XPath
確定XML文檔中部分位置的語言
XPath即為XML路徑語言,它是一種用來確定XML(標準通用標記語言的子集)文檔中某部分位置的語言。
XPath即為XML路徑語言(XML Path Language),它是一種用來確定XML文檔中某部分位置的語言。
XPath基於XML的樹狀結構,提供在數據結構樹中找尋節點的能力。起初XPath的提出的初衷是將其作為一個通用的、介於XPointer與XSL間的語法模型。但是XPath很快的被開發者採用來當作小型查詢語言。
選取節點XPath使用路徑表達式在XML文檔中選取節點。節點是通過沿著路徑或者step來選取的。
下面在下面的表格中,我們已列出了一些路徑表達式以及表達式的結果:列出了最有用的路徑表達式:
| 表達式 | 描述 |
|---|---|
| nodename | 選取此節點的所有子節點。 |
| / | 從根節點選取。 |
| // | 從匹配選擇的當前節點選擇文檔中的節點,而不考慮它們的位置。 |
| . | 選取當前節點。 |
| .. | 選取當前節點的父節點。 |
| @ | 選取屬性。 |
在下面的表格中,我們已列出了一些路徑表達式以及表達式的結果.
| 路徑表達式 | 結果 |
|---|---|
| bookstore | 選取 bookstore 元素的所有子節點。 |
| /bookstore | 選取根元素 bookstore。 註釋:假如路徑起始於正斜杠( / ),則此路徑始終代表到某元素的絕對路徑! |
| bookstore/book | 選取屬於 bookstore 的子元素的所有 book 元素。 |
| //book | 選取所有 book 子元素,而不管它們在文檔中的位置。 |
| bookstore//book | 選擇屬於 bookstore 元素的後代的所有 book 元素,而不管它們位於 bookstore 之下的什麼位置。 |
| //@lang | 選取名為 lang 的所有屬性。 |
XPath
XPath使用路徑表達式來選取XML文檔中的節點或者節點集。這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似。路徑表達式是從一個XML節點(當前的上下文節點)到另一個節點、或一組節點的書面步驟順序。這些步驟以“/”字元分開,每一步有三個構成成分:
1、軸描述(用最直接的方式接近目標節點)
2、節點測試(用於篩選節點位置和名稱)
3、節點描述(用於篩選節點的屬性和子節點特徵)
一般情況下,我們使用簡寫后的語法。雖然完整的軸描述是一種更加貼近人類語言,利用自然語言的單詞和語法來書寫的描述方式,但是相比之下也更加羅嗦。
下面列出了可用在 XPath 表達式中的運算符:
| 運算符 | 描述 | 實例 | 返回值 |
|---|---|---|---|
| | | 計算兩個節點集 | //book | //cd | 返回所有擁有 book 和 cd 元素的節點集 |
| + | 加法 | 6 + 4 | 10 |
| - | 減法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等於 | price=9.80 | 如果 price 是 9.80,則返回 true。 如果 price 是 9.90,則返回 false。 |
| != | 不等於 | price!=9.80 | 如果 price 是 9.90,則返回 true。 如果 price 是 9.80,則返回 false。 |
| < | 小於 | price<9.80 | 如果 price 是 9.00,則返回 true。 如果 price 是 9.90,則返回 false。 |
| <= | 小於或等於 | price<=9.80 | 如果 price 是 9.00,則返回 true。 如果 price 是 9.90,則返回 false。 |
| > | 大於 | price>9.80 | 如果 price 是 9.90,則返回 true。 如果 price 是 9.80,則返回 false。 |
| >= | 大於或等於 | price>=9.80 | 如果 price 是 9.90,則返回 true。 如果 price 是 9.70,則返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,則返回 true。 如果 price 是 9.50,則返回 false。 |
| and | 與 | price>9.00 and price<9.90 | 如果 price 是 9.80,則返回 true。 如果 price 是 8.50,則返回 false。 |
| mod | 計算除法的餘數 | 5 mod 2 | 1 |
XPath是XSLT標準中的主要元素。如果沒有XPath方面的知識,您就無法創建XSLT文檔。
XPath於1999年11月16日成為W3C標準。
XPath被設計供XSLT、XPointer以及其他XML解析軟體使用。
軸可定義相對於當前節點的節點集。
| 軸名稱 | 結果 |
|---|---|
| ancestor | 選取當前節點的所有先輩(父、祖父等)。 |
| ancestor-or-self | 選取當前節點的所有先輩(父、祖父等)以及當前節點本身。 |
| attribute | 選取當前節點的所有屬性。 |
| child | 選取當前節點的所有子元素。 |
| descendant | 選取當前節點的所有後代元素(子、孫等)。 |
| descendant-or-self | 選取當前節點的所有後代元素(子、孫等)以及當前節點本身。 |
| following | 選取文檔中當前節點的結束標籤之後的所有節點。 |
| namespace | 選取當前節點的所有命名空間節點。 |
| parent | 選取當前節點的父節點。 |
| preceding | 選取文檔中當前節點的開始標籤之前的所有節點。 |
| preceding-sibling | 選取當前節點之前的所有同級節點。 |
| self | 選取當前節點。 |
步(step)包括:
軸(axis)
定義所選節點與當前節點之間的樹關係
節點測試(node-test)
識別某個軸內部的節點
零個或者更多謂語(predicate)
更深入地提煉所選的節點集
步的語法:
軸名稱::節點測試[謂語]
實例
| 例子 | 結果 |
|---|---|
| child::book | 選取所有屬於當前節點的子元素的 book 節點。 |
| attribute::lang | 選取當前節點的 lang 屬性。 |
| child::* | 選取當前節點的所有子元素。 |
| attribute::* | 選取當前節點的所有屬性。 |
| child::text() | 選取當前節點的所有文本子節點。 |
| child::node() | 選取當前節點的所有子節點。 |
| descendant::book | 選取當前節點的所有 book 後代。 |
| ancestor::book | 選擇當前節點的所有 book 先輩。 |
| ancestor-or-self::book | 選取當前節點的所有 book 先輩以及當前節點(如果此節點是 book 節點) |
| child::*/child::price | 選取當前節點的所有 price 孫節點。 |
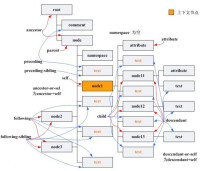
節點(Node)是XPath的術語。在XPath中,有七種類型的節點:元素、屬性、文本、命名空間、處理指令、註釋以及文檔(根)節點。XML文檔是被作為節點樹來對待的。樹的根被稱為文檔節點或者根節點。
父(Parent)
每個元素以及屬性都有一個父。
在下面的例子中,book元素是 title、author、year 以及price元素的父:
子(Children)
元素節點可有零個、一個或多個子。
在下面的例子中,title、author、year以及price元素都是book元素的子:
同胞(Sibling)
擁有相同的父的節點
在下面的例子中,title、author、year 以及 price 元素都是同胞:
先輩(Ancestor)
某節點的父、父的父,等等。
在下面的例子中,title 元素的先輩是 book 元素和 bookstore 元素:
後代(Descendant)
某個節點的子,子的子,等等。
在下面的例子中,bookstore 的後代是 book、title、author、year 以及 price 元素:
名稱說明
fn:node-name(node)返回參數節點的節點名稱。
fn:nilled(node)返回是否拒絕參數節點的布爾值。
fn:data(item.item,...)接受項目序列,並返回原子值序列。
fn:base-uri()
fn:base-uri(node)
返回當前節點或指定節點的base-uri屬性的值。
fn:document-uri(node)返回指定節點的document-uri屬性的值。
在W3C建議下,XPath1.0於1999年11月16日發表。XPath 2.0目前正在W3C審核過程的最終階段。XPath 2.0表達了XPath語言在大小與能力上顯著的增加。
最值得一提的改變是XPath2.0有了更豐富的型別系統;XPath2.0支持不可分割型態,如在XML Schema內建型態定義一樣,並且也可自綱要(schema)導入用戶自定型別。現在每個值都是一個序列(一個單一不可分割值或節點都被視為長度一的序列)。XPath1.0節點組被節點序列取代,它可以是任何順序。
為了支持更豐富的型別組,XPath2.0提供相當延展的函式與操作子群。
XPath2.0實際上是XQuery1.0的子集合。它提供了一個for表達式。該式是XQuery里“FLWOR”表達式的縮減版。利用列出XQuery省去的部分來描述該語言是可能的。主要範例是查詢前導語(query prolog)、元素和屬性建構式、“FLWOR”語法的余項式、以及typeswitch表達式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | ISO-8859-1"?> |

基本信息
- 中文名
- 可擴展標記語言路徑語言
- 外文名
- XPath
- 英文全稱
- Xml Path Language
- 釋義
- 確定XML文檔中某部分位置的語言
- 基於
- XML的樹狀結構
- 用途
- 查詢語言