全文索引
全文索引
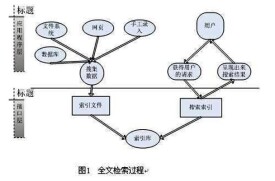
全文索引技術是目前搜索引擎的關鍵技術。
試想在1M大小的文件中搜索一個詞,可能需要幾秒,在100M的文件中可能需要幾十秒,如果在更大的文件中搜索那麼就需要更大的系統開銷,這樣的開銷是不現實的。
所以在這樣的矛盾下出現了全文索引技術,有時候有人叫倒排文檔技術。
原理是先定義一個詞庫,然後在文章中查找每個詞條(term)出現的頻率和位置,把這樣的頻率和位置信息按照詞庫的順序歸納,這樣就相當於對文件建立了一個以詞庫為目錄的索引,這樣查找某個詞的時候就能很快的定位到該詞出現的位置。
問題在處理英文文檔的時候顯然這樣的方式是非常好的,因為英文自然的被空格分成若干詞,只要我們有足夠大的辭彙庫就能很好的處理。但是亞洲文字因為沒有空格作為斷詞標誌,所以就很難判斷一個詞,而且人們使用的辭彙在不斷的變化,而維護一個可擴展的辭彙庫的成本是很高的,所以問題出現了。
解決出現這樣的問題使“分詞”成為全文索引的關鍵技術。目前有兩種基本的方法:
二元法 它把所有有可能的每兩兩漢字的組合看為一個片語,這樣就沒有維護詞庫的開銷。
詞庫法 它使使用詞庫中的詞作為切分的標準,這樣也出現了詞庫跟不上辭彙發展的問題,除非你維護詞庫。
實際上現在很多著名的搜索引擎都使用了多種分詞的辦法,比如“正向最大匹配”+“逆向最大匹配”,基於統計學的新詞識別,自動維護詞庫等技術,但是顯然這樣的技術還沒有做到完美。
目前全文索引技術正走向人工智慧化,也是發展的方向。
MicroSoft SqlServer 2000/2005 中的全文索引是由一系列存儲過程來完成的,這些存儲過程按先後順序羅列如下:
1、啟動資料庫的全文索引服務存儲過程:sp_fulltext_service
2、初始化全文索引存儲過程:sp_fulltext_database
3、建立全文索引目錄存儲過程:sp_fulltext_catalog
4、在全文索引目錄中添加刪除表標記存儲過程:sp_fulltext_table
5、在全文索引目錄的表中添加或刪除列標記存儲過程:sp_fulltext_column
基本信息
- 中文名
- 全文索引
- 外文名
- term
- 方法
- 先定義一個詞庫
- 性質
- 搜索引擎的關鍵技術