路由演演算法
路由演演算法
路由演演算法,可以根據多個特性來加以區分,演演算法設計者的特定目標影響了該路由協議的操作;具體來說存在著多種路由演演算法,每種演演算法對網路和路由器資源的影響都不同;由於路由演演算法使用多種metric,從而影響到最佳路徑的計算。
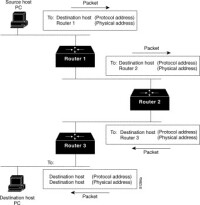
(圖)路由演演算法
路由演演算法必須健壯,即在出現不正常或不可預見事件的情況下必須仍能正常處理,例如硬體故障、高負載和不正確的實現。因為路由器位於網路的連接點,當它們失效時會產生重大的問題。最好的路由演演算法通常是那些經過了時間考驗,證實在各種網路條件下都很穩定的演演算法。
此外路由演演算法必須能快速聚合,聚合是所有路由器對最佳路徑達成一致的過程。當某網路事件使路徑斷掉或不可用時,路由器通過網路分發路由更新信息,促使最佳路徑的重新計算,最終使所有路由器達成一致。聚合很慢的路由演演算法可能會產生路由環或網路中斷。
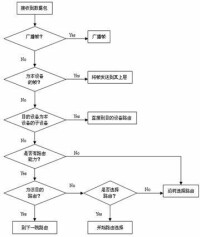
(圖)路由演演算法流程圖
關於路由器如何收集網路的結構信息以及對之進行分析來確定最佳路由,有兩種主要的路由演演算法:
總體式路由演演算法和分散式路由演演算法。採用分散式路由演演算法時,每個路由器只有與它直接相連的路由器的信息——而沒有網路中的每個路由器的信息。這些演演算法也被稱為DV(距離向量)演演算法。採用總體式路由演演算法時,每個路由器都擁有網路中所有其他路由器的全部信息以及網路的流量狀態。這些演演算法也被稱為LS(鏈路狀態)演演算法。
路由演演算法通常具有下列設計目標的一個或多個:優化、簡單、低耗、健壯、穩定、快速聚合、靈活性。
(1)最優化:指路由演演算法選擇最佳路徑的能力。根據metric的值和權值來計算。
(2)簡潔性:演演算法設計簡潔,路由協議必須高效地提供其功能,盡量減少軟體和應用的開銷。當實現路由演演算法的軟體必須運行在物理資源有限的計算機上時高效尤其重要。
(圖)路由演演算法
(4)快速收斂:收斂是在最佳路徑的判斷上所有路由器達到一致的過程。當某個網路事件引起路由可用或不可用時,路由器就發出更新信息。路由更新信息遍及整個網路,引發重新計算最佳路徑,最終達到所有路由器一致公認的最佳路徑。收斂慢的路由演演算法會造成路徑循環或網路中斷。
(5)靈活性:路由演演算法可以快速、準確地適應各種網路環境。例如,某個網段發生故障,路由演演算法要能很快發現故障,並為使用該網段的所有路由選擇另一條最佳路徑。
路由演演算法還應該是靈活的,即它們應該迅速、準確地適應各種網路環境。路由演演算法可以設計得可適應網路帶寬、路由器隊列大小和網路延遲。
路由演演算法的核心是路由選擇演演算法,設計路由演演算法時要考慮的技術要素有:
1、選擇最短路由還是最佳路由;
2、通信子網是採用虛電路操作方式還是採用數據報的操作方式;
3、採用分散式路由演演算法還是採用集中式路由演演算法;
4、考慮關於網路拓撲、流量和延遲等網路信息的來源;
5、確定採用靜態路由還是動態路由。
優化指路由演演算法選擇最佳路徑的能力,根據metric的值和權值來計算。例如有一種路由演演算法可能使用跳數和延遲,但可能延遲的權值要大些。當然,路由協議必須嚴格定義計算metric的演演算法。
各路由演演算法的區別點包括:靜態與動態、單路徑與多路徑、平坦與分層、主機智能與路由器智能、域內與域間、鏈接狀態與距離向量。
1、靜態與動態
靜態路由演演算法很難算得上是演演算法,只不過是開始路由前由網管建立的表映射。這些映射自身並不改變,除非網管去改動。使用靜態路由的演演算法較容易設計,在網路通信可預測及簡單的網路中工作得很好。由於靜態路由系統不能對
(圖)路由演演算法
2、單路徑與多路徑
一些複雜的路由協議支持到同一目的的多條路徑。與單路徑演演算法不同,這些多路徑演演算法允許數據在多條線路上復用。多路徑演演算法的優點很明顯:它們可以提供更好的吞吐量和可靠性。
3、平坦與分層
一些路由協議在平坦的空間里運作,其它的則有路由的層次。在平坦的路由系統中,每個路由器與其它所有路由器是對等的;在分層次的路由系統中,一些路由器構成了路由主幹,數據從非主幹路由器流向主幹路由器,然後在主幹上傳輸直到它們到達目標所在區域,在這裡,它們從最後的主幹路由器通過一個或多個非主幹路由器到達終點。路由系統通常設計有邏輯節點組,稱為域、自治系統或區間。
在分層的系統中,一些路由器可以與其它域中的路由器通信,其它的則只能與域內的路由器通信。在很大的網路中,可能還存在其它級別,最高級的路由器構成了路由主幹。
分層路由的主要優點是它模擬了多數公司的結構,從而能很好地支持其通信。多數的網路通信發生在小組中(域)。因為域內路由器只需要知道本域內的其它路由器,它們的路由演演算法可以簡化,根據所使用的路由演演算法,路由更新的通信量可以相應地減少。
4、主機智能與路由器智能
一些路由演演算法假定源結點來決定整個路徑,這通常稱為源路由。在源路由系統中,路由器只作為存貯轉發設備,無意識地把分組發向下一跳。其它路由演演算法假定主機對路徑一無所知,在這些演演算法中,路由器基於自己的計算決定通過網路的路徑。前一種系統中,主機具有決定路由的智能,後者則為路由器具有此能力。
主機智能和路由器智能的折衷實際是最佳路由與額外開銷的平衡。主機智能系統通常能選擇更佳的路徑,因為它們在發送數據前探索了所有可能的路徑,然後基於特定系統對“優化”的定義來選擇最佳路徑。然而確定所有路徑的行為通常需要很多的探索通信量和很長的時間。
5、域內與域間
一些路由演演算法只在域內工作,其它的則既在域內也在域間工作。這兩種演演算法的本質是不同的。其遵循的理由是優化的域內路由演演算法沒有必要也成為優化的域間路由演演算法。
6、鏈接狀態與距離向量
鏈接狀態演演算法(也叫做短路徑優先演演算法)把路由信息散布到網路的每個節點,不過每個路由器只發送路由表中描述其自己鏈接狀態的部分。距離向量演演算法(也叫做Bellman-Ford演演算法)中每個路由器發送路由表的全部或部分,但只發給其鄰居。也就是說,鏈接狀態演演算法到處發送較少的更新信息,而距離向量演演算法只向相鄰的路由器發送較多的更新信息。
由於鏈接狀態演演算法聚合得較快,它們相對於距離演演算法產生路由環的傾向較小。在另一方面,鏈接狀態演演算法需要更多的CPU和內存資源,因此鏈接狀態演演算法的實現和支持較昂貴。雖然有差異,這兩種演演算法類型在多數環境中都可以工作得很好。
(圖)路由演演算法
通常所使用的度量有:路徑長度、可靠性、時延、帶寬、負載、通信成本等。
路徑長度
路徑長度是最常用的路由metric。一些路由協議允許網管給每個網路鏈接人工賦以代價值,這種情況下,路由長度是所經過各個鏈接的代價總和。其它路由協議定義了跳數,即分組在從源到目的的路途中必須經過的網路產品,如路由器的個數。
可靠性
可靠性,在路由演演算法中指網路鏈接的可依賴性(通常以位誤率描述),有些網路鏈接可能比其它的失效更多,網路失效后,一些網路鏈接可能比其它的更易或更快修復。任何可靠性因素都可以在給可靠率賦值時計算在內,通常是由網管給網路鏈接賦以metric值。
路由延遲
路由延遲指分組從源通過網路到達目的所花時間。很多因素影響到延遲,包括中間的網路鏈接的帶寬、經過的每個路由器的埠隊列、所有中間網路鏈接的擁塞程度以及物理距離。因為延遲是多個重要變數的混合體,它是個比較常用且有效的metric。
帶寬
帶寬指鏈接可用的流通容量。在其它所有條件都相等時,10Mbps的乙太網鏈接比64kbps的專線更可取。雖然帶寬是鏈接可獲得的最大吞吐量,但是通過具有較大帶寬的鏈接做路由不一定比經過較慢鏈接路由更好。例如,如果一條快速鏈路很忙,分組到達目的所花時間可能要更長。
負載
負載指網路資源,如路由器的繁忙程度。負載可以用很多方面計算,包括CPU使用情況和每秒處理分組數。持續地監視這些參數本身也是很耗費資源的。
通信代價
通信代價是另一種重要的metric,尤其是有一些公司可能關係運作費用甚於性能。即使線路延遲可能較長,他們也寧願通過自己的線路發送數據而不採用昂貴的公用線路。
(圖)路由演演算法
採用LS演演算法時,每個路由器必須遵循以下步驟:
1、確認在物理上與之相連的路由器並獲得它們的IP地址。當一個路由器開始工作后,它首先向整個網路發送一個“HELLO”分組數據包。每個接收到數據包的路由器都將返回一條消息,其中包含它自身的IP地址。
2、測量相鄰路由器的延時(或者其他重要的網路參數,比如平均流量)。為做到這一點,路由器向整個網路發送響應分組數據包。每個接收到數據包的路由器返回一個應答分組數據包。將路程往返時間除以2,路由器便可以計算出延時。(路程往返時間是網路當前延遲的量度,通過一個分組數據包從遠程主機返回的時間來測量。)該時間包括了傳輸和處理兩部分的時間——也就是將分組數據包發送到目的地的時間以及接收方處理分組數據包和應答的時間。
3、向網路中的其他路由器廣播自己的信息,同時也接收其他路由器的信息。
在這一步中,所有的路由器共享它們的知識並且將自身的信息廣播給其他每一個路由器。這樣,每一個路由器都能夠知道網路的結構以及狀態。
4、使用一個合適的演演算法,確定網路中兩個節點之間的最佳路由。
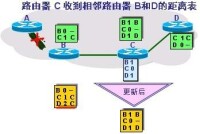
在這一步中,路由器選擇通往每一個節點的最佳路由。它們使用一個演演算法來實現這一點,如Dijkstra最短路徑演演算法。在這個演演算法中,一個路由器通過收集到的其他路由器的信息,建立一個網路圖。這個圖描述網路中的路由器的位置以及它們之間的鏈接關係。每個鏈接都有一個數字標註,稱為權值或成本。這個數字是延時和平均流量的函數,有時它僅僅表示節點間的躍點數。例如,如果一個節點與目的地之間有兩條鏈路,路由器將選擇權值最低的鏈路。
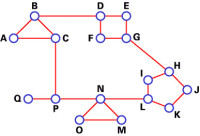
Dijkstra演演算法
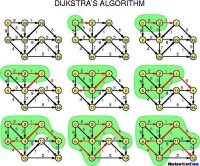
(圖)Dijkstra演演算法
1、路由器建立一張網路圖,並且確定源節點和目的節點,在這個例子里我們設為V1和V2。然後路由器建立一個矩陣,稱為“鄰接矩陣”。在這個矩陣中,各矩陣元素表示權值。例如,[i, j]是節點Vi與Vj之間的鏈路權值。如果節點Vi與Vj之間沒有鏈路直接相連,它們的權值設為“無窮大”。
2、路由器為網路中的每一個節點建立一組狀態記錄。此記錄包括三個欄位:
前序欄位——表示當前節點之前的節點。
長度欄位——表示從源節點到當前節點的權值之和。
標號欄位——表示節點的狀態。每個節點都處於一個狀態模式:“永久”或“暫時”。
3、路由器初始化(所有節點的)狀態記錄集參數,將它們的長度設為“無窮大”,標號設為“暫時”。
4、路由器設置一個T節點。例如,如果設V1是源T節點,路由器將V1的標號更改為“永久”。當一個標號更改為“永久”后,它將不再改變。一個T節點僅僅是一個代理而已。
5、路由器更新與源T節點直接相連的所有暫時性節點的狀態記錄集。
6、路由器在所有的暫時性節點中選擇距離V1的權值最低的節點。這個節點將是新的T節點。
7、如果這個節點不是V2(目的節點),路由器則返回到步驟5。
8、如果節點是V2,路由器則向前回溯,將它的前序節點從狀態記錄集中提取出來,如此循環,直到提取到V1為止。這個節點列表便是從V1到V2的最佳路由。
鏈路狀態演演算法
(圖)鏈路狀態路由演演算法
距離向量演演算法
距離向量演演算法(也稱為Bellman-Ford演演算法)則要求每個路由器發送其路由表全部或部分信息,但僅發送到鄰近結點上。從本質上來說,鏈路狀態演演算法將少量更新信息發送至網路各處,而距離向量演演算法發送大量更新信息至鄰接路由器。 ——由於鏈路狀態演演算法收斂更快,因此它在一定程度上比距離向量演演算法更不易產生路由循環。但另一方面,鏈路狀態演演算法要求比距離向量演演算法有更強的CPU能力和更多的內存空間,因此鏈路狀態演演算法將會在實現時顯得更昂貴一些。
可以看到,在LS和DV演演算法中,每個路由器都需要保存其他路由器的一些信息。隨著網路規模的擴大,網路中的路由器也將增加。因此,路由表的規模也將增大,從而使路由器不能有效地處理網路流量。使用分級路由可以解決這個問題。讓使用DV演演算法來查找節點間的最佳路由。
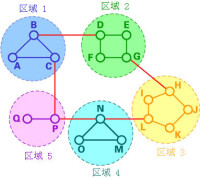
在下述情形中,網路中的每個節點保存了一個有17個記錄的路由表。在分級路由中,路由器被分成很多組,稱為區域。每個路由器都只有自己所在區域路由器的信息,而沒有其他區域路由器的信息。所以在其路由表中,路由器只需要存儲其他每個區域的一條記錄。在這個例子中,我們將網路分為5個區域。
如果A想發送分組數據包到在區域2中的一個路由器(D、E、F或G),它就將分組數據包先發送到B,依此類推。可以看到,在這種類型的路由中,可以對路由表進行概括,因此網路效率提高了。上面的例子描述了一個兩級的分級路由。同樣我們也可以採用三級或者四級的分級路由。
在一個三級的分級路由中,網路被分為很多簇。每個簇由很多個區域組成,每個區域包含很多個路由器。分級路由廣泛應用於網際網路路由中,並且使用了多種路由協議。