Cluster
Cluster
簇(cluster),我們知道磁碟是由一個一個扇區組成的,若干個扇區合為一個簇,文件存取是以簇為單位的,哪怕這個文件只有1個位元組。每個簇在文件分配表中都有對應的表項,簇號即為表項號,每個表項佔1.5個位元組(磁碟空間在10MB以下)或2個位元組(磁碟空間在10MB以上)。
文件佔用磁碟空間,基本單位不是位元組而是簇。一般情況下,軟盤每簇是1個扇區,硬碟每簇的扇區數與硬碟的總容量大小有關,可能是4、8、16、32、64……同一個文件的數據並不一定完整地存放在磁碟的一個連續的區域內,而往往會分成若干段,像一條鏈子一樣存放。這種存儲方式稱為文件的鏈式存儲。由於硬碟上保存著段與段之間的連接信息(即FAT),操作系統在讀取文件時,總是能夠準確地找到各段的位置並正確讀出。為了實現文件的鏈式存儲,硬碟上必須準確地記錄哪些簇已經被文件佔用,還必須為每個已經佔用的簇指明存儲後繼內容的下一個簇的簇號。對一個文件的最後一簇,則要指明本簇無後繼簇。這些都是由FAT表來保存的,表中有很多表項,每項記錄一個簇的信息。由於FAT對於文件管理的重要性,所以為了安全起見,FAT有一個備份,即在原FAT的後面再建一個同樣的FAT。初形成的FAT中所有項都標明為“未佔用”,但如果磁碟有局部損壞,那麼格式化程序會檢測出損壞的簇,在相應的項中標為“壞簇”,以後存文件時就不會再使用這個簇了。FAT的項數與硬碟上的總簇數相當,每一項佔用的位元組數也要與總簇數相適應,因為其中需要存放簇號。
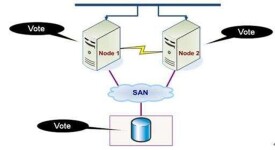
一個計算機集群是指一組連接起來的電腦,它們共同工作對外界來說就像一個電腦一樣。集群一般由區域網連接,但也有例外。集群一般用於單個電腦無法完成的高性能計算,擁有較高的性價比。
baidu和google的後台伺服器就是一個cluster
Cluster技術發展多年了,但其實並沒有一個非常準確的定義和分類,不同的人有不同的理解。
其實,叫什麼無所謂,只要能夠對用戶有益就可以了. :-)
就個人理解而言,cluster有以下幾種,當然前面說過,不同的人有不同的理解,大家可以充分討論。我的這些分類更偏重於工程而不是技術性。
實現高可用性,但對單個應用性能沒有提高,市場上大部分產品都是屬於這類,技術上也較簡單。
利用IP技術實現對通用IP應用的支持。這種技術並不是很新,最早是在硬體上面採用的,Linux出現后才有了很多純軟體的模式,這也是open source帶來的好處吧
包括了一些象PVM,beowulf這樣的信息傳遞機制和API庫,也有任務調度產品,當然技術上最難的是并行編譯/并行系統等更智能化的產品
雖然cluster的最高目的是實現真正的與應用程序無關的動態負載均衡,但由於技術上的限制,現在都只能在特殊的應用中實現,需要修改應用程序,所以並沒有通用產品,大多是廠商有自己的并行版本。例如oracle paraller server.
以上基本是按照工程或者說產品的角度劃分的,和技術上劃分應該有一定區別。
集群就是由一些互相連接在一起的計算機構成的一個并行或分散式系統,從外部來看,它們僅僅是一個系統,對外提供統一的服務。
集群技術本身有很多種分類,市場上的產品也很多,都沒有很標準的定義。一般可以分為以下幾種:
嚴格來講,這種冗餘系統並不能叫做真正的集群,因為它只能夠提高系統的可用性,卻無法提高系統的整體性能。
有以下幾種類型。
A. 容錯機
特點是在一台機器內部對其所有的硬體部件都進行冗餘(包括硬碟、控制卡、匯流排、電源等等)。
能夠基本做到與軟體系統無關,而且可實現無縫切換,但價格極其昂貴。
典型市場產品:Compaq NonStop(Tandem),Micron(NetFrame),Straus
B. 基於系統鏡像的雙機系統
特點是利用雙機,將系統的數據和運行狀態(包括內存中的數據)進行鏡像,從而實現熱備份的目的。
能夠做到無縫切換,但因為採用軟體控制,佔用系統資源較大,而且由於兩台機器需要完全一樣的配置,所以性能價格比太低。
典型市場產品:Novell SFT III,Marathon Endurance 4000 for NT
C. 基於系統切換的雙機系統
特點是利用雙機,將系統的數據(僅指硬碟數據)進行鏡像,在主機失效的情況下從機將進行系統一級的切換。
性能價格比適中,但無法實現無縫切換。
典型市場產品:Legato(Vinca) StandbyServer for NetWare,Savoir(WesternMicro)SavWareHA(Sentinel),Compaq StandbyServer
特點是當集群中的某個節點故障時,其它節點可以進行應用程序一級的切換,所以所有節點在正常狀態下都可以對外提供自己的服務,也被成為靜態的負載均衡方式。
性能價格比高,但也無法實現無縫切換,而且對單個應用程序本身無法做到負載均衡。
典型市場產品:Legato(Vinca) Co-StandbyServer for NT,Novell HA Server,Microsoft Cluster Server,DEC Cluster for NT,Legato Octopus,Legato FullTime,NeoHigh Rose HA,SUN Clusters,Veritas Cluster Server (FirstWatch),CA SurvivIT,1776
主要應用於科學計算、大任務量的計算等環境。有并行編譯、進程通訊、任務分發等多種實現方法。
典型市場產品:TurboLinux enFuzion,Beowulf,Supercomputer Architectures,Platform
所有節點對外提供相同的服務,這樣可以實現對單個應用程序的負載均衡,而且同時提供了高可用性。
性能價格比極高,但目前無法支持資料庫。
典型市場產品:TurboCluster Server,Linux Virtual Server,F5 BigIP,Microsoft Windows NT Load Balance Service
負載均衡是提高系統性能的一種前沿技術。還是沿用前面的例子,一台IA伺服器的處理能力是每秒幾萬個,顯然無法在一秒鐘內處理幾十萬個請求,但如果我們能夠有10台這樣的伺服器組成一個系統,如果有辦法將所有的請求平均分配到所有的伺服器,那麼這個系統就擁有了每秒處理幾十萬個請求的能力。這就是負載均衡的基本思想。
實際上,目前市場上有多家廠商的負載均衡產品。由於其應用的主要技術的不同,也就有著不同的特點和不同的性能。
輪詢DNS方案可以說是技術上最簡單也最直觀的一種方案。當然,這種方案只能夠實現負載均衡的功能,卻無法實現對高可用性的保證。
它的原理是在DNS伺服器中設定對同一個Internet主機名的多個IP地址的映射。這樣,在DNS收到查詢主機名的請求時,會循環的將所有對應的IP地址逐個返回。這樣,就能夠將不同的客戶端連接定位到不同的IP主機上,也就能夠實現比較簡單的負載均衡功能。但是,這種方案有兩個比較致命的缺點:
l 只能夠實現對基於Internet主機名請求的負載均衡,如果是直接基於IP地址的請求則無能為力。
l 在集群內有節點發生故障的情況下,DNS伺服器仍會將這個節點的IP地址返回給查詢方,也就仍會不斷的有客戶請求試圖與已故障的節點建立連接。這種情況下,即使你手工修改DNS伺服器的對應設置,將故障的IP地址刪除,由於Internet上所有的DNS伺服器都有緩存機制,仍會有成千上萬的客戶端連接不到集群,除非等到所有的DNS緩存都超時。
有些廠商提供對負載均衡的硬體解決方案,製造出帶有NAT(網路地址轉換)功能的高檔路由器或交換機來實現負載均衡功能。NAT本身的原理就是實現多個私有IP地址對單個公共IP地址的轉換。代表產品是Cicso公司和Alteon公司的某些高檔硬體交換機系列。這種方案有如下缺點:
l 由於採用了特殊的硬體,使得整個系統中存在非工業標準部件,極大的影響系統的擴充和維護、升級工作。
l 價格極其昂貴,和軟體的解決方案根本是數量級上的差別。
l 一般只能實現對節點系統一級的狀態檢查,無法細化到服務一級的檢查。
l 由於採用NAT機制,集群管理節點本身要完成的工作量很大,很容易成為整個系統的瓶頸。
l 此特殊硬體本身就是單一故障點。
l 實現異地節點的集群非常困難。
這種方案的原理是客戶請求會同時被所有的節點所接收,然後所有節點按照一定的規則協商決定由哪個節點處理這個請求。此種方案中比較顯著的特點就是整個集群中沒有顯著的管理節點,所有決定由全體工作節點共同協商作出。代表產品是Microsoft公司的Microsoft Load Balancing Service這種方案的特點是:
l 由於各節點間要進行的通訊量太大,加重了網路的負擔,一般需要增加節點通訊的專用網路,也就加大了安裝和維護的難度和費用。
l 由於每個節點都要接收所有的客戶請求並進行分析,極大的加大了網路驅動層的負擔,也就減低了節點本身的工作效率,同時也時網路驅動層很容易成為節點系統的瓶頸。
l 由於要更改網路驅動層的程序,所以並不是一個通用的方案,只能夠實現對特殊平台的支持。
l 在小量節點的情況下協商的效率還可以接受,一旦節點數量增加,通訊和協商將變得異常複雜和低效,整個系統的性能會有非線性的大幅度下降。所以此類方案,一般在理論上也只允許最多十幾個的節點。
l 無法實現異地節點的集群。
l 由於集群內沒有統一的管理者,所以可能出現混亂的異常現象。
流量分發的原理是所有的用戶請求首先到達集群的管理節點,管理節點可以根據所有服務節點的處理能力和現狀來決定將這個請求分發給某個服務節點。當某個服務節點由於硬體或軟體原因故障時,管理節點能夠自動檢測到並停止向這個服務節點分發流量。這樣,既通過將流量分擔而增加了整個系統的性能和處理能力,又可以很好的提高系統的可用性。
通過將管理節點本身做一個子集群可以消除由於管理節點自身的單一性帶來的單一故障點。有些傳統技術人員認為,因為所有的客戶流量都將通過管理節點,所以管理節點很容易成為整個系統的瓶頸。但TurboCluster Server通過先進的直接路由或IP隧道轉發機制巧妙的解決了問題。使得所有對客戶響應的流量都由服務節點直接返回給客戶端,而並不需要再次通過管理節點。眾所周知,對於服務提供商而言,進入的流量要遠遠小於流出的流量,所以管理節點本身將不再是瓶頸。
流量分發的具體實現方法有直接路由、IP隧道和網路地址轉換三種方法。TurboCluster Server目前支持效率最高的前兩種。由於這種先進的結構和技術,使得TurboCluster Server集群內的服務節點數並沒有上限,而且對大量節點的協同工作的效率也能夠非常好的保證。
集群技術已經發展了多年,其中的分支也非常多。目前集群技術正逐漸走向分層結構,以後也肯定會有專門用戶前端、後端的集群產品出現。
隨著計算機應用地位的逐漸提升,系統安全和重要性的日益增加,集群技術必將會有著極為廣闊的應用前景。
基本信息
- 實質
- 若干個扇區合為一個簇
- 簡介
- 文件存取是以簇為單位
- 意義
- 表項號