GROUP BY
GROUP BY
GROUP BY語句用於結合聚合函數,根據一個或多個列對結果集進行分組。
GROUP BY
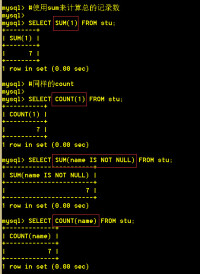
2.Group By的使用:
上面已經給出了對Group By語句的理解。基於這個理解和SQL Server 2000的聯機幫助,下面對Group By語句的各種典型使用進行依次列舉說明。
2.1 Group By [Expressions]:
這個恐怕是Group By語句最常見的用法了,Group By+[分組欄位](可以有多個)。在執行了這個操作以後,數據集將根據分組欄位的值將一個數據集劃分成各個不同的小組。比如有如下數據集,其中水果名稱(FruitName)和出產國家(ProductPlace)為聯合主鍵:
| FruitName | ProductPlace | Price |
| Apple | China | $1.1 |
| Apple | Japan | $2.1 |
| Apple | USA | $2.5 |
| Orange | China | $0.8 |
| Banana | China | $3.1 |
| Peach | USA | $3.0 |
如果我們想知道每個國家有多少種水果,那麼可以通過如下SQL語句來完成:
SELECT COUNT(*) AS水果種類,ProductPlace AS出產國
FROM T_TEST_FRUITINFO
GROUP BY ProductPlace
這個SQL語句就是使用了Group By+分組欄位的方式,那麼這句SQL語句就可以解釋成“我按照出產國家(ProductPlace)將數據集進行分組,然後分別按照各個組來統計各自的記錄數量。”很好理解對吧。這裡值得注意的是結果集中有兩個返回欄位,一個是ProductPlace(出產國),一個是水果種類。如果我們這裡水果種類不是用Count(*),而是類似如下寫法的話:
SELECT FruitName, ProductPlace FROM T_TEST_FRUITINFO GROUP BY ProductPlace
那麼SQL在執行此語句的時候會報如下的類似錯誤:
選擇列表中的列'T_TEST_FRUITINFO.FruitName'無效,因為該列沒有包含在聚合函數或GROUP BY子句中。
這就是我們需要注意的一點,如果在返回集欄位中,這些欄位要麼就要包含在Group By語句的後面,作為分組的依據;要麼就要被包含在聚合函數中。我們可以將Group By操作想象成如下的一個過程,首先系統根據SELECT語句得到一個結果集,如最開始的那個水果、出產國家、單價的一個詳細表。然後根據分組欄位,將具有相同分組欄位的記錄歸併成了一條記錄。這個時候剩下的那些不存在於Group By語句後面作為分組依據的欄位就有可能出現多個值,但是當前一種分組情況只有一條記錄,一個數據格是無法放入多個數值的,所以這裡就需要通過一定的處理將這些多值的列轉化成單值,然後將其放在對應的數據格中,那麼完成這個步驟的就是聚合函數。這就是為什麼這些函數叫聚合函數(aggregate functions)了。
2.2 Group By All[expressions]:
Group By All +分組欄位, 這個和前面提到的Group By [Expressions]的形式多了一個關鍵字ALL。這個關鍵字只有在使用了where語句且where條件篩選掉了一些組的情況下才可以看出效果。在SQL Server 2000的聯機幫助中,對於Group By All是這樣進行描述的:
如果使用ALL關鍵字,那麼查詢結果將包括由GROUP BY子句產生的所有組,即使某些組沒有符合搜索條件的行。沒有ALL關鍵字,包含GROUP BY子句的 SELECT語句將不顯示沒有符合條件的行的組。
其中有這麼一句話“如果使用ALL關鍵字,那麼查詢結果將包含由Group By子句產生的所有組...沒有ALL關鍵字,那麼不顯示不符合條件的行組。”這句話聽起來好像挺耳熟的,對了,好像和LEFT JOIN 和 RIGHT JOIN有點像。其實這裡是類比LEFT JOIN來進行理解的。還是基於如下這樣一個數據集:
| FruitName | ProductPlace | Price |
| Apple | China | $1.1 |
| Apple | Japan | $2.1 |
| Apple | USA | $2.5 |
| Orange | China | $0.8 |
| Banana | China | $3.1 |
| Peach | USA | $3.0 |
首先我們不使用帶ALL關鍵字的Group By語句:
那麼在最後結果中由於Japan不符合where語句,所以分組結果中將不會出現Japan。
如今我們加入ALL關鍵字:
重新運行后,我們可以看到Japan的分組,但是對應的“水果種類”不會進行真正的統計,聚合函數會根據返回值的類型用默認值0或者NULL來代替聚合函數的返回值。
2.3 GROUP BY [Expressions] WITH CUBE | ROLLUP:
首先需要說明的是Group By All語句是不能和CUBE和ROLLUP關鍵字一起使用的。
首先先說說CUBE關鍵字,以下是SQL Server 2000聯機幫助中的說明:
在結果集內返回每個可能的組和子組組合的GROUP BY匯總行。GROUP BY匯總行在結果中顯示為NULL,但可用來表示所有值。使用GROUPING函數確定結果集內的空值是否是GROUP BY匯總值。
結果集內的匯總行數取決於GROUP BY子句內包含的列數。GROUP BY子句中的每個操作數(列)綁定在分組 NULL下,並且分組適用於所有其它操作數(列)。由於CUBE返回每個可能的組和子組組合,因此不論指定分組列時所使用的是什麼順序,行數都相同。
我們通常的Group By語句是按照其後所跟的所有欄位進行分組,而如果加入了CUBE關鍵字以後,那麼系統將根據所有欄位進行分組的基礎上,還會通過對所有這些分組欄位所有可能存在的組合形成的分組條件進行分組計算。由於上面舉的例子過於簡單,這裡就不再適合了,如今我們的數據集將換一個場景,一個表中包含人員的基本信息:員工所在的部門編號(C_EMPLINFO_DEPTID)、員工性別(C_EMPLINFO_SEX)、員工姓名(C_EMPLINFO_NAME)等。那麼我如今想知道每個部門各個性別的人數,那麼我們可以通過如下語句得到:
1.所有部門有多少人(這裡相當於就不進行分組了,因為這裡已經對員工的部門和性別沒有做任何限制了,但是這的確也是一種分組條件的組合方式);
2.每種性別有多人(這裡實際上是僅僅根據性別(C_EMPLINFO_SEX)進行分組);
3.每個部門有多少人(這裡僅僅是根據部門(C_EMPLINFO_DEPTID)進行分組);那麼我們就可以使用ROLLUP語句了。
1 2 3 | SELECTC_EMPLINFO_DEPTID,C_EMPLINFO_SEX,COUNT(*)ASC_EMPLINFO_TOTALSTAFFNUM FROMT_PERSONNEL_EMPLINFO GROUPBYC_EMPLINFO_DEPTID,C_EMPLINFO_SEXWITHCUBE |
那麼這裡你可以看到結果集中多出了很多行,而且結果集中的某一個欄位或者多個欄位、甚至全部的欄位都為NULL,請仔細看一下你就會發現實際上這些記錄就是完成了上面我所列舉的所有統計數據的展現。使用過SQL Server 2005或者RDLC的朋友們一定對於矩陣的小計和分組功能有印象吧,是不是都可以通過這個得到答案。我想RDLC中對於分組和小計的計算就是通過Group By的CUBE和ROLLUP關鍵字來實現的。(個人意見,未證實)
CUBE關鍵字還有一個極為相似的兄弟ROLLUP, 同樣我們先從這英文入手,ROLL UP是“向上卷”的意思,如果說CUBE的組合是絕對自由的,那麼ROLLUP的組合就需要有點約束了。我們先來看看SQL Server 2000的聯機中對ROLLUP關鍵字的定義:
指定在結果集內不僅包含由 GROUP BY 提供的正常行,還包含匯總行。按層次結構順序,從組內的最低級別到最高級別匯總組。組的層次結構取決於指定分組列時所使用的順序。更改分組列的順序會影響在結果集內生成的行數。
那麼這個順序是什麼呢?對了就是Group By 後面欄位的順序,排在靠近Group By的分組欄位的級別高,然後是依次遞減。如:Group By Column1, Column2, Column3。那麼分組級別從高到低的順序是:Column1 > Column2 > Column3。還是看我們前面的例子,SQL語句中我們僅僅將CUBE關鍵字替換成ROLLUP關鍵字,如:
1 2 3 | SELECTC_EMPLINFO_DEPTID,C_EMPLINFO_SEX,COUNT(*)ASC_EMPLINFO_TOTALSTAFFNUM FROMT_PERSONNEL_EMPLINFO GROUPBYC_EMPLINFO_DEPTID,C_EMPLINFO_SEXWITHROLLUP |
和CUBE相比,返回的數據行數減少了不少。:),仔細看一下,除了正常的Group By語句后,數據中還包含了:
1.部門員工數;(向上卷了一次,這次先去掉了員工性別的分組限制)
2.所有部門員工數;(向上又卷了依次,這次去掉了員工所在部門的分組限制)。
在現實的應用中,對於報表的一些統計功能是很有幫助的。
這裡還有一個問題需要補充說明一下,如果我們使用ROLLUP或者CUBE關鍵字,那麼將產生一些小計的行,這些行中被剔除在分組因素之外的欄位將會被設置為NULL,那麼還存在一種情況,比如在作為分組依據的列表中存在可空的行,那麼NULL也會被作為一個分組表示出來,所以這裡我們就不能僅僅通過NULL來判斷是不是小計記錄了。下面的例子展示了這裡說得到的情況。還是我們前面提到的水果例子,如今我們在每種商品後面增加一個“折扣列”(Discount),用於顯示對應商品的折扣,這個數值是可空的,也就是可以通過NULL來表示沒有對應的折扣信息。數據集如下所示:
| FruitName | ProductPlace | Price | Discount |
| Apple | China | $1.1 | 0.8 |
| Apple | Japan | $2.1 | 0.9 |
| Apple | USA | $2.5 | 1.0 |
| Orange | China | $0.8 | NULL |
| Banana | China | $3.1 | NULL |
| Peach | USA | $3.0 | NULL |
如今我們要統計“各種折扣對應有多少種商品,並總計商品的總數。”,那麼我們可以通過如下的SQL語句來完成:
1 2 3 | SELECTCOUNT(*)ASProductCount,Discount FROMT_TEST_FRUITINFO GROUPBYDiscountWITHROLLUP |
好了,運行一下,你會發現數據都正常出來了,按照如上的數據集,結果如下所示:
| ProductCount | Discount |
| 3 | NULL |
| 1 | 0.8 |
| 1 | 0.9 |
| 1 | 1.0 |
| 6 | NULL |
好了,各種折扣的商品數量都出來了,但是在顯示“沒有折扣商品”和“商品小計”的時候判斷上確存在問題,因為存在兩條Discount為Null的記錄。是哪一條呢?通過分析數據我們知道第一條數據(3, Null)應該對應沒有折扣商品的數量,而(6,Null)應該對應所有商品的數量。需要判斷這兩個具有不同意義的Null就需要引入一個聚合函數Grouping。如今我們把語句修改一下,在返回值中使用Grouping函數增加一列返回值,SQL語句如下:
1 2 3 | SELECTCOUNT(*)ASProductCount,Discount,GROUPING(Discount)ASExpr1 FROMT_TEST_FRUITINFO GROUPBYDiscountWITHROLLUP |
這個時候,我們再看看運行的結果:
| ProductCount | Discount | Expr1 |
| 3 | NULL | |
| 1 | 0.8 | |
| 1 | 0.9 | |
| 1 | 1.0 | |
| 6 | NULL | 1 |
對於根據指定欄位Grouping中包含的欄位進行小計的記錄,這裡會標記為1,我們就可以通過這個標記值將小計記錄從判斷那些由於ROLLUP或者CUBE關鍵字產生的行。Grouping(column_name)可以帶一個參數,Grouping就會去判斷對應的欄位值的NULL是否是由ROLLUP或者CUBE產生的特殊NULL值,如果是那麼就在由Grouping聚合函數產生的新列中將值設置為1。注意Grouping只會檢查Column_name對應的NULL來決定是否將值設置為1,而不是完全由此列是否是由ROLLUP或者CUBE關鍵字自動添加來決定的。
2.2 Group By 和 Having, Where ,Order by語句的執行順序:
最後要說明一下的Group By, Having, Where, Order by幾個語句的執行順序。一個SQL語句往往會產生多個臨時視圖,那麼這些關鍵字的執行順序就非常重要了,因為你必須了解這個關鍵字是在對應視圖形成前的欄位進行操作還是對形成的臨時視圖進行操作,這個問題在使用了別名的視圖尤其重要。以上列舉的關鍵字是按照如下順序進行執行的:Where, Group By, Having, Order by。首先where將最原始記錄中不滿足條件的記錄刪除(所以應該在where語句中盡量的將不符合條件的記錄篩選掉,這樣可以減少分組的次數),然後通過Group By關鍵字後面指定的分組條件將篩選得到的視圖進行分組,接著系統根據Having關鍵字後面指定的篩選條件,將分組視圖后不滿足條件的記錄篩選掉,然後按照Order By語句對視圖進行排序,這樣最終的結果就產生了。在這四個關鍵字中,只有在Order By語句中才可以使用最終視圖的列名,如:
1 2 3 4 | SELECTFruitName,ProductPlace,Price,IDASIDE,Discount FROMT_TEST_FRUITINFO WHERE(ProductPlace=N'china') ORDERBYIDE |
這裡只有在ORDER BY語句中才可以使用IDE,其他條件語句中如果需要引用列名則只能使用ID,而不能使用IDE。
基本信息
- 外文名
- GROUP BY
- 術語類別
- 計算機術語
- 作用
- 通過一定的規則將一個數據集劃分成若干個小的區域,然後針對若干個小區域進行數據處理
- 釋義
- 根據一定的規則進行分組