Treap
數據結構中的二叉搜索樹
樹堆,在數據結構中也稱Treap,是指有一個隨機附加域滿足堆的性質的二叉搜索樹,其結構相當於以隨機數據插入的二叉搜索樹。其基本操作的期望時間複雜度為O(logn)。相對於其他的平衡二叉搜索樹,Treap的特點是實現簡單,且能基本實現隨機平衡的結構。
我們可以看到,如果一個二叉排序樹節點插入的順序是隨機的,這樣我們得到的二叉排序樹大多數情況下是平衡的,即使存在一些極端情況,但是這種情況發生的概率很小,所以我們可以這樣建立一顆二叉排序樹,而不必要像AVL那樣旋轉,可以證明隨機順序建立的二叉排序樹在期望高度是O(logn),但是某些時候我們並不能得知所有的帶插入節點,打亂以後再插入。所以我們需要一種規則來實現這種想法,並且不必要所有節點。也就是說節點是順序輸入的,我們實現這一點可以用Treap。
Treap=Tree+Heap
Treap是一棵二叉排序樹,它的左子樹和右子樹分別是一個Treap,和一般的二叉排序樹不同的是,Treap紀錄一個額外的數據,就是優先順序。Treap在以關鍵碼構成二叉排序樹的同時,還滿足堆的性質(在這裡我們假設節點的優先順序大於該節點的孩子的優先順序)。但是這裡要注意的是Treap和二叉堆有一點不同,就是二叉堆必須是完全二叉樹,而Treap可以並不一定是。
Treap維護堆性質的方法用到了旋轉,這裡先簡單地介紹一下。Treap只需要兩種旋轉,這樣編程複雜度比Splay等就要小一些,這正是Treap的特色之一。
旋轉是這樣的:

treap旋轉
給節點隨機分配一個優先順序,先和二叉排序樹的插入一樣,先把要插入的點插入到一個葉子上,然後跟維護堆一樣,如果當前節點的優先順序比根大就旋轉,如果當前節點是根的左兒子就右旋如果當前節點是根的右兒子就左旋。
我們如果把插入寫成遞歸形式的話,只需要在遞歸調用完成後判斷是否滿足堆性質,如果不滿足就旋轉,實現非常容易。
由於是旋轉的二叉排序樹,最多進行h次(h是樹的高度),插入的複雜度是log( n )的,在期望情況下,所以它的期望複雜度是 O( log( N ) );
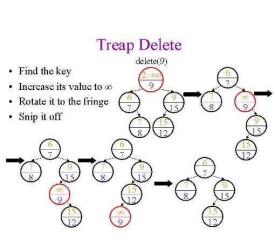
有了旋轉的操作之後,Treap的刪除比二叉排序樹還要簡單。因為Treap滿足堆性質,所以我們只需要把要刪除的節點旋轉到葉節點上,然後直接刪除就可以了。具體的方法就是每次找到優先順序最大的兒子,向與其相反的方向旋轉,直到那個節點被旋轉到葉節點,然後直接刪除。刪除最多進行log( n )次旋轉,期望複雜度是log( n )。
第二種刪除方法:為保證效率,可以用普通二叉查找樹的刪除方法,找到節點的中序前綴,然後替換,刪除,並使用非遞歸。雖然時間複雜度仍為log級別,但常數因子小了很多。
Pascal代碼:
查找
和一般的二叉排序樹一樣,但是由於Treap的隨機化結構,可以證明Treap中查找的期望複雜度是log( n )。
分離
要把一個Treap按大小分成兩個Treap,只要在需要分開的位置加一個虛擬節點,然後旋至根節點刪除,左右兩個子樹就是得出的兩個Treap了。根據二叉排序樹的性質,這時左子樹的所有節點都小於右子樹的節點。
時間相當於一次插入操作的複雜度,也就是 log( n )
合併
合併是指把兩個Treap合併成一個Treap,其中第一個Treap的所有節點都必須小於或等於第二個Treap中的所有節點,也就是分離的結果所要滿足的條件。合併的過程和分離相反,只要加一個虛擬的根,把兩棵樹分別作為左右子樹,然後把根刪除就可以了。
時間複雜度和刪除一樣,也是期望
旋轉
旋轉就是把random出來的值進行維護堆得性質的操作。因為BST得特殊性質,所以在旋轉時,還要維護BST的性質。
演演算法分析
首先我們注意到二叉排序樹有一個特性,就是每個子樹的形態在優先順序唯一確定的情況下都是唯一的,不受其他因素影響,也就是說,左子樹的形態與樹中大於根節點的值無關,右子樹亦然。
這是因為Treap滿足堆的性質,Treap的根節點是優先順序最大的那個節點,考慮它的左子樹,樹根也是子樹裡面最大的一點,右子樹亦然。所以Treap相當於先把所有節點按照優先順序排序,然後插入,實質上就相當於以隨機順序建立的二叉排序樹,只不過它並不需要一次讀入所有數據,可以一個一個地插入。而當這個隨機順序確定的時候,這個樹是唯一的。
因此在給定優先順序的情況下,只要是用符合要求的操作,通過任何方式得出的Treap都是一樣的,所以不改變優先順序的情況下,特殊的操作不會造成Treap結構的退化。而改變優先順序可能會使Treap變得不夠隨機以致退化。
證明隨機建立二叉排序樹的大家可以參見CLRS P265 12.4 Randomly built binary search trees,這裡略去。
模板
支持以下操作
1. 插入x數
2. 刪除x數(若有多個相同的數,應只刪除一個)
3. 查詢x數的排名(若有多個相同的數,應輸出最小的排名)
4. 查詢排名為x的數
5. 求x的前驅(前驅定義為小於x,且最大的數)
6. 求x的後繼(後繼定義為大於x,且最小的數)
基本信息
- 外文名
- Tree heap
- 性質
- 自平衡二叉查找樹