後綴數組
後綴數組
在字元串處理當中,後綴樹和後綴數組都是非常有力的工具。其實後綴數組是後綴樹的一個非常精巧的替代品,它比後綴樹容易編程實現,能夠實現後綴樹的很多功能而時間複雜度也不太遜色,並且,它比後綴樹所佔用的空間小很多。可以說,在信息學競賽中後綴數組比後綴樹要更為實用。
字元串 S 的子串 r[i,j] , i ≤ j ,表示 r 串中從 i 到 j 這一段,就是順次排列 r[i],r[i+1],...,r[j] 形成的字元串。
後綴是指從某個位置 i 開始到整個串末尾結束的一個特殊子串。字元串 r 的從 第 i 個字元開始的後綴表示為 Suffix(i) ,也就是Suffix(i)=r[i,len(r)] 。
大小比較:關於字元串的大小比較,是指通常所說的“字典順序”比較,也就是對於兩個字元串u、v,令i 從1 開始順次比較u[i]和v[i],如果u[i]=v[i]則令 i 加1,否則若u[i]v[i]則認為u>v(也就是vlen(u)或者i>len(v)仍比較不出結果,那麼若len(u)len(v)則u>v。
從字元串的大小比較的定義來看,S 的兩個開頭位置不同的後綴u 和v 進行比較的結果不可能是相等,因為u=v 的必要條件len(u)=len(v)在這裡不可能滿足。
後綴數組 SA 是一個一維數組,它保存從 1 到 n 的某個排列 SA[1 ] ,SA[2] , …… , SA[n] ,並且保證suffix(SA[i]) < Suffix(SA[i+1]) , 1 ≤ i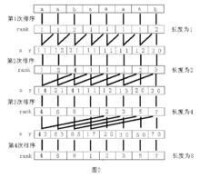 名次數組 Rank[i] 保存的是 Suffix(i) 在所有後綴中從小到大排列的“名次”。簡單的說,後綴數組(SA)是“排第幾的是誰? ” ,名次數組(RANK)是“你排第幾? ” 。容易看出,後綴數組和名次數組為互逆運算。如圖1 所示。
名次數組 Rank[i] 保存的是 Suffix(i) 在所有後綴中從小到大排列的“名次”。簡單的說,後綴數組(SA)是“排第幾的是誰? ” ,名次數組(RANK)是“你排第幾? ” 。容易看出,後綴數組和名次數組為互逆運算。如圖1 所示。
後綴數組SA與名次數組Rank的對應關係
設字元串的長度為 n 。為了方便比較大小,可以在字元串後面添加一個字元,這個字元沒有在前面的字元中出現過,而且比前面的字元都要小。在求出名次數組后,可以僅用 O(1) 的時間比較任意兩個後綴的大小。在求出後綴數組或名次數組中的其中一個以後,便可以用 O(n) 的時間求出另外一個。任意兩個後綴如果直接比較大小,最多需要比較字元 n 次,也就是說最遲在比較第 n 個字元時一定能分出“勝負” 。
• 主要思路
如何構造後綴數組呢?最直接最簡單的方法當然是把S的後綴都看作一些普通的字元串,按照一般字元串排序的方法對它們從小到大進行排序。
不難看出,這種做法是很笨拙的,因為它沒有利用到各個後綴之間的有機聯繫,所以它的效率不可能很高。即使採用字元串排序中比較高效的Multi-key Quick Sort,最壞情況的時間複雜度仍然是O(n )的,不能滿足我們的需要。
下面介紹倍增演演算法(Doubling Algorithm),它正是充分利用了各個後綴之間的聯繫,將構造後綴數組的最壞時間複雜度成功降至O(nlogn)。
對一個字元串u,我們定義u的k-前綴
定義k-前綴比較關係
設兩個字元串u和v,
u
u =k v當且僅當uk=vk;
u ≤k v當且僅當uk ≤ vk。
直觀地看這些加了一個下標k的比較符號的意義就是對兩個字元串的前k個字元進行字典序比較,特別的一點就是在作大於和小於的比較時如果某個字元串的長度不到k也沒有關係,只要能夠在k個字元比較結束之前得到第一個字元串大於或者小於第二個字元串就可以了。
根據前綴比較符的性質我們可以得到以下的非常重要的性質(下面三個性質均在1≤i,j≤n時成立):
性質1.1 對於任意一常數k≥n,Suffix(i)
性質1.2 Suffix(i)=2kSuffix(j)等價於Suffix(i)=kSuffix(j) 且 Suffix(i+k)=kSuffix(j+k)。
性質1.3 Suffix(i)<2kSuffix(j) 等價於Suffix(i)
註:kSuffix(i)表示Suffix(i)的k-前綴。
這裡有一個問題,當i+k>n或者j+k>n的時候Suffix(i+k)或Suffix(j+k)是無明確定義的表達式,但實際上不需要考慮這個問題,因為此時Suffix(i)或者Suffix(j)的長度不超過k,也就是說它們的k-前綴以'$'結尾,於是k-前綴比較的結果不可能相等,也就是說前k個字元已經能夠比出大小,後面的表達式自然可以忽略,這也就看出我們規定S以'$'結尾的特殊用處了。
定義k-後綴數組SAk保存從 i 到 j的某個排列SAk[1],SAk[2],…SAk[n]使得Suffix(SA[]) ≤kSuffix(SAk[i+1]),1≤i
定義k-名次數組Rankk,Rankk代表Suffix(i)在k-前綴關係下從小到大的“名次”,也就是1加上滿足Suffix(j)
假設我們已經求出了SAk和Rankk,那麼我們可以很方便地求出SA2k和Rank2k,因為根據性質1.2和1.3,2k-前綴比較關係可以由常數個k-前綴比較關係組合起來等價地表達,而Rankk數組實際上給出了在常數時間內進行
Suffix(i)
Suffix(i)=kSuffix(j)當且僅當Rankk[i]=Rankk[j]
因此,比較Suffix(i)和Suffix(j)在k-前綴比較關係下的大小可以在常數時間內完成,於是對所有的後綴在≤k關係下進行排序也就和一般的排序沒有什麼區別了,它實際上就相當於每個Suffix(i)有一個主關鍵字Rankk[i]和一個次關鍵字Rankk[i+k]。如果採用快速排序之類O(nlogn)的排序,那麼從SAk和Rankk構造出SA2k的複雜度就是O(nlogn)。更聰明的方法是採用基數排序,複雜度為O(n)。
求出SA2k之後就可以在O(n)的時間內根據SA2k構造出Rank2k。因此,從SAk和Rankk推出SA2k和Rank2k可以在O(n)時間內完成。
下面只有一個問題需要解決:如何構造出SA1和Rank1。這個問題非常簡單:因為<1,=1和≤1這些運算符實際上就是對字元串的第一個字元進行比較,所以只要把每個後綴按照它的第一個字元進行排序就可以求出SA1,不妨就採用快速排序,複雜度為O(nlogn)。
於是,可以在O(nlogn)的時間內求出SA1和Rank1。
求出了SA1和Rank1,我們可以在O(n)的時間內求出SA2和Rank2,同樣,我們可以再用O(n)的時間求出SA4和Rank4,這樣,我們依次求出:
SA2和Rank2,SA4和Rank4,SA8和Rank8,……直到SAm和Rankm,其中m=2k且m≥n。而根據性質1.1,SAm和SA是等價的。這樣一共需要進行logn次O(n)的過程,因此可以在O(nlogn)的時間內計算出後綴數組SA和名次數組Rank。
• 具體實現
待排序的字元串放在 r 數組中,從 r[0] 到 r[n-1] ,長度為 n ,且最大值小於 m 。為了函數操作的方便,約定除 r[n-1] 外所有的 r[i] 都大於 0, r[n-1]=0 。函數結束后,結果放在 sa 數組中,從 sa[0] 到 sa[n-1] 。
函數的第一步,要對長度為 1 的字元串進行排序。一般來說,在字元串的 題目中, r 的最大值不會很大,所以這裡使用了計數排序。如果 r 的最大值很大,那麼把這段代碼改成快速排序。代碼:
這裡 x 數組保存的值相當於是 rank 值。下面的操作只是用 x 數組來比較字元的大小,所以沒有必要求出當前真實的 rank 值。
接下來進行若干次基數排序,在實現的時候,這裡有一個小優化。基數排 序要分兩次,第一次是對第二關鍵字排序,第二次是對第一關鍵字排序。對第二 關鍵字排序的結果實際上可以利用上一次求得的 sa 直接算出,沒有必要再算一次。代碼:
其中變數 j 是當前字元串的長度,數組 y 保存的是對第二關鍵字排序的結 果。然後要對第一關鍵字進行排序,代碼:
這樣便求出了新的 sa 值。在求出 sa 后,下一步是計算 rank 值。這裡要注意的是,可能有多個字元串的 rank 值是相同的,所以必須比較兩個字元串是否完全相同, y 數組的值已經沒有必要保存,為了節省空間,這裡用 y 數組保存 r ank值。這裡又有一個小優化,將 x 和 y 定義為指針類型,複製整個數組的操作可 以用交換指針的值代替,不必將數組中值一個一個的複製。代碼:
其中 cmp 函數的代碼是:
這裡可以看到規定 r[n-1]=0 的好處,如果 r[a]=r[b] ,說明以 r[a] 或 r[b ]開頭的長度為 l 的字元串肯定不包括字元 r[n-1] ,所以調用變數 r[a+l] 和 r[b +l]不會導致數組下標越界,這樣就不需要做特殊判斷。執行完上面的代碼后, ran k值保存在 x 數組中,而變數 p 的結果實際上就是不同的字元串的個數。這裡可 以加一個小優化,如果 p 等於 n ,那麼函數可以結束。因為在當前長度的字元串 中,已經沒有相同的字元串,接下來的排序不會改變 rank 值。例如圖 1 中的第四次排序,實際上是沒有必要的。對上面的兩段代碼,循 環的初始賦值和終止條件 可以這樣寫:
在第一次的排序以後, rank 數組中的最大值小於 p ,所以讓 m=p 。
整個倍增演演算法基本寫好,代碼大約 25 行。
• 演演算法分析
倍增演演算法的時間複雜度比較容易分析。每次基數排序的時間複雜度為 O(n) ,
排序的次數決定於最長公共子串的長度,最壞情況下,排序次數為 logn 次,所
以總的時間複雜度為 O(nlogn) 。
• 主要思路
DC3 演演算法分 3 步:
(1)、先將後綴分成兩部分,然後對第一部分的後綴排序。
將後綴分成兩部分,第一部分是後綴 k ( k 模 3 不等於 0 ),第二部分是后 綴k ( k 模 3 等於 0 )。先對所有起始位置模 3 不等於 0 的後綴進行排序,即對suffix(1), suffix(2), suffix(4), suffix(5), suffix(7) …… 進行排序。做法是將 suffix(1) 和 suffix(2) 連接,如果這兩個後綴的長度不是 3 的倍數,那先各自在末尾添 0 使得長度都變成 3 的倍數。然後每 3 個字元為一組,進行基 數排序,將每組字元“合併”成一個新的字元。然後用遞歸的方法求這個新的字 符串的後綴數組。在得到新的字元串的 sa 后,便可以計算原字元串所有起始位置模 3 不等於 0 的後綴的 sa 。要注意的是,原字元串必須以一個最小的且前面沒有出現過的字元結尾,這樣才能保證結果正確。
(2)、利用( 1 )的結果,對第二部分的後綴排序。
剩下的後綴是起始位置模 3 等於 0 的後綴,而這些後綴都可以看成是一個 字元加上一個在( 1 )中已經求出 rank 的後綴,所以只要一次基數排序便可以求 出剩下的後綴的 sa 。
(3)、將(1)和(2)的結果合併,即完成對所有後綴排序。
這個合併操作跟合併排序中的合併操作一樣。每次需要比較兩個後綴的大小。分兩種情況考慮,第一種情況是suffix(3*i)和suffix(3*j+1)的比較,可以把suffix(3*i)和suffix(3*j+1)表示成:
suffix(3*i) = r[3*i] +suffix(3*i+1)
suffix(3*j+1)= r[3*j+1]+suffix(3*j+2)
其中suffix(3*i+1)和suffix(3*j+2)的比較可以利用(2)的結果快速得到。
第二種情況是suffix(3*i)和suffix(3*j+2)的比較,可以把suffix(3*i)和suffix(3*j+2)表示成:
suffix(3*i) =r[3*i] +r[3*i+1]+ suffix(3*i+2)
suffix(3*j+2)=r[3*j+2]+r[3*j+3]+ suffix(3*(j+1)+1)
同樣的道理,suffix(3*i+2)和suffix(3*(j+1)+1) 的比較可以利用(2)的結果快速得到。所以每次的比較都可以高效的完成,這也是之前要每3個字元合併,而不是每2個字元合併的原因。
• 具體實現
各個參數的作用和前面的倍增演演算法一樣,不同的地方是r數組和sa數組的
大小都要是3*n,這為了方便下面的遞歸處理,不用每次都申請新的內存空間。
函數中用到的變數:
rn數組保存的是(1)中要遞歸處理的新字元串,san數組是新字元串的sa。
變數ta表示起始位置模3為0的後綴個數,變數tb表示起始位置模3為1的後綴個數,已經直接算出。變數tbc表示起始位置模3為1或2的後綴個數。先按
(1)中所說的用基數排序把3個字元“合併”成一個新的字元。為了方便操作,
先將r[n]和r[n+1]賦值為0。
代碼:
其中sort函數的作用是進行基數排序。代碼:
基數排序結束后,新的字元的排名保存在wb數組中。
跟倍增演演算法一樣,在基數排序以後,求新的字元串時要判斷兩個字元組是否
完全相同。代碼:
其中F(x)是計算出原字元串的suffix(x)在新的字元串中的起始位置。代碼:
c0函數是比較是否完全相同,在開頭加一段代碼:
接下來是遞歸處理新的字元串,這裡和倍增演演算法一樣,可以加一個小優化:如果p等於tbc,那麼說明在新的字元串中沒有相同的字元,這樣可以直接求出san數組,並不用遞歸處理。代碼:
然後是第(2)步,將所有起始位置模3等於0的後綴進行排序。其中對第二關鍵字的排序結果可以由新字元串的sa直接計算得到,沒有必要再排一次。
代碼:
要注意的是,如果n%3==1,要特殊處理suffix(n-1),因為在san數組裡並沒有suffix(n)。G(x)是計算新字元串的suffix(x)在原字元串中的位置,和F(x)為互逆運算。在開頭加一段:
最後是第(3)步,合併所有後綴的排序結果,保存在sa數組中。代碼:
其中c12函數是按(3)中所說的比較後綴大小的函數,k=1是第一種情況,
k=2是第二種情況。代碼:
整個DC3演演算法基本寫好,代碼大約40行。
• 演演算法分析
假設這個演演算法的時間複雜度為f(n)。容易看出第(1)步排序的時間為O(n)
(一般來說,m比較小,這裡忽略不計),新的字元串的長度不超過2n/3,求新
字元串的sa的時間為f(2n/3),第(2)和第(3)步的時間都是O(n)。所以
f(n)=O(n)+f(2n/3)
f(n)≤c×n+f(2n/3)
f(n)≤c×n+c×(2n/3)+c×(4n/9)+c×(8n/27)+……≤3c×n
所以 f(n)=O(n)
由此看出,DC3演演算法是一個優秀的線性演演算法。
從時間複雜度、空間複雜度、編程複雜度和實際效率等方面對倍增演演算法與DC3演演算法進行比較。
• 時間複雜度
倍增演演算法的時間複雜度為O(nlogn),DC3演演算法的時間複雜度為O(n)。
從常數上看,DC3演演算法的常數要比倍增演演算法大。
• 空間複雜度
倍增演演算法和DC3演演算法的空間複雜度都是O(n)。按前面所講的實現方法,倍
增演演算法所需數組總大小為6n,DC3演演算法所需數組總大小為10n。
對競賽選手來說,一般題目規模在10w這個數量級,所以不需要擔心爆空間什麼的。
• 編程複雜度
倍增演演算法的源程序長度為25行,DC3演演算法的源程序長度為40行。(PS:我會告訴你縮行了么。。)
• 實際效率
| N | 倍增演演算法 | DC3演演算法 |
| 200000 | 192 | 140 |
| 300000 | 367 | 244 |
| 500000 | 750 | 499 |
| 1000000 | 1693 | 1248 |
測試環境:NOI-linux Pentium(R)4CPU2.80GHz(不包括讀入和輸出的時間,單位:ms)
從表中可以看出,DC3演演算法在實際效率上還是有一定優勢的。倍增演演算法容易實現,DC3演演算法效率比較高,但是實現起來比倍增演演算法複雜一些。對於不同的題目,應當根據數據規模的大小決定使用哪個演演算法。
在NOI(P)和ACM中大家一般會選擇倍增,因為代碼短,好寫好調,而且時間複雜度比DC3高不了多少。。
一個字元串S的後綴數組SA可以在O(nlogn)的時間內計算出來。利用SA我們已經可以做很多事情,比如在O(mlogn)的時間內進行模式匹配,其中m,n分別為模式串和待匹配串的長度。但是要想更充分地發揮後綴數組的威力,我們還需要計算一個輔助的工具——最長公共前綴(Longest Common Prefix)。
對兩個字元串u,v定義函數lcp(u,v)=max{i|u=iv},也就是從頭開始順次比較u和v的對應字元,對應字元持續相等的最大位置,稱為這兩個字元串的最長公共前綴。
對正整數i,j定義LCP(i,j)=lcp(Suffix(SA[i]),Suffix(SA[j])),其中i,j均為1至n的整數。LCP(i,j)也就是後綴數組中第i個和第j個後綴的最長公共前綴的長度。
關於LCP有兩個顯而易見的性質:
性質2.1 LCP(i,j)=LCP(j,i)
性質2.2 LCP(i,i)=len(Suffix(SA[i]))=n-SA[i]+1
這兩個性質的用處在於,我們計算LCP(i,j)時只需要考慮ij時可交換i,j,i=j時可以直接輸出結果n-SA+1。
直接根據定義,用順次比較對應字元的方法來計算LCP(i,j)顯然是很低效的,時間複雜度為O(n),所以我們必須進行適當的預處理以降低每次計算LCP的複雜度。
經過仔細分析,我們發現LCP函數有一個非常好的性質:
設i
要證明LCP Theorem,首先證明LCP Lemma:
對任意1≤i
證明:設p=min{LCP(i,j),LCP(j,k)},則有LCP(i,j)≥p,LCP(j,k)≥p。
設Suffix(SA[i])=u,Suffix(SA[j])=v,Suffix(SA[k])=w。
由p =LCP(i,j) v得u =p v;同理v =p w。
於是Suffix(SA[i]) =p Suffix(SA[k]),即LCP(i,k)≥p。 (1)
又設LCP(i,k)=q>p,則
u[1]=w[1],u[2]=w[2],...u[q]=w[q]。
而min{LCP(i,j),LCP(j,k)}=p說明u[p+1]≠v[p+1]或v[p+1]≠w[q+1],
設u[p+1]=x,v[p+1]=y,w[p+1]=z,顯然有x≤y≤z,又由p
於是,q>p不成立,即LCP(i,k)≤p。 (2)
綜合(1),(2)知 LCP(i,k)=p=min{LCP(i,j),LCP(j,k)},LCP Lemma得證。
於是LCP Theorem可以證明如下:
當j-i=1和j-i=2時,顯然成立。
設j-i=m時LCP Theorem成立,當j-i=m+1時,
由LCP Lemma知LCP(i,j)=min{LCP(i,i+1),LCP(i+1,j)},
因j-(i+1)≤m,LCP(i+1,j)=min{LCP(k-1,k)|i+2≤k≤j},故當j-i=m+1時,仍有
LCP(i,j)=min{LCP(i,i+1),min{LCP(k-1,k)|i+2≤k≤j}}=min{LCP(k-1,k}|i+1≤k≤j)
根據數學歸納法,LCP Theorem成立。
根據LCP Theorem得出必然的一個推論:
LCP Corollary 對i≤j
定義一維數組height,令height[i]=LCP(i-1,i),1
由LCP Theorem,LCP(i,j)=min{height[k]|i+1≤k≤j},也就是說,計算LCP(i,j)等同於詢問一維數組height中下標在i+1到j範圍內的所有元素的最小值。如果height數組是固定的,這就是非常經典的RMQ(Range Minimum Query)問題。
RMQ問題可以用線段樹或靜態排序樹在O(nlogn)時間內進行預處理,之後每次詢問花費時間O(logn),更好的方法是RMQ標準演演算法,可以在O(n)時間內進行預處理,每次詢問可以在常數時間內完成。
對於一個固定的字元串S,其height數組顯然是固定的,只要我們能高效地求出height數組,那麼運用RMQ方法進行預處理之後,每次計算LCP(i,j)的時間複雜度就是常數級了。於是只有一個問題——如何盡量高效地算出height數組。
根據計算後綴數組的經驗,我們不應該把n個後綴看作互不相關的普通字元串,而應該盡量利用它們之間的聯繫,下面證明一個非常有用的性質:
為了描述方便,設h[i]=height[Rank[i]],即height[i]=h[SA[i]]。h數組滿足一個性質:
性質3 對於i>1且Rank[i]>1,一定有h[i]≥h[i-1]-1。
為了證明性質3,我們有必要明確兩個事實:
設i=1,則成立以下兩點:
Fact 1 Suffix(i)
Fact 2 一定有lcp(Suffix(i+1),Suffix(j+1))=lcp(Suffix(i),Suffix(j))-1。
看起來很神奇,但其實很自然:lcp(Suffix(i),Suffix(j))>=1說明Suffix(i)和Suffix(j)的第一個字元是相同的,設它為α,則Suffix(i)相當於α后連接Suffix(i+1),Suffix(j)相當於α后連接Suffix(j+1)。比較Suffix(i)和Suffix(j)時,第一個字元α是一定相等的,於是後面就等價於比較Suffix(i)和Suffix(j),因此Fact 1成立。Fact 2可類似證明。
於是可以證明性質3:
當h[i-1]≤1時,結論顯然成立,因h≥0≥h[i-1]-1。
當h[i-1]>1時,也即height[Rank[i-1]]>1,可見Rank[i-1]>1,因height[1]=0。
令j=i-1,k=SA[Rank[j]-1]。顯然有Suffix(k)
根據h[i-1]=lcp(Suffix(k),Suffix(j))>1和Suffix(k)
由Fact 2知lcp(Suffix(k+1),Suffix(i))=h[i-1]-1。
由Fact 1知Rank[k+1]
於是根據LCP Corollary,有
LCP(Rank[i]-1,Rank[i])≥LCP(Rank[k+1],Rank[i])
=lcp(Suffix(k+1),Suffix(i))
=h[i-1]-1
由於h[i]=height[Rank[i]]=LCP(Rank[i]-1,Rank[i]),最終得到 h[i]≥h[i-1]-1。
根據性質3,可以令i從1循環到n按照如下方法依次算出h[i]:
若Rank[i]=1,則h[i]=0。字元比較次數為0。
若i=1或者h[i-1]≤1,則直接將Suffix(i)和Suffix(Rank-1)從第一個字元開始依次比較直到有字元不相同,由此計算出h[i]。字元比較次數為h[i]+1,不超過h[i]-h[i-1]+2。
否則,說明i>1,Rank[i]>1,h[i-1]>1,根據性質3,Suffix(i)和Suffix(Rank[i]-1)至少有前h[i-1]-1個字元是相同的,於是字元比較可以從h[i-1]開始,直到某個字元不相同,由此計算出h[i]。字元比較次數為h[i]-h[i-1]+2。
不難看出總的字元比較次數不超過3n,也就是說,整個演演算法的複雜度為O(n)。
求出了h數組,根據關係式height[i]=h[SA[i]]可以在O(n)時間內求出height數組,於是
可以在O(n)時間內求出height數組。
結合RMQ方法,在O(n)時間和空間進行預處理之後就能做到在常數時間內計算出對任意(i,j)計算出LCP(i,j)。
因為lcp(Suffix(i),Suffix(j))=LCP(Rank[i],Rank[j]),所以我們也就可以在常數時間內求出S的任何兩個後綴之間的最長公共前綴。這正是後綴數組能強有力地處理很多字元串問題的重要原因之一。
C++代碼
基本信息
- 中文名
- 後綴數組
- 外文名
- Suffix Array
目錄