樹結構
按分支關係組織數據元素的結構
樹結構是一種非線性存儲結構,存儲的是具有“一對多”關係的數據元素的集合。
樹結構在客觀世界中廣泛存在,如人類社會的族譜和各種社會組織機構都可用樹形象表示。樹在計算機領域中也得到廣泛應用,如在編譯源程序如下時,可用樹表示源源程序如下的語法結構。又如在資料庫系統中,樹型結構也是信息的重要組織形式之一。一切具有層次關係的問題都可用樹來描述。
一棵樹(tree)是由n(n>0)個元素組成的有限集合,其中:
(1)每個元素稱為結點(node);
(2)有一個特定的結點,稱為根結點或根(root);
(3)除根結點外,其餘結點被分成m(m>=0)個互不相交的有限集合,而每個子集又都是一棵樹(稱為原樹的子樹)
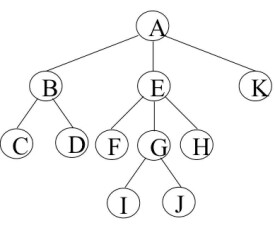
樹的度——也即是寬度,簡單地說,就是結點的分支數。以組成該樹各結點中最大的度作為該樹的度,如上圖的樹,其度為3;樹中度為零的結點稱為葉結點或終端結點。樹中度不為零的結點稱為分枝結點或非終端結點。除根結點外的分枝結點統稱為內部結點。
樹的深度——組成該樹各結點的最大層次,如上圖,其深度為4;
根結點的層次為1,其他結點的層次等於它的父結點的層次數加1.
對於一棵子樹中的任意兩個不同的結點,如果從一個結點出發,按層次自上而下沿著一個個樹枝能到達另一結點,稱它們之間存在著一條路徑。可用路徑所經過的結點序列表示路徑,路徑的長度等於路徑上的結點個數減1.
指若干棵互不相交的樹的集合
設T是一棵樹,表示T的一種最簡單的方法是用一個一維數組存儲每個結點,數組的下標就是結點的位置指針,每個結點中有一個指向各自的父親結點的數組下標的域,這樣可使Parent操作非常方便。類型定義如下:
Type TPosition=integer; {結點的位置類型為整型} NodeType=Record Label:LabelType; {該結點的標號} Parent:TPosition; {該結點的父親的數組下標,對於根結點該域為0} End; TreeType=Record NodeCount:integer; {樹的結點的總數目} Node:Array [1..MaxNodeCount] of NodeType;{存儲樹的結點} End; |
TreeType=Record
由於樹中每個結點的父親是唯一的,所以上述的父親數組表示法可以唯一地表示任何一棵樹。在這種表示法下,尋找一個結點的父結點只需要O(1)時間。在樹中可以從一個結點出發找出一條向上延伸到達其祖先的道路,即從一個結點到其父親,再到其祖父等等。求這樣的道路所需的時間正比於道路上結點的個數。在樹的父親數組表示法中,對於涉及查詢兒子和兄弟信息的樹操作,可能要遍歷整個數組。為了節省查詢時間,可以規定指示兒子的數組下標值大於父親的數組下標值,而指示兄弟結點的數組下標值隨著兄弟的從左到右是遞增的。
樹的另一種常用的表示方法就是兒子鏈表表示法。這種表示法用一個線性表來存儲樹的所有結點信息,稱為結點表。對每個結點建立一個兒子表。兒子表中只存儲兒子結點的地址信息,可以是指針,數組下標甚至內存地址。由於每個結點的兒子數目不定,因此兒子表常用單鏈表來實現,因此這種表示法稱為兒子鏈表表示法。這種實現法與圖的鄰接表表示法類似。下圖是一個兒子鏈表表示法的示意圖。
圖3 樹的兒子鏈表實現
圖3中兒子鏈表結構表示的樹如圖4所示,樹中各結點存放於一個數組實現的表中,數組下標作為各結點的指針。每一個數組元素(即每一個結點)含有一個兒子表,在圖3中兒子表是用單鏈表來實現的,當然也可以用其他表的實現方式來實現兒子表,比如說游標方式(靜態鏈表)。但由於每個結點的兒子數目不確定,所以一般不用數組來實現兒子表,但可以用數組來實現結點表,就如圖3所示。在圖3中可以看到,位於結點表第一個位置的結點(未必是根結點)有兩個兒子結點,從左到右的兩個兒子結點分別位於結點表的第2和第3個位置。因為圖3中的結點表用數組實現,所以結點的標號就是結點在結點表中的數組下標。如圖4所示。
圖4 圖3中兒子鏈表所表示的樹
為了指明樹的根結點的位置,我們可以用一個變數Root記錄根結點在結點表中的位置。有了根結點的位置,就可以利用兒子表依次找到樹中所有的結點。
兒子鏈表表示的樹的類型定義如下:
Type {====================== NodeListType是一個元素為NodeType類型的線性表,其位置類型為TPosition, NodeListType定義了結點表的類型; ChildrenListType是一個元素為TPosition類型的線性表, ChildrenListType定義了兒子表的類型 =======================} TPosition=.... ChildrenListType=... NodeType=Record {結點的類型} Label:LabelType; {結點的標號} Children:ChildrenListType;{結點的兒子表} End; NodeListType=... TreeType=record root:TPosition; {記錄樹根在結點表中的位置} Node:NodeListType; {結點表} end; |
其中NodeListType是一個元素為NodeType類型的線性表,其位置類型為TPosition,NodeListType定義了結點表的類型;ChildrenListType是一個元素為TPosition類型的線性表, ChildrenListType定義了兒子表的類型。以上類型定義並不考慮表的具體實現方式,如果假設結點表和兒子表都用單鏈表實現,則類型定義可以具體實現如下:
{兒子鏈表實現樹的類型定義的一個具體實例,結點表和兒子表都用單鏈表實現} Type TPosition=^NodeType; {結點表的位置類型} ChildrenNodeType=record {兒子表的結點項的類型} child:TPosition; {指向兒子結點的位置指針} next:^ChildrenNodeType; {指向下一個兒子表項的指針} end; NodeType=Record {結點的類型定義為單鏈表} Label:LabelType; {結點的標號} Children:^ChildrenNodeType;{指向兒子表的指針} Next:TPosition; End; TreeType=^NodeType; {樹的類型定義為結點指針類型} |
注意以上的定義只是一種具體情況,實際應用中結點表和兒子表可能用數組、鏈表等任何一種表的實現方式實現。
樹的左兒子右兄弟表示法又稱為 二叉樹表示法或 二叉鏈表表示法。每個結點除了data域外,還含有兩個域,分別指向該結點的最左兒子和右鄰兄弟。這種表示法常用二叉鏈表實現,因此又稱為 二叉鏈表表示法。但是實際應用中常用游標(靜態鏈表)來代替鏈表,請參見表的游標實現。
若用指針實現,其類型定義為:
Type TPosition=^NodeType; NodeType=record Label:LabelType; Leftmost_Child,Right_Sibling:TPosition; end; TreeType=TPosition; |
若用游標實現,其類型定義為:
Type TPosition=integer; NodeType=record Label:LabelType; Leftmost_Child,Right_Sibling:TPosition; end; CellspaceType=array [1..MaxNodeCount] of NodeType; TreeType=TPosition; var Cellspace:CellspaceType; Tree:TreeType; |
此時樹類型TreeType是整數類型,它指示樹根在cellspace中的游標。例如圖5(a)中樹的左兒子右兄弟表示法的指針和游標實現分別如圖5(b)和(c)所示。
(a)
(b)
(c)
圖5 樹的左兒子右兄弟表示法
用樹的左兒子右兄弟表示法可以直接實現樹的大部分操作,只有在對樹結點作Parent操作時需遍歷樹。如果要反覆執行Parent操作,可在結點記錄中再開闢一個指向父結點的指針域,也可以利用最右兒子單元中的Right_Sibling作為指向父結點的指針(否則這裡總是空指針)。當執行Parent(v)時,可以先通過Right_Sibling逐步找出結點v的最右兄弟,再通過最右兄弟的Right_Sibling(父親指針)找到父結點。這個結點就是結點v的父親。在這樣的表示法下,求一個結點的父親所需要的時間正比於該結點右邊的兄弟個數。不過,這時每個記錄中需要多用一位(bit)空間,用以標明該記錄中的right_sibling是指向右鄰兄弟還是指向父親。
考慮到對於現在的計算機,內存已經不是很重要的限制因素了。我們下面就採取增加一個parent域的方案,以改進左兒子右兄弟表示法中Parent操作的效率。因此重新定義樹的類型如下:
若用指針實現,其類型定義為:
Type TPosition=^NodeType; NodeType=record Label:LabelType; Parent,Leftmost_Child,Right_Sibling:TPosition; {增加一個Parent域} end; TreeType=TPosition; var Tree:TreeType; |
若用游標實現,其類型定義為:
Type TPosition=integer; NodeType=record Label:LabelType; Parent,Leftmost_Child,Right_Sibling:TPosition; {增加一個Parent域} end; CellspaceType=array [1..MaxNodeCount] of NodeType; TreeType=TPosition; var Cellspace:CellspaceType; Tree:TreeType; |
樹的遍歷是樹的一種重要的運算。所謂遍歷是指對樹中所有結點的系統的訪問,即依次對樹中每個結點訪問一次且僅訪問一次。樹的3種最重要的遍歷方式分別稱為前序遍歷、中序遍歷和後序遍歷。以這3種方式遍歷一棵樹時,若按訪問結點的先後次序將結點排列起來,就可分別得到樹中所有結點的前序列表,中序列表和後序列表。相應的結點次序分別稱為結點的前序、中序和後序。
樹的這3種遍歷方式可遞歸地定義如下:
§ 如果T是一棵空樹,那麼對T進行前序遍歷、中序遍歷和後序遍歷都是空操作,得到的列表為空表。
§ 如果T是一棵單結點樹,那麼對T進行前序遍歷、中序遍歷和後序遍歷都只訪問這個結點。這個結點本身就是要得到的相應列表。
§ 否則,設T如圖6所示,它以n為樹根,樹根的子樹從左到右依次為T1,T2,..,Tk,那麼有:
§ 對T進行前序遍歷是先訪問樹根n,然後依次前序遍歷T1,T2,..,Tk。
§ 對T進行中序遍歷是先中序遍歷T1,然後訪問樹根n,接著依次對T2,T2,..,Tk進行中序遍歷。
§ 對T進行後序遍歷是先依次對T1,T2,..,Tk進行後序遍歷,最後訪問樹根n。
排序是一種十分重要的運算。所謂排序就是把一堆雜亂無章的元素按照某種次序排列起來,形成一個線性有序的序列。二叉排序樹是利用二叉樹的結構特點來實現對元素排序的。
一、二叉排序樹的定義
二叉排序樹或者是空樹,或者是具有如下性質的二叉樹:
1、左子樹上所有結點的數據值均小於根結點的數據值;
2、右子樹上所有結點的數據值均大於或等於根結點的數據值;
3、左子樹、右子樹本身又各是一棵二叉排序樹。
由此可見,二叉排序樹是一種特殊結構的二叉樹。(18(10(3,15(12,15)),21(20,21(,37))))就是一棵二叉排序樹。
二、二叉排序樹的構造
二叉排序樹的構造過程實質上就是排序的過程,它是二叉排序樹作媒介,將一個任意的數據序列變成一個有序序列。二叉排序樹的構造一般是採用陸續插入結點的辦法逐步構成的。具體構造的思路是:
1、以待排序的數據的第一個數據構成根結點;
2、對以後的各個數據,逐個插入結點,而且規定:在插入過程的每一步,原有樹結點位置不再變動,只是將新數據的結點作為一個葉子結點插入到合適的位置,使樹中任何結點的數據與其左、右子樹結點數據之間的關係仍然符合對二叉排序樹的要求。
一、哈夫曼樹的含義:哈夫曼樹是一種帶權路徑長度最短的樹。
所謂路徑長度就是某個端結點到樹的根結點的距離,等於該端結點的祖先數,或該結點所在層數減1,用lk表示。二叉樹中每個端結點對應的一個實數稱為該結點的權,用Wk表示。我們定義各端結點的權Wk與相應的路徑程度lk乘積的代數和為該二叉樹的帶權路徑長度,用WPL表示,即:
可以證明,哈夫曼樹是最優二叉樹。如給定權值{5,4,7,2,3},可以生成很多棵二叉樹,其中的(A(B(7,5),C(4,D(3,2))))是哈夫曼樹。
二、哈夫曼樹的構造
1、哈夫曼演演算法:
(1)根據給定的n個權值{W1,W2,…,Wn}構成n棵二叉樹的森林:F{T1,T2,…,Tn}。其中每棵二叉樹Ti只有一個帶權為Wi的根結點,其左右子樹為空。
(2)在F中選取兩棵結點的權值最小的樹作為左右子樹構成一棵新的二叉樹,且置新的二叉樹的根結點的權值為其左右子樹上根結點的權值之和。
(3)在F中刪除這兩棵樹,同時,將新得到的二叉樹加入F中。
(4)重複(2)、(3),直到F只含一棵樹為止。最後的這棵樹便是哈夫曼樹。
2、演演算法描述
為了上述演演算法,選用數組型的鏈表作為存儲結構,其類型設計如下:
Type tnode=RECORD
weight:real;
Lc,Rc:integer;
END;
tree=ARRAY[1..2*n-1] of tnode;
node=RECORD
weight:real;
adr:integer;
END;
A=ARRAY[1..n] of node;
下面是在這個存儲結構上實現的構造哈夫曼樹的演演算法:
Procedure Huffmantree(VAR W:ARRAY[1..n]OF real;VAR TR:tree);
VAR AT:A;
BENGIN
FOR i:=1 TO n DO{實現第(1)步}
BEGIN
TR[i].weight:=W[i];{將權值放在樹葉中}
TR[i].Lc:=0;
TR[i].Rc:=0;
AT[i].weight:=TR[i].weight;{用AT存放當前森林的根}
AT[i].adr:=i;
END;
num:=n;{森林中結點個數}
K:=num+1;{形成的新結點在TR數組中的位置}
WHILE (num>=2) DO {重複實現第(2)、(3)步}
BEGIN
SORTING(AT,num);{按根值大小對森林中的樹進行升序排列}
TR[k].weight:=AT[1].weight+AT[2].weight;
{選擇兩棵結點權值最小的樹構造新二叉樹}
TR[k].Lc:=AT[1].adr; {左子樹:權值最小的樹}
TR[k].Rc:=AT[2].adr; {右子樹:權值次小的樹}
AT[1].weight:=TR[k].weight; {新樹賦予第一}
AT[1].adr:=k; {新樹結點標號}
AT[2].weight:=AT[num].weight;{原最後樹賦予第二}
AT[2].adr:=AT[num].adr; {跟進結點標號}
num:=num-1; {刪除原最後樹}
k:=k+1; {增加結點標號}
END;
END;
三、應用:哈夫曼編碼
利用哈夫曼樹構造的用於通信的二進位編碼,稱為哈夫曼編碼。
例如,有一段電文‘CAST TAT A SA’,統計電文中字母的頻度,f('C')=1,f('S')=2,f('T')=3,f(' ')=3,f('A')=4,可用其頻度{1,2,3,3,4}為權值生成Huffman樹,並在每個葉子上註明對應的字元。樹中從根到每個葉子都有一條路徑,若對路徑上的各分支進行約定,指向左子樹根的分支用“0”碼錶示,指向右子樹根的分支用“1”碼錶示,再取每條路徑上的“0”或“1”的序列作為與各個葉子對應的字元的編碼,這就是哈夫曼編碼。
二叉樹是一類非常重要的樹形結構,它可以遞歸地定義如下:
二叉樹T是有限個結點的集合,它或者是空集,或者由一個根結點u以及分別稱為左子樹和右子樹的兩棵互不相交的二叉樹u(1)和u(2)組成。若用n,n1和n2分別表示T,u(1)和u(2)的結點數,則有n=1+n1+n2 。u(1)和u(2)有時分別稱為T的第一和第二子樹。
因此,二叉樹的根可以有空的左子樹或空的右子樹,或者左、右子樹均為空。
二叉樹具有以下的重要性質:
高度為h≥0的二叉樹至少有h+1個結點;高度不超過h(≥0)的二叉樹至多有2h+1-1個結點;含有n≥1個結點的二叉樹的高度至多為n-1;含有n≥1個結點的二叉樹的高度至少為 logn ,因此其高度為Ω(logn)。詳見二叉樹詞條。