共找到2條詞條名為RegExp的結果 展開
- RegExp
- 對字元串操作的一種邏輯公式
RegExp
RegExp
RegExp是一個VBScript5.0的正則表達式對象。
某人一天寫程序的時候出現了一個問題,總是出現不允許操作的對象的錯誤,很奇怪之前一直運行沒有問題的程序,怎麼會有不允許操作的對象呢?只能一步一步的查到底是那個對象不允許操作了,終於找到了這個對象,Set regEx = New RegExp,把所有的文件搜索了一遍,也沒有發現 RegExp,怪不得會出現不允許操作的對象了。
上網搜索RegExp,原來這是一個VBScript5.0的正則表達式對象。只要伺服器安裝了IE5.x,就會VBScript5.0。VB中的replace和execute函數可以執行,那麼這個為什麼不能執行呢?猜想可能是改對象需要註冊組件,開始-運行:regsvr32 vbscript.dll 就OK了。
問題解決了,那麼RegExp該如何使用呢?在網上找到了相關的說明。
在製作網站的時候,尤其是各種電子商務網站,首先都會讓用戶填寫一些表格來獲取註冊用戶的各種信息,因 為用戶有可能輸入各式各樣的信息,而有些不符合要求的數據會給後端ASP處理程序帶來不必要的麻煩,甚至導致網站出現一些安全問題。因此在將這 些信息保存到網站的資料庫之前,要對這些用戶所輸入的信息進行數據的合法性校驗,以便後面的程序可以安全順利的執行。所以一般會在後端編寫一個ASP 的校驗程序來分析用戶輸入的數據是否是合法的。
或許有人會問了,使用運行在客戶端的JavaScript不是可以更好更快的 來校驗用戶的數據嗎?的確,這樣在大多的情況下是可以的,為什麼是大多情況下呢?因為編寫的JavaScript不一定可以完全正常的同時運行在IE以 及Netscape上面,因為微軟的Jscript並不全和JavaScript相同,再加上還有一些瀏覽器不一定和微軟以及Netscape兼容的很 好,所以很有可能在客戶端的Javascript不會精確的校驗用戶輸入的各種數據,而ASP程序是運行在伺服器端的,只是和伺服器的環境有關,無論 客戶端是什麼瀏覽器,對於ASP程序來說都是沒有分別的,所以選擇使用後端的ASP程序來進行數據合法性的校驗是一個好的選擇。
在使用ASP來進行後端的數據合法性校驗的時候,有些人為滿足不同環境下面的數據校驗,編寫了很多的函數來實現,比如,當想要校驗用戶輸入的URL 地址是否合法,是可以自己編寫一段代碼來逐個逐個字元的分析用戶輸入的信息,要分析的信息量小了,那還比較好辦,若是分析的條件千變萬化,那可就慘了,不但要編寫很長很繁瑣的代碼,而且運行的效率極其低下,有沒有好的解決辦法呢?有,那就是VBScritp5.0提供的“正則表達式”對象,只要伺服器安裝了IE5.x,就會帶VBScript5.0。其實,“正則表達式”原本是Unix下面的專利,尤其是在Perl語言中使用得最為廣泛,正是由於“正則表達式”的強大功能,才使得微軟慢慢將正則表達式對象移植到了視窗系統上面,利用“正則表達式”對象,就可以非常方便的對各種數據進行合法性的校驗了。
首先,先來了解一下究竟什麼是VBScript的“正則表達式”對象,來看一段程序:
在這段程序中,看到可以使用“New RegExp”來得到一個正則表達式對象,然後對這個對象進行正則匹配模板的賦值,也就是告訴正則表達式對象,想要匹配一個什麼樣子的模板,然後使用方法Test來檢測待處理的數據和給出的模版是否相匹配,如果不匹配,那就表明待處理的數據不是合法的數據,從而也就實現了數據合法性的校驗,可以看出,使用一個設計合理的匹配模板,可以輕鬆的校驗一批格式類似的數據信息。
當然,VBScript5.0中的“正則表達式”對象還有很多的其他的方法和屬性,比如方法Replace(),利用它以很快的實現現在網上很時髦的UBB風格的論壇以及BBS,這不 在討論範圍之內,以後再加以論述,現在就看看在數據校驗方面正則表達式對象常用的方法和屬性:
常用方法:Execute 方法
描述:對指定的字元串執行正則表達式搜索。
語法:object.Execute(string) Execute 方法的語法包括以下幾個部分:
object:必需的。總是一個 RegExp 對象的名稱。
string:必需的。要在其上執行正則表達式的文本字元串。
說明:正則表達式搜索的設計模式是通過 RegExp 對象的 Pattern 來設置的。Execute 方法返回一個
Matches 集合,其中包含了在 string 中找到的每一個匹配的 Match 對象。如果未找到匹配,Execute 將返回空的 Matches 集合。
Test方法
描述:對指定的字元串執行一個正則表達式搜索,並返回一個 Boolean 值指示是否找到匹配的模式。
語法:object.Test(string)
Test 方法的語法包括以下幾個部分:
object:必需的。總是一個 RegExp 對象的名稱。
string:必需的。要執行正則表達式搜索的文本字元串。
說明:正則表達式搜索的實際模式是通過RegExp對象的Pattern屬性來設置的。RegExp.Global屬性對Test方法沒有影響。如果找到了匹配的模式,Test方法返回True;否則返回False。
常用屬性:Global屬性
描述:設置或返回一個 Boolean 值,該值指明在整個搜索字元串時模式是全部匹配還是只匹配第一個。
語法:object.Global [= True | False ]
object 參數總是 RegExp 對象。如果搜索應用於整個字元串,Global 屬性的值為 True,否則其值為 False。默認的設置為 False。
IgnoreCase屬性
描述:設置或返回一個Boolean值,指明模式搜索是否區分大小寫。
語法:object.IgnoreCase [= True | False ]
object 參數總是一個 RegExp 對象。如果搜索是區分大小寫的,則 IgnoreCase 屬性為 False;否則為 True。預設值為 False。
Pattern屬性
描述:設置或返回被搜索的正則表達式模式。這是一個最重要的屬性,主要是設置這個屬性來實現數據校驗的。
語法:object.Pattern [= "searchstring"]
Pattern 屬性的語法包含以下幾個部分:
object:必需的。總是一個 RegExp 對象變數。
searchstring:可選的。被搜索的正則字元串表達式。它可能包含設置部分表格中的各種正則表達式字元。
設置:在書寫正則表達式的模式時使用了特殊的字元和序列。下表描述了可以使用的字元和序列,並給出了實例。
字元描述:\:將下一個字元標記為特殊字元或字面值。例如"n"與字元"n"匹配。"\n"與換行符匹配。序列"\"與"\"匹配,"\("與"("匹配。
^ :匹配輸入的開始位置。
$ :匹配輸入的結尾。
* :匹配前一個字元零次或幾次。例如,"zo*"可以匹配"z"、"zoo"。
+ :匹配前一個字元一次或多次。例如,"zo+"可以匹配"zoo",但不匹配"z"。
? :匹配前一個字元零次或一次。例如,"a?ve?"可以匹配"never"中的"ve"。
.:匹配換行符以外的任何字元。
(pattern) 與模式匹配並記住匹配。匹配的子字元串可以從作為結果的 Matches 集合中使用 Item [0]...[n]取得。如果要匹配括弧字元(和),可使用"\(" 或 "\)"。
x|y:匹配 x 或 y。例如 "z|food" 可匹配 "z" 或 "food"。"(z|f)ood" 匹配 "zoo" 或 "food"。
:n 為非負的整數。匹配恰好n次。例如,"o" 不能與 "Bob 中的 "o" 匹配,但是可以與"foooood"中的前兩個o匹配。
:n 為非負的整數。匹配至少n次。例如,"o"不匹配"Bob"中的"o",但是匹配"foooood"中所有的o。"o"等價於"o+"。"o"等價於"o*"。
:m 和 n 為非負的整數。匹配至少 n 次,至多 m 次。例如,"o" 匹配 "fooooood"中前三個o。"o"等價於"o?"。
[xyz] :一個字符集。與括弧中字元的其中之一匹配。例如,"[abc]" 匹配"plain"中的"a"。
[^xyz] :一個否定的字符集。匹配不在此括弧中的任何字元。例如,"[^abc]" 可以匹配"plain"中的"p".
[a-z] :表示某個範圍內的字元。與指定區間內的任何字元匹配。例如,"[a-z]"匹配"a"與"z"之間的任何一個小寫字母字元。
[^m-z] :否定的字元區間。與不在指定區間內的字元匹配。例如,"[m-z]"與不在"m"到"z"之間的任何字元匹配。
\b :與單詞的邊界匹配,即單詞與空格之間的位置。例如,"er\b" 與"never"中的"er"匹配,但是不匹配"verb"中的"er"。
\B :與非單詞邊界匹配。"ea*r\B"與"never early"中的"ear"匹配。
\d :與一個數字字元匹配。等價於[0-9]。
\D :與非數字的字元匹配。等價於[^0-9]。
\f :與分頁符匹配。
\n :與換行符字元匹配。
\r :與回車字元匹配。
\s :與任何白字元匹配,包括空格、製表符、分頁符等。等價於"[ \f\n\r\t\v]"。
\S :與任何非空白的字元匹配。等價於"[^ \f\n\r\t\v]"。
\t :與製表符匹配。
\v :與垂直製表符匹配。
\w :與任何單詞字元匹配,包括下劃線。等價於"[A-Za-z0-9_]"。
\W :與任何非單詞字元匹配。等價於"[^A-Za-z0-9_]"。
\num :匹配 num個,其中 num 為一個正整數。引用回到記住的匹配。例如,"(.)"匹配兩個連續的相同的字元。
\n:匹配 n,其中n 是一個八進位換碼值。八進位換碼值必須是 1,2 或 3 個數字長。
例如,"" 和 "1" 都與一個製表符匹配。"11"等價於"1" 與 "1"。八進位換碼值不得超過 256。否則,只有前兩個字元被視為表達式的一部分。允許在正則表達式中使用ASCⅡ碼。
\xn:匹配n,其中n是一個十六進位的換碼值。十六進位換碼值必須恰好為兩個數字長。例如,"\x41"匹配"A"。"\x041"等價於"\x04" 和 "1"。允許在正則表達式中使用 ASCⅡ 碼。
好了,常用的方法和屬性就是這些了,上面的語法介紹的已經很詳細了,沒有必要在啰嗦了,接下來看看在具體的例子裡面如何使用這些方法和屬性來 校驗數據的合法性,還是舉個例子吧,比如,想要對用戶輸入的電子郵件進行校驗,首先,一個合法的電子郵件地址至少應當滿足以下幾個條件:
⒈ 必須包含一個並且只有一個符號“@”
⒉ 必須包含至少一個至多三個符號“.”
⒊ 第一個字元不得是“@”或者“.”
⒋ 不允許出現“@.”或者.@
⒌ 結尾不得是字元“@”或者“.”
所以根據以上的原則和上面表中的語法,很容易的就可以得到需要的模板如下:"(\w)+[@](\w)+[.](\w)+"
接下來仔細分析一下這個模板,首先“\w”表示郵件的開始字元只能是包含下劃線的單詞字元,這樣,滿足了第三個條件;“[@]”表示在電子郵件中應 當匹配並且只能匹配一次字元“@”,滿足了條件一;同樣的“[.]”表示在電子郵件中至少匹配1個至多匹配3個字元“.” ,滿足了第二個條件;模板最後的“(\w)+”表示結尾的字元只能是包含下劃線在內的單詞字元,滿足了條件五;模板中間的“(\w)+”滿足了條件四。
然後,直接調用剛才的那個函數CheckExp("(\w)+[@](\w)+[.](\w)+",待校驗的字元串)就好了,如果返回True就 表示數據是合法的,否則就是不正確的,怎麼樣,簡單吧。還可以寫出來校驗身份證號碼的模板:"([0-9])";校驗URL的模板:"^http: //((\w)+[.])"等等;可以看到,這些模板提供了很好的可重利用的模塊,利用自己或者別人提供的各種模板,可以方便快捷的進行 數據的合法性校驗了,相信一定會寫出非常通用的模板的。
這樣,只要定製不同的模板,就可以實現對不同數據的合法性校驗了。所以,正則表達式對象中最重要的屬性就是:“Pattern”屬性,只要真正掌握了這個屬性,才可以自由的運用正則表達式對象來為數據校驗進行服務。-------------------------------------------RegExp對象提供簡單的正則表達式支持功能。
RegExp對象的用法:
RegExp 對象的屬性
◎ Global屬性
Global屬性設置或返回一個 Boolean 值,該值指明在整個搜索字元串時模式是全部匹配還是只匹配第一個。
語法
object.Global [= True | False ]
object 參數總是 RegExp 對象。如果搜索應用於整個字元串,Global 屬性的值為 True,否則其值為 False。默認的設置為 True。
Global 屬性的用法(改變賦予 Global 屬性的值並觀察其效果):
◎ IgnoreCase屬性
IgnoreCase屬性設置或返回一個Boolean值,指明模式搜索是否區分大小寫。
語法
object.IgnoreCase [= True | False ]
object 參數總是一個 RegExp 對象。如果搜索是區分大小寫的,則 IgnoreCase 屬性為 False;否則為 True。預設值為 True。
IgnoreCase 屬性的用法(改變賦予 IgnoreCase 屬性的值以觀察其效果):
◎ Pattern屬性
Pattern屬性設置或返回被搜索的正則表達式模式。
語法
object.Pattern [= "searchstring"]
Pattern 屬性的語法包含以下幾個部分:
語法說明:
object 必需的。總是一個 RegExp 對象變數。
searchstring 可選的。被搜索的正則字元串表達式。它可能包含設置部分表格中的各種正則表達式字元。
設置
在書寫正則表達式的模式時使用了特殊的字元和序列。下面描述了可以使用的字元和序列,並給出了實例。
\ 將下一個字元標記為特殊字元或字面值。例如"n"與字元"n"匹配。"\n"與換行符匹配。序列"\"與"\"匹配對面,"\("與"("匹配。
^ 匹配輸入的開始位置。
$ 匹配輸入的結尾。
* 匹配前一個字元零次或幾次。例如,"zo*"可以匹配"z"、"zoo"。
+ 匹配前一個字元一次或多次。例如,"zo+"可以匹配"zoo",但不匹配"z"。
? 匹配前一個字元零次或一次。例如,"a?ve?"可以匹配"never"中的"ve"。
. 匹配換行符以外的任何字元。
(pattern) 與模式匹配並記住匹配。匹配的子字元串可以從作為結果的 Matches 集合中使用 Item [0]...[n]取得。如果要匹配括弧字元(和),可使用"\(" 或 "\)"。
x|y 匹配 x 或 y。例如 "z|food" 可匹配 "z" 或 "food"。"(z|f)ood" 匹配 "zoo" 或 "food"。
n 為非負的整數。匹配恰好n次。例如,"o" 不能與 "Bob 中的 "o" 匹配,但是可以與"foooood"中的前兩個o匹配。
{n,} n 為非負的整數。匹配至少n次。例如,"o{2,}"不匹配"Bob"中的"o",但是匹配"foooood"中所有的o。"o{1,}"等價於"o+"。"o{0,}"等價於"o*"。
{n,m} m 和 n 為非負的整數。匹配至少 n 次,至多 m 次。例如,"o{1,3}" 匹配 "fooooood"中前三個o。"o{0,1}"等價於"o?"。
[xyz] 一個字符集。與括弧中字元的其中之一匹配。例如,"[abc]" 匹配"plain"中的"a"。
[^xyz] 一個否定的字符集。匹配不在此括弧中的任何字元。例如,"[^abc]" 可以匹配"plain"中的"p".
[a-z] 表示某個範圍內的字元。與指定區間內的任何字元匹配。例如,"[a-z]"匹配"a"與"z"之間的任何一個小寫字母字元。
[^m-z] 否定的字元區間。與不在指定區間內的字元匹配。例如,"[m-z]"與不在"m"到"z"之間的任何字元匹配。
\b 與單詞的邊界匹配,即單詞與空格之間的位置。例如,"er\b" 與"never"中的"er"匹配,但是不匹配"verb"中的"er"。
\B 與非單詞邊界匹配。"ea*r\B"與"never early"中的"ear"匹配。
\d 與一個數字字元匹配。等價於[0-9]。
\D 與非數字的字元匹配。等價於[^0-9]。
\f 與分頁符匹配。
\n 與換行符字元匹配。
\r 與回車字元匹配。
\s 與任何白字元匹配,包括空格、製表符、分頁符等。等價於"[ \f\n\r\t\v]"。
\S 與任何非空白的字元匹配。等價於"[^ \f\n\r\t\v]"。
\t 與製表符匹配。
\v 與垂直製表符匹配。
\w 與任何單詞字元匹配,包括下劃線。等價於"[A-Za-z0-9_]"。
\W 與任何非單詞字元匹配。等價於"[^A-Za-z0-9_]"。
\num 匹配 num個,其中 num 為一個正整數。引用回到記住的匹配。例如,"(.)"匹配兩個連續的相同的字元。
\n 匹配 n,其中n 是一個八進位換碼值。八進位換碼值必須是 1,2 或 3 個數字長。例如,"" 和 "1" 都與一個製表符匹配。"11"等價於"1" 與 "1"。八進位換碼值不得超過 256。否則,只有前兩個字元被視為表達式的一部分。允許在正則表達式中使用ASCⅡ碼。
\xn 匹配n,其中n是一個十六進位的換碼值。十六進位換碼值必須恰好為兩個數字長。例如,"\x41"匹配"A"。"\x041"等價於"\x04" 和 "1"。允許在正則表達式中使用 ASCⅡ 碼。
Pattern 屬性的用法:
RegExp對象的方法
◎ Execute方法
Execute方法對指定的字元串執行正則表達式搜索。
語法
object.Execute(string)
語法部分描述
object 必需的。總是一個 RegExp 對象的名稱。
string 必需的。要在其上執行正則表達式的文本字元串。
說明
正則表達式搜索的設計模式是通過 RegExp 對象的 Pattern 來設置的。
Execute 方法返回一個 Matches 集合,其中包含了在 string 中找到的每一個匹配的 Match 對象。如果未找到匹配,Execute 將返回空的 Matches 集合。
Execute 方法的用法:
◎ Replace方法
Replace方法替換在正則表達式查找中找到的文本。
語法
object.Replace(string1,string2)
語法部分描述
object 必需的。總是一個 RegExp 對象的名稱。
string1 必需的。string1 是將要進行文本替換的字元串。
string2 必需的。string2 是替換文本字元串。
說明
被替換的文本的實際模式是通過 RegExp 對象的 Pattern 屬性設置的。
Replace 方法返回 string1 的副本,其中的 RegExp.Pattern 文本已經被替換為 string2。如果沒有找到匹配的文本,將返回原來的 string1 的副本。
Replace 方法的用法:
' 將 'fox' 替換為 'cat'。
;另外,Replace 方法在模式中替換 subexpressions。下面對以前示例中函數的調用,替換了原字元串中的所有字對:
MsgBox(ReplaceText("(\S+)(\s+)(\S+)","")) ' Swap pairs of words.
◎ Test方法
Test方法對指定的字元串執行一個正則表達式搜索,並返回一個 Boolean 值指示是否找到匹配的模式。
語法
object.Test(string)
語法部分描述
object 必需的。總是一個 RegExp 對象的名稱。
string 必需的。要執行正則表達式搜索的文本字元串。
說明
正則表達式搜索的實際模式是通過RegExp對象的Pattern屬性來設置的。RegExp.Global屬性對Test方法沒有影響。
如果找到了匹配的模式,Test方法返回True;否則返回False。
Test 方法的用法:
RegExp 對象
構造函數
new RegExp(“表達式”,”屬性”)
FF: Firefox,N: Netscape,IE: Internet Explorer;數字錶示此版本以後支持
屬性 描述 FF N IE
global
RegExp 對象是否具有標誌 g。1 4 4
ignoreCase
RegExp 對象是否具有標誌 i。1 4 4
lastIndex
一個整數,標示開始下一次匹配的字元位置。1 4 4
multiline
RegExp 對象是否具有標誌 m。1 4 4
source
正則表達式的源文本。1 4 4
方法 描述 FF N IE
exec
檢索字元串中指定的值。返回找到的值(存放於數組中)。1 4 4
test
檢索字元串中指定的值。返回 true 或 false。1 4 4
說明:
⒈exec() 找到了匹配的文本,則返回一個結果數組。否則,返回 null。此數組的第 0 個元素是與正則表達式相匹配的文本,第 1 個元素是與 RegExpObject 的第 1 個子表達式相匹配的文本(如果有的話),第 2 個元素是與 RegExpObject 的第 2 個子表達式相匹配的文本(如果有的話),以此類推。除了數組元素和 length 屬性之外,exec() 方法還返回兩個屬性。index 屬性聲明的是匹配文本的第一個字元的位置。input 屬性則存放的是被檢索的字元串 string。
⒉使用過的正則對象會從上次匹配位置開始新匹配。
⒊如果構造函數中屬性包含i,會把所有匹配項強制轉換為小寫。
⒋正則對象中不包含g的話只處理一次匹配。
簡單示例:
實例化一個RegExp:
支持正則表達式的 String 對象的方法
方法 描述 FF N IE
search
檢索與正則表達式相匹配的值,返回位置。1 4 4
match
找到一個或多個(含屬性g)正在表達式的匹配,返回字元串或數組 1 4 4
replace
替換與正則表達式匹配的子串,返回替換后的字元串。1 4 4
split
把字元串分割為字元串數組,返回數組。1 4 4
說明:
⒈ replace函數的第二個參數可以是一個函數,此時會調用此函數處理每一次匹配。
⒉ replace函數的正則參數如果不包含g屬性,將只替換第一個匹配。
簡單示例:
將 str中的url添加上html a標籤。(注意:此demo代碼並不實用)
RegExp 是正則表達式的縮寫。
當檢索某個文本時,可以使用一種模式來描述要檢索的內容。RegExp 就是這種模式。
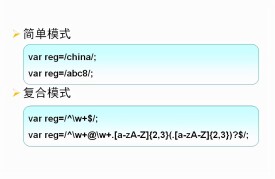
簡單的模式可以是一個單獨的字元。
更複雜的模式包括了更多的字元,並可用於解析、格式檢查、替換等等。
可以規定字元串中的檢索位置,以及要檢索的字元類型,等等。
RegExp 對象表示正則表達式,它是對字元串執行模式匹配的強大工具
RegExp 對象用於存儲檢索模式。
通過 new 關鍵詞來定義 RegExp 對象。以下代碼定義了名為 patt1 的 RegExp 對象,其模式是 "e":
var patt1 = new RegExp("e");
創建RegExp對象語法:
RegExp 對象有 3 個方法:test()、exec() 以及 compile()。
test()
test() 方法檢索字元串中的指定值。返回值是 true 或 false。
例子:
由於該字元串中存在字母 "e",以上代碼的輸出將是:
true
true
exec()
exec() 方法檢索字元串中的指定值。返回值是被找到的值。如果沒有發現匹配,則返回 null。
例子 1:
由於該字元串中存在字母 "e",以上代碼的輸出將是:
e e
例子 2:
可以向 RegExp 對象添加第二個參數,以設定檢索。例如,如果需要找到所有某個字元的所有存在,則可以使用 "g" 參數 ("global")。
如需關於如何修改搜索模式的完整信息,請訪問 RegExp 對象參考手冊。
在使用 "g" 參數時,exec() 的工作原理如下:
找到第一個 "e",並存儲其位置
如果再次運行 exec(),則從存儲的位置開始檢索,並找到下一個 "e",並存儲其位置
由於這個字元串中 6 個 "e" 字母,代碼的輸出將是:
eeeeeenull
eeeeeenull
compile()
compile() 方法用於改變 RegExp。
compile() 既可以改變檢索模式,也可以添加或刪除第二個參數。
由於字元串中存在 "e",而沒有 "d",以上代碼的輸出是:
truefalse
new RegExp(pattern,attributes);
參數:
參數pattern 是一個字元串,指定了正則表達式的模式或其他正則表達式。
參數attributes 是一個可選的字元串,包含屬性 "g"、"i" 和 "m",分別用於指定全局匹配、區分大小寫的匹配和多行匹配。ECMAScript 標準化之前,不支持 m 屬性。如果pattern 是正則表達式,而不是字元串,則必須省略該參數。
返回值:
一個新的 RegExp 對象,具有指定的模式和標誌。如果參數pattern 是正則表達式而不是字元串,那麼 RegExp() 構造函數將用與指定的 RegExp 相同的模式和標誌創建一個新的 RegExp 對象。
如果不用 new 運算符,而將 RegExp() 作為函數調用,那麼它的行為與用 new 運算符調用時一樣,只是當pattern 是正則表達式時,它只返回pattern,而不再創建一個新的 RegExp 對象。
拋出:
SyntaxError - 如果pattern 不是合法的正則表達式,或attributes 含有 "g"、"i" 和 "m" 之外的字元,拋出該異常。
TypeError - 如果pattern 是 RegExp 對象,但沒有省略attributes 參數,拋出該異常。
修飾符:
| 修飾符 | 描述 |
| i | 執行對大小寫不敏感的匹配。 |
| g | 執行全局匹配(查找所有匹配而非在找到第一個匹配后停止)。 |
| m | 執行多行匹配。 |
方括弧:
方括弧用於查找某個範圍內的字元:
| 表達式 | 描述 |
| [abc] | 查找方括弧之間的任何字元。 |
| [^abc] | 查找任何不在方括弧之間的字元。 |
| [0-9] | 查找任何從 0 至 9 的數字。 |
| [a-z] | 查找任何從小寫 a 到小寫 z 的字元。 |
| [A-Z] | 查找任何從大寫 A 到大寫 Z 的字元。 |
| [a-Z] | 查找任何從小寫 a 到大寫 Z 的字元。 |
| [adgk] | 查找給定集合內的任何字元。 |
| [^adgk] | 查找給定集合外的任何字元。 |
| [red|blue|green] | 查找任何指定的選項。 |
支持正則表達式的String對象的方法:
FF: Firefox,IE: Internet Explorer
| 方法 | 描述 | FF | IE |
| search | 檢索與正則表達式相匹配的值。 | 1 | 4 |
| match | 找到一個或多個正則表達式的匹配。 | 1 | 4 |
| replace | 替換與正則表達式匹配的子串。 | 1 | 4 |
| split | 把字元串分割為字元串數組。 | 1 | 4 |
基本信息
- 外文名
- RegExp
- 相關技術
- 正則表達式
- 語法
- object.Test(string)