數據緩衝區
數據緩衝區
數據緩衝區是自我管理數據緩衝區內存,通過C語言來實現。
data cache area
自我管理數據緩衝區內存
開發具有高效性、簡單性、可移植性和安全性的代碼
C 程序設計語言定義了兩個標準的內存管理函數:malloc() 和 free()。C 程序員經常使用那些函數在運行時分配緩衝區,以便在函數之間傳遞數據。然而在許多場合下,您無法預先確定緩衝區所需的實際大小,這對於構造複雜的 C 程序來說,可能會導致幾個根本性的問題。在本文中,Xiaoming Zhang 倡導一種自我管理的抽象數據緩衝區。他概括地給出了抽象緩衝區的偽 C 代碼實現,並詳細介紹了採用這種機制的優點。
軟體的規模和複雜性隨時都在增長,從根本上影響了應用程序的體系結構。在許多場合下,將所有功能編碼進軟體的單個部分中是不切實際的。讓獨立的軟體部分相互交互,比如以插件的形式,這樣做的重要性正在變得越來越明顯。要相對容易地實現這種交互,甚至是在不同廠商編寫的軟體部分之間,軟體需要有定義良好的介面。使用諸如 C 這樣的傳統程序設計語言來編寫滿足這種需要的軟體可能是一個挑戰。
考慮到這種挑戰,本文將研究 C 程序設計語言中的數據緩衝區介面,同時著眼於如何改進當前實踐。儘管內存管理看起來可能無足輕重,但是恰當設計的介面能夠產生高效、簡單和可移植的代碼 —— 這其中每個特性都需要進行內存管理才能實現。因而,下一節將概略介紹程序員在採用傳統數據緩衝區管理方案時所面對的各種問題。後面跟著要介紹的是 抽象數據緩衝區方案,並通過偽代碼實現來進行說明,這種方案解決了許多問題;最後要介紹的是一些 代碼片斷,用以演示該解決方案的好處。
傳統實踐和它們帶來的問題
C 程序員經常使用動態分配的緩衝區(通過調用 malloc() / free() 函數)在函數之間傳遞數據。儘管該方法提供了靈活性,但它也帶來了一些性能影響。首先,它要求在需要緩衝區塊的任何地方進行額外的管理工作(分配和釋放內存塊)。如果分配和釋放不能在相同的代碼位置進行,那麼確保在某個內存塊不再需要時,釋放一次(且僅釋放一次)該內存塊是很重要的;否則就可能導致內存泄露或代碼崩潰。其次,必須預先確定緩衝區的大小才能分配該內存塊。然而,您也許會發現,確定數據大小並不總是那麼容易。開發人員經常採用最大數據尺寸的保守估計,而這樣可能導致嚴重的內存資源浪費。
為避免由於多次釋放而導致的可能的內存泄露和代碼崩潰,好的編程實踐要求您明確地預定義負責分配和釋放緩衝區內存的程序部分。然而在實踐中,定義職責會導致其他困難。在傳統方案下,由於在創建緩衝區時必須指定大小,因此 數據提供者(它可能知道它所提供的數據的大小)是用來執行緩衝區分配操作的最佳搭檔。另一方面,用於釋放的最佳搭檔可能是 數據使用者,因為它知道何時不再需要該數據。通常情況下,數據提供者和數據使用者是不相同的。
當數據提供者和數據使用者來自不同的軟體提供商時,進行交互的各方可能採用不同的底層內存管理機制。例如,有些軟體提供商可能選擇自我管理的堆空間,而其他軟體提供商則依賴底層操作系統(OS)來獲得這樣的功能。此外,不同的操作系統可能以不同的方式實現內存管理。例如,PalmOS 提供兩種不同的內存資源:基於堆和基於資料庫。一般來講,不同的內存管理機制具有各自的優點和缺點,因此您可能不希望預先假定某種特定的機制。不同的首選項甚至可能導致相互衝突的代碼編寫習慣。
解決這個問題的三種方法如下:
交互方之一定義用於數據交換的底層內存分配機制。另一方總是使用已公布的介面來分配或釋放緩衝區,從而避免潛在的不一致。這種模型需要雙方都堅持一個可能與軟體基本功能無關的編程約定,而且在一般情況下,這個編程約定可能使代碼更加不可重用。
驅動數據交換的那一方將負責管理操作 —— 當該方充當數據提供者時,這是一個相對適當的方案。然而,當該方充當數據使用者時,事情就變得棘手了。為避免去發現數據大小,數據使用者可以分配一個任意大小的緩衝區。如果該數據緩衝區沒有足夠大,就必須對數據提供者發出多次調用。因此這種方法需要圍繞該交互調用編寫額外的循環代碼,以備多次調用之需。
對於第三種選擇,數據使用者將對管理操作負責。然而在這種情況下,如果另一方是數據提供者,數據使用者必須預先發出一次調用以發現緩衝區大小 —— 從而給另一方施加了更多的負擔,即編寫邏輯代碼來提供關於緩衝區大小的信息,而這可能需要執行耗時的演演算法。而且,這種解決辦法還可能引入嚴重的效率問題:假設函數 a() 從函數 b() 獲得數據,後者反過來又在執行期間從函數 c() 獲得數據。假設發現緩衝區大小和提供實際的數據都需要執行相同的演演算法。
為了從 b() 獲得數據, a() 必須發出兩次調用:一次用於確定緩衝區大小,另一次用於獲得實際數據。對於向 a() 發出的每次調用, b() 都必須對 c() 發出兩次調用。因此,當這個操作結束時, c() 中的演演算法代碼可能已經執行了四次。原則上,該代碼應該僅執行一次。
顯而易見地,這三種解決辦法全都存在局限性,因此傳統緩衝區內存管理方法並不是適合編寫大規模交互軟體代碼的機制。
除了上述困難之外,安全性也證明是傳統方法存在的問題:傳統緩衝區管理方案無法容易地防止惡意用戶刻意改寫數據緩衝區,從而導致程序異常。考慮到所有這一切,設計一個適當的數據緩衝區介面就勢在必行!
從概念上講,數據緩衝區在傳統方案下是由兩個操作創建的:數據緩衝區實體的創建和實際內存的分配。然而事實上,在實際數據變得可用之前,您不需要分配實際的內存 —— 即可以將兩個操作分離開來。
最初可以使用內存塊的一個空鏈表來創建一個抽象緩衝區。抽象數據緩衝區僅在實際數據變得可用時才分配內存。釋放內存也變成了抽象數據緩衝的責任。考慮到所有這些,集中內存管理和數據複製操作就會帶來以下優點:
各方都能通過調用預定義的 API 函數來構造和/或銷毀數據緩衝區。內存使用將保持接近最優狀態,因為緩衝區內存僅在必要時才分配,並且會儘快釋放,從而最小化內存泄露。任何一方都不需要知道底層的內存管理方案,使得軟體高度可移植,同時保證了交互雙方之間的兼容性。由於沒有哪一方需要管理內存,確定緩衝區的大小就變得不必要了(因而也不可能存在前面指出的多次執行問題)。事實證明緩衝區溢出也不可能會發生,因為僅當存在額外數據空間時才會複製數據。
一種簡單的實現
為了表示一個抽象數據緩衝區,需要聲明兩個結構化的數據類型:
清單 1. 聲明兩個結構化的數據類型來表示一個抽象數據緩衝區
| typedef struct BufferBlockHeader_st BufferBlockHeader; struct BufferBlockHeader_st { BufferBlockHeader * pNextBlock;}; struct Buffer_st { long int totalLength; BufferBlockHeader * pFirstBlock; short int startPoint; BufferBlockHeader * pLastBlock; short int ENDPOINT;}; typedef struct Buffer_st Buffer; |
Buffer 包含關於已創建的抽象緩衝區的信息,它還管理內存塊的一個鏈表:
totalLoength 記錄當前存儲在緩衝區中的位元組數。 pFirstBlock 指向該鏈表中的第一個內存塊。 startPoint 記錄第一個內存塊中第一個位元組的偏移位置。 pLostBlock 指向該鏈表的最後一個內存塊。 endPoint 記錄最後一個內存塊中第一個空閑位元組的偏移位置。
您可以向 Buffer 引入一個附加參數,用以指定每個內存塊的大小,並且可以在抽象緩衝區的初始化期間,將該參數設置為一個可取的值。這裡假設使用默認塊大小。
如果分配了的話, BufferBlockHeader 結構中的 pNextBlock 總是指向該鏈表中的下一個內存塊。每個內存塊在分配時都包含一個 BufferBlockHeader 頭,後面跟著一個用於存儲實際數據的緩衝區塊。
圖 1 描述了一個存儲了一些數據的抽象緩衝區。
圖 1. 抽象緩衝區的數據結構
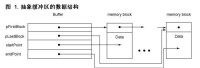
抽象緩衝區的數據結構
在能夠緩衝數據之前,必須通過調用下面的 newBuffer() 函數來顯式地創建抽象緩衝區:
清單 2 使用 newBuffer() 函數創建抽象緩衝區
| Buffer * newBuffer() { allocate a Buffer structure; initialize the structure;} |
在 清單 2 中,該函數分配了包含一個 Buffer 的內存塊,並初始化它的條目以指明它是一個空抽象緩衝區。
相應地,必須在使用抽象緩衝區之後通過調用下面的 freeBuffer() 函數來銷毀它:
清單 3 使用 freeBuffer() 函數來銷毀抽象緩衝區
| void freeBuffer(Buffer * pBuffer ) { while (there is more memory block in the linked list) { free the next memory block; } free the Buffer structure;} |
清單 3 中的函數釋放鏈表中的所有內存塊,然後釋放由 newBuffer() 分配的 Buffer 。
要逐步向抽象緩衝區追加數據段,可使用以下函數:
清單 4. 逐步向抽象緩衝區追加數據段
| long int appendData(Buffer * pBuffer, byte * pInput, long int offset, long int DATALENGTH ) { while (there is more input data) { fill the current memory block; if (there is more input data) { allocate a new memory block and add it into the linked list; } } } |
清單 4 中的函數把存儲在 pInput[offset..offset+dataLength] 中的位元組複製到 pBuffer 所指向的抽象緩衝區中,並在必要時在鏈表中插入新的內存塊,然後返回成功複製到抽象緩衝區中的位元組數目。
採用類似的方式,您可以使用以下函數,逐段地從抽象緩衝區讀取數據段:
清單 5. 從抽象緩衝區讀取數據段
| long int readData(Buffer * pBuffer, byte * pOutput, long int offset, long int arrayLength ) { while (there is something more to read and there is room for output) { read from the first memory block; if (the first memory block is empty) { delete the first memory block from the linked list and free its memory; } }} |
在 清單 5 中,該函數銷毀性地從 pBuffer 所指向的抽象緩衝區最多讀取 arrayLength 個前導位元組,並在內存塊變為空時從鏈表中刪除它們,然後返回成功讀取的位元組數目。
如果需要,您可以實現一個類似 readData() 的函數來允許非銷毀性的讀取。
實現一個函數來返回當前存儲在抽象緩衝區中的位元組數目,這樣可能會帶來好處。
清單 6. 返回抽象緩衝區中的位元組數目
| long int bytesAvailable(Buffer * pBuffer ) { return totalLength;} |