: XML DOM 是用於獲取、更改、添加或刪除 XML 元素的標準。
HTML DOM 是:
• HTML 的標準對象模型
• HTML 的標準編程介面
• W3C 標準
HTML DOM 定義了所有 HTML 元素的對象和屬性,以及訪問它們的方法(介面)。
換言之,HTML DOM 是關於如何獲取、修改、添加或刪除 HTML 元素的標準。
根據W3C DOM規範,DOM是HTML與XML的應用編程介面(API),DOM將整個頁面映射為一個由層次節點組成的文件。有1級、2級、3級共3個級別。
1級DOM在1998年10月份成為W3C的提議,由DOM核心與DOM HTML兩個模塊組成。DOM核心能映射以XML為基礎的文檔結構,允許獲取和操作文檔的任意部分。DOM HTML通過添加HTML專用的對象與函數對DOM核心進行了擴展。
DOM
2級DOM引進了幾個新DOM模塊來處理新的介面類型:
DOM視圖:描述跟蹤一個文檔的各種視圖(使用CSS樣式設計文檔前後)的介面;
DOM事件:描述事件介面;
DOM樣式:描述處理基於CSS樣式的介面;
DOM遍歷與範圍:描述遍歷和操作文檔樹的介面;
3級DOM通過引入統一方式載入和保存文檔和文檔驗證方法對DOM進行進一步擴展,DOM3包含一個名為“DOM載入與保存”的新模塊,DOM核心擴展后可支持XML1.0的所有內容,包括XML Infoset、 XPath、和XML Base。
當閱讀與DOM有關的材料時,可能會遇到參考0級DOM的情況。需要注意的是並沒有標準被稱為0級DOM,它僅是DOM歷史上一個參考點(0級DOM被認為是在Internet Explorer 4.0 與Netscape Navigator4.0支持的最早的DHTML)。
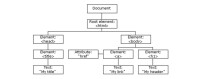
根據 DOM,HTML 文檔中的每個成分都是一個節點。
DOM 是這樣規定的:
整個文檔是一個文檔節點
每個 HTML 標籤是一個元素節點
包徠含在 HTML 元素中的文本是文本節點
每一個 HTML 屬性是一個屬性節點
註釋屬於註釋節點
節點彼此都有等級關係。
HTML 文檔中的所有節點組成了一個文檔樹(或節點樹)。HTML 文檔中的每個元素、屬性、文本等都代表著樹中的一個節點。樹起始於文檔節點,並由此繼續伸出枝條,直到處於這棵樹最低級別的所有文本節點為止。
下面這個圖片表示一個文檔樹(節點樹):
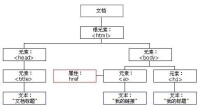
節點樹示意圖
請看下面這個HTML文檔:
DOM Lesson one
Hello world!
上面所有的節點彼此間都存在關係。
除文檔節點之外的每個節點都有父節點。舉例, 和 的父節點是 節點,文本節點 "Hello world!" 的父節點是
節點。
大部分元素節點都有子節點。比方說, 節點有一個子節點: 節點。<title> 節點也有一個子節點:文本節點 "DOM Tutorial"。</div><div class="cp">當節點分享同一個父節點時,它們就是同輩(同級節點)。比方說,<h1> 和 <div class="cp">是同輩,因為它們的父節點均是 <body> 節點。</div><div class="cp">節點也可以擁有後代,後代指某個節點的所有子節點,或者這些子節點的子節點,以此類推。比方說,所有的文本節點都是 <html>節點的後代,而第一個文本節點是 <head> 節點的後代。</div><div class="cp">節點也可以擁有先輩。先輩是某個節點的父節點,或者父節點的父節點,以此類推。比方說,所有的文本節點都可把 <html> 節點作為先輩節點。</div><div class="catlog-title is-1"><h3>訪問節點</h3><a id="catalog_3" class="title-anchor"></a></div><hr class="border-1"><div class="cp">你可通過若干種方法來查找您希望操作的元素:</div><div class="cp">通過使用 getElementById() 和 getElementsByTagName() 方法</div><div class="cp">通過使用一個元素節點的 parentNode、firstChild 以及 lastChild 屬性</div><div class="cp">getElementById() 和 getElementsByTagName() 這兩種方法,可查找整個 HTML 文檔中的任何 HTML 元素。</div><div class="cp">這兩種方法會忽略文檔的結構。假如您希望查找文檔中所有的 <div class="cp"> 元素,getElementsByTagName() 會把它們全部找到,不管 <div class="cp"> 元素處於文檔中的哪個層次。同時,getElementById() 方法也會返回正確的元素,不論它被隱藏在文檔結構中的什麼位置。</div><div class="cp">這兩種方法會向您提供任何你所需要的 HTML 元素,不論它們在文檔中所處的位置!</div><div class="cp">getElementById() 可通過指定的 ID 來返回元素:</div><div class="cp">getElementById() 語法</div><div class="cp">document.getElementById("ID");註釋:getElementById() 無法工作在 XML 中。在 XML 文檔中,您必須通過擁有類型 id 的屬性來進行搜索,而此類型必須在 XML DTD 中進行聲明。</div><div class="cp">getElementsByTagName() 方法會使用指定的標籤名返回所有的元素(作為一個節點列表),這些元素是您在使用此方法時所處的元素的後代。</div><div class="cp">getElementsByTagName() 可被用於任何的 HTML 元素:</div><div class="cp">getElementsByTagName() 語法</div><div class="cp">document.getElementsByTagName("標籤名稱");或者:</div><div class="cp">document.getElementById('ID').getElementsByTagName("標籤名稱");</div><div class="catlog-title is-2"><h4>實例 1</h4><a id="catalog_3_1" class="title-anchor"></a></div><div class="cp">下面這個例子會返迴文檔中所有 <div class="cp"> 元素的一個節點列表:</div><div class="cp">document.getElementsByTagName("p");</div><div class="catlog-title is-2"><h4>實例 2</h4><a id="catalog_3_2" class="title-anchor"></a></div><div class="cp">下面這個例子會返回所有 <div class="cp"> 元素的一個節點列表,且這些 <div class="cp"> 元素必須是 id 為 "maindiv" 的元素的後代:</div><div class="cp">document.getElementById('maindiv').getElementsByTagName("p");</div><div class="catlog-title is-2"><h4>節點列表</h4><a id="catalog_3_3" class="title-anchor"></a></div><div class="cp">當我們使用節點列表時,通常要把此列表保存在一個變數中,就像這樣:</div><div class="cp">var x=document.getElementsByTagName("p");現在,變數 x 包含著頁面中所有 <div class="cp"> 元素的一個列表,並且我們可以通過它們的索引號來訪問這些 <div class="cp"> 元素。</div><div class="cp">註釋:索引號從 0 開始。</div><div class="cp">您可以通過使用 length 屬性來循環遍歷節點列表:</div><div class="cp">var x=document.getElementsByTagName("p"); for (var i=0;i<x.length;i++) { // do something with each paragraph }您也可以通過索引號來訪問某個具體的元素。</div><div class="cp">要訪問第三個 <div class="cp"> 元素,您可以這麼寫:</div><div class="cp">var y=x[2];</div><div class="cp">parentNode、firstChild以及lastChild</div><div class="cp">這三個屬性 parentNode、firstChild 以及 lastChild 可遵循文檔的結構,在文檔中進行“短距離的旅行”。</div><div class="cp">請看下面這個 HTML 片段:</div><div class="cp"><div class="table-container"><table class="table is-bordered is-striped is-fullwidth"></div><div class="cp"><tr></div><div class="cp"><td>John</td></div><div class="cp"><td>Doe</td></div><div class="cp"><td>Alaska</td></div><div class="cp"></tr></div><div class="cp"></table></div></div><div class="cp">在上面的HTML代碼中,第一個 <td> 是 <tr> 元素的首個子元素(firstChild),而最後一個 <td> 是 <tr>元素的最後一個子元素(lastChild)。</div><div class="cp">此外,<tr> 是每個 <td>元 素的父節點(parentNode)。</div><div class="cp">對 firstChild 最普遍的用法是訪問某個元素的文本:</div><div class="cp">var x=[a paragraph]; var text=x.firstChild.nodeValue;parentNode 屬性常被用來改變文檔的結構。假設您希望從文檔中刪除帶有 id 為 "maindiv" 的節點:</div><div class="cp">var x=document.getElementById("maindiv"); x.parentNode.removeChild(x);首先,您需要找到帶有指定 id 的節點,然後移至其父節點並執行 removeChild() 方法。</div><div class="catlog-title is-1"><h3>優點和缺點</h3><a id="catalog_4" class="title-anchor"></a></div><hr class="border-1"><div class="cp">DOM的優勢主要表現在:易用性強,使用DOM時,將把所有的XML文檔信息都存於內存中,並且遍歷簡單,支持XPath,增強了易用性。</div><div class="cp">DOM的缺點主要表現在:效率低,解析速度慢,內存佔用量過高,對於大文件來說幾乎不可能使用。另外效率低還表現在大量的消耗時間,因為使用DOM進行解析時,將為文檔的每個element、attribute、processing-instruction和comment都創建一個對象,這樣在DOM機制中所運用的大量對象的創建和銷毀無疑會影響其效率。</div><div class="catlog-title is-1"><h3>模型及擴展</h3><a id="catalog_5" class="title-anchor"></a></div><hr class="border-1"><div class="cp">文檔對象模型DOM</div><div class="cp">DOM即文檔對象模型,是W3C制定的標準介面規範,是一種處理HTML和XML文件的標準API。DOM提供了對整個文檔的訪問模型,將文檔作為一個樹形結構,樹的每個結點表示了一個HTML標籤或標籤內的文本項。DOM樹結構精確地描述了HTML文檔中標籤間的相互關聯性。將HTML或XML文檔轉化為DOM樹的過程稱為解析(parse)。HTML文檔被解析后,轉化為DOM樹,因此對HTML文檔的處理可以通過對DOM樹的操作實現。DOM模型不僅描述了文檔的結構,還定義了結點對象的行為,利用對象的方法和屬性,可以方便地訪問、修改、添加和刪除DOM樹的結點和內容。</div><div class="cp">DOM樹擴展</div><div class="cp">根據W3C的定義,DOM樹結點的屬性包括標記名(nodeName)、結點類型(node Type,取值為TagTxt)、結點內容(data)、父結點對象集合(parent Node)、子結點對象集合(firstChild,lastChild)、兄弟結點對象集合(previous Sibling,nextSibling)等。DOM樹結點的這些屬性給出了頁面的基本內容和結構信息,但不能反映標籤、屬性以及內容等與主題的相關程度,因而缺乏主題提取所需的語義。對DOM樹擴展的總體思路為:考慮HTML頁面標籤的類別,以及標籤屬性值對頁面主題信息的影響,將這種影響納入對頁面內容要素的計算中,對DOM樹結點進行語義擴展,同時引入結點影響度因子來刻畫該結點在樹中的重要程度。</div><div class="cp">DOM樹結點語義擴展</div><div class="cp">為了增加DOM樹結點與頁面主題信息相關程度的語義信息,計算結點內容的重要度,將<a target="_blank" href="/wiki/qg2xlq5rmkqvz05.html" title="HTML標籤">HTML標籤</a>的類別(Category)、非鏈接文字數(WordNum)、超鏈接數(LinkNum)、屬性集(Attibution)和影響度因子(Influence)等屬性添加到結點中,擴展其語義。HTML標籤依據其作用可分為5類:</div><div class="cp">● 描述標題及頁面概要信息的標籤:如〈title〉、〈meta〉等。</div><div class="cp">● 規劃網頁布局的標籤:如〈table〉、〈tr〉、〈td〉、〈p〉、〈div〉等,其作用是描述網頁內容的布局結構。</div><div class="cp">● 描述顯示特點的標籤:如〈b〉、〈I〉、〈strong〉、〈h1〉-〈h6〉等,其作用是強調重點內容,引起人們注意。</div><div class="cp">● 超鏈接相關的標籤,表示網頁間的內容相關性信息。</div><div class="cp">● 其他標籤,如設置圖像的標籤〈img〉,在文本提取時將忽略這類標籤。</div><div class="cp">根據HTML標籤在刻畫網頁特徵時的語義功能,將DOM樹結點分為6種類別:標題類(TITLE)、正文類(CONTENT)、視覺類(VISION)、分塊類(BLOCK)、超鏈類(LINK)和其他類(OTHER),不同類的結點對Web信息提取的重要度不同。</div><div class="cp">● 標題類(TITLE):指HTML文檔中標題標籤的專有類別。</div><div class="cp">● 正文類(CONTENT):指包含網頁正文內容的標籤類別,如包含文字的〈td〉標籤。</div><div class="cp">● 視覺類(VISION):指描述頁面顯示特性的標籤類別,如〈b〉、〈strong〉等。</div><div class="cp">● 分塊類(BLOCK):指用於網頁內容分塊的標籤類別,如〈table〉、〈tr〉等。</div><div class="cp">● 超鏈類(LINK):指包含超鏈接的標籤類別,如〈a〉。</div><div class="cp">● 其他類(OTHER):指不屬於以上5種類別的標籤類型。</div><div class="cp">以上6類結點對頁面主題的重要度依次降低。擴展后的DOM樹結點結構如圖1所示。</div><div class="cp">結點影響度因子</div><div class="cp">Web頁面的有效內容大多存在DOM樹的葉結點中,DOM樹中的其餘結點主要用於表示內容分塊及頁面的外觀特性。在已有的頁面信息提取方法中,對這些結點往往只考慮內容分塊作用,而忽略了視覺結點對頁面內容的影響。實際上,網頁設計者通常會利用顯示標籤以及標籤屬性強調重點內容,不妨稱其為強調標籤和標籤強調屬性,例如〈b〉標籤,或〈font〉標籤的size屬性。此外,不同類別結點對其子孫結點內容塊的影響也是不同的。例如,以標題類結點為祖先結點的內容塊,其重要程度應更高。為了評判DOM樹中結點對內容的影響程度,定義了結點影響度因子。</div><div class="cp">定義1(DOM樹結點影響度因子)表示結點對內容影響的相對程度,用Influence(node)表示,Influence(node) ∈[0,1]。該值越大,表明影響程度越高。</div><div class="cp">結點影響度因子的確定要綜合考慮結點類別和標籤強調屬性,其初值按TITLE,CONTENT,VISION,BLOCK,LINK,OTHER類別降序排列。可構造影響度因子初值向量Initvlale。同時結點影響度因子具有傳遞性,即某結點的影響度因子值應向其子結點傳遞。因此,葉結點的影響度因子可由下式計算:Influence(leaf) =∑ki=Influence(Ancestori)其中,Ancestori是葉結點的祖先結點,k為祖先結點數。</div><div class="catlog-title is-1"><h3>介面</h3><a id="catalog_6" class="title-anchor"></a></div><hr class="border-1"><div class="cp">主要的介面有:</div><div class="cp">● <a target="_blank" href="/wiki/j3q86zyogjn79x0.html" title="Node">Node</a>介面:它是文檔中節點的基類型。定義了基本的訪問和改變文檔結構的方法。</div><div class="cp">● <a target="_blank" href="/wiki/jev24ry3kmqjowz.html" title="Document">Document</a>介面:它代表整個文檔。可創建文檔中的各種節點(元素、註釋、處理指令等),創建的節點中帶有一個OwnerDoculnent屬性表示創建它們的Document對象。</div><div class="cp">● DocumentFragment介面:它代表文檔樹的子樹,相當一個小型文檔。</div><div class="cp">● Attr介面:它代表元素節點的屬性。有意思的是它並不認為是該元素節點的子節點,不構成DOM樹的一部分。同時也不是DocumentFragment節點的直接子節點。</div><div class="cp">● CharacterData介面:它維護了DOMsitrgn字元串並提供讀寫操作的介面。但不直接對應文檔的某種類型節點。</div><div class="cp">● Text介面:它從CharacterData繼承而來。代表元素或屬性的一段連續的文本內容。它有一個派生的介面CDATAsection,目的是:CDATASeciton節點的內容將不會作任何轉化;使用Node中的nomraliez方法時相鄰的Text節點會合併成一個節點,但使用CDATASeciton可避免合併。</div><div class="cp">● Comment介面:它也從CharacterData繼承而來。代表註釋中的文本內容。</div><div class="cp">● NodeList介面:用於管理有序的節點集。</div><div class="cp">● Entity介面:它代表實體;EntityReference代表實體的引用。</div><div class="cp">● NamedNodeMap介面:用於管理無序的節點集。</div><div class="cp">● DOMImplementation介面:它提供與DOM模型的實例無關的介面。CreateDocument可創建一個Document對象;haseFature可判斷DOM實現是否支持某一模塊。</div><div class="cp">● Notation介面:它代表文檔中的符號定義。</div><div class="cp">● ProcessingInstruction介面:它代表處理指令。</div><div class="cp">● DOMException介面:異常處理。由於程序中的邏輯錯誤、數據丟失或DOM實現本身不穩定引起的錯誤。在程序處理過程中,由方法返回一個錯誤值。介面之間的繼承關係可參看圖2。</div><div class="catlog-title is-1"><h3>特徵</h3><a id="catalog_7" class="title-anchor"></a></div><hr class="border-1"><div class="cp">Document Object Model的歷史可以追溯至1990年代後期微軟與Netscape的“瀏覽器大戰” (browser wars),雙方為了在JavaScript與JScript一決生死,於是大規模的賦予瀏覽器強大的功能。微軟在網頁技術上加入了不少專屬事物,計有VBScript、ActiveX、以及微軟自家的DHTML格式等,使不少網頁使用非微軟平台及瀏覽器無法正常顯示。DOM即是當時蘊釀出來的傑作。</div><div class="cp">DOM分為HTML DOM和XML DOM兩種。它們分別定義了訪問和操作HTML/XML文檔的標準方法,並將對應的文檔呈現為帶有元素、屬性和文本的樹結構(節點樹),如圖3所示: 1)DOM樹定義了HTML/XML文檔的邏輯結構,給出了一種應用程序訪問和處理XML文檔的方法。</div><div class="cp">2)在DOM樹中,有一個根節點,所有其他的節點都是根節點的後代。</div><div class="cp">3) 在應用過程中,基於DOM的HTML/XML分析器將一個HTML/XML文檔轉換成一棵DOM樹,應用程序通過對DOM樹的操作,來實現對HTML/XML文檔數據的操作。</div><div style="clear: both"></div></div></div></div><div class="column is-narrow is-full-touch"><div class="sidebar"><div class="summary-albums"><a class="image" target="_blank" rel="noopener noreferrer nofollow" href="/album/4mv5076rj59jm00/pics.html"><img src="https://i1.twwiki.net/cover/w275/m8/4/m849d6af43eaff338eec46451d88847c2.jpg"></a></div><div class="info-box"><div class="catlog-title is-2"><h4>基本信息</h4></div><div><dl><dt>中文名</dt><dd><div><span>文檔對象模型</span></div></dd></dl><dl><dt>外文名</dt><dd><div><span>Document Object Model</span></div></dd></dl><dl><dt>別名</dt><dd><div><span>DOM</span></div></dd></dl><dl><dt>應用</dt><dd><div><span>處理可擴展標誌語言</span></div></dd></dl><dl><dt>平台</dt><dd><div><span>Windows</span></div></dd></dl><dl><dt>發展</dt><dd><div><span>網頁應用</span></div></dd></dl></div></div></div></div></div><ul id="fixbar"><li class="gotop"><span class="icon is-large"><i class="iconf i-dingbu"></i></span></li><li class="dir"><span class="icon is-medium"><i class="iconf i-dir"></i></span><span class="bar-font">目錄</span></li></ul></div></div><footer class="py-5 footer"><div class="container has-text-centered"><a target="_blank" rel="nofollow" href="/site/privacy">隱私條款</a><span> | </span><a target="_blank" rel="nofollow" href="/site/contact">聯絡我們</a></div></footer><div class="modal" id="dir-modal"><div class="modal-background"></div><div class="modal-card"><header class="modal-card-head"><p class="modal-card-title">目錄</p><button class="delete" aria-label="close"></button></header><section class="modal-card-body"></section></div></div><script src="https://cdn.jsdelivr.net/npm/jquery@2.2.4/dist/jquery.min.js"></script><script src="https://i1.twwiki.net/js/com.min.js?v=12"></script><script async src="https://www.googletagmanager.com/gtag/js?id=G-PQB6P4TLQ5"></script><script> window.dataLayer = window.dataLayer || []; function gtag(){dataLayer.push(arguments);} gtag('js', new Date()); gtag('config', 'G-PQB6P4TLQ5');</script></body></html>