流水線技術
流水線技術
流水線(pipeline)技術是指在程序執行時多條指令重疊進行操作的一種准并行處理實現技術。流水線是Intel首次在486晶元中開始使用的。在CPU中由5—6個不同功能的電路單元組成一條指令處理流水線,然後將一條指令分成5—6步后再由這些電路單元分別執行,這樣就能實現在一個CPU時鐘周期完成一條指令,因此提高CPU的運算速度。經典奔騰每條整數流水線都分為四級流水,即取指令、解碼、執行、寫回結果,浮點流水又分為八級流水。
借鑒了工業流水線製造的思想,現代CPU也採用了流水線設計。在工業製造中採用流水線可以提高單位時間的生產量;同樣在CPU中採用流水線設計也有助於提高CPU的頻率。
流水線技術
1.衝壓:製作車身外殼和底盤等部件;
2.焊接:將衝壓成形后的各部件焊接成車身;
3.塗裝:將車身等主要部件清洗、化學處理、打磨、噴漆和烘乾;
4.總裝:將各部件(包括發動機和向外採購的零部件)組裝成車;
同時對應地需要衝壓、焊接、塗裝和總裝四個工人。採用流水線的製造方式,同一時刻四輛汽車在裝配。如果不採用流水線,那麼第一輛汽車依次經過上述四個步驟裝配完成之後,下一輛汽車才開始進行裝配,最早期的工業製造就是採用的這種原始的方式。未採用流水線的原始製造方式,同一時刻只有一輛汽車在裝配。
流水線技術
CPU的工作也可以大致分為指令的獲取、解碼、運算和結果的寫入四個步驟,採用流水線設計之後,指令(好比待裝配的汽車)就可以連續不斷地進行處理。在同一個較長的時間段內,顯然擁有流水線設計的CPU能夠處理更多的指令。
流水線技術
功能部件級:在實現較為複雜的運算時採用
指令級:將一條指令執行過程分為多個階段
處理器間級:每個處理器完成其專門的任務。
單功能流水線:只完成一種如乘法或浮點運算等,多用於數字信號處理器(DSP),各處理器可并行完成各自的功能,加快整機處理速度。
流水線技術
靜態流水線:同一時間內,多功能結構只能按一種功能的連接方式工作。
動態流水線:同一時間內,可以有多種功能的連接方式同時工作。
標量流水線:一般數據
向量流水線:矢量數據。X+Y=Z每一個代表一維數據。
線性流水線:指各功能模塊順序串列連接,無反饋迴路,如前面介紹的。
非線性流水線:帶有反饋迴路的流水線。
衡量一種流水線處理方式的性能高低的書面數據主要由吞吐率、效率和加速比這三個參數來決定。
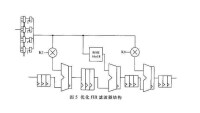
流水線技術
由此,要對於流水線的瓶頸部分的處理主要在於減少流水段的處理時間。實現的方法一般有兩種:
1、把瓶頸部分的流水線分拆,以便任務可以充分流水處理。流水段的處理時間過長,一般是由於任務堵塞造成的,而任務的堵塞會導致流水線不能在同一個時鐘周期內啟動另一個操作,可以把流水段劃分,在各小流水段中間設置緩存寄存器,緩衝上一個流水段的任務,使流水線充分流水。假如X流水段的處理時間為3T,可以把X流水段再細分成3小段,這樣,每小段的功能相同,但是處理時間已經變成3T/3=T了。
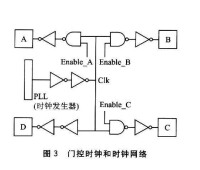
流水線技術
是指某一流水線如果採用串列模式之後所用的時間T0和採用流水線模式后所用時間T的比值,數值越大,說明這條流水線的工作安排方式越好。
使用效率:指流水線中,各個部件的利用率。由於流水線在開始工作時存在建立時間;在結束時存在排空時間,各個部件不可能一直在工作,總有某個部件在某一個時間處於閑置狀態。用處於工作狀態的部件和總部件的比值來說明這條流水線的工作效率。
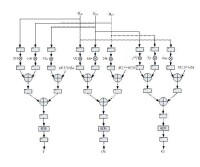
流水線技術
1、多個任務在同一時間周期內爭用同一個流水段。例如,假如在指令流水線中,如果數據和指令是放在同一個儲存器中,並且訪問介面也只有一個,那麼,兩條指令就會爭用儲存器;在一些算數流水線中,有些運算會同時訪問一個運算部件。
2、數據依賴。比如,A運算必須得到B運算的結果,但是,B運算還沒有開始,A運算動作就必須等待,直到B運算完成,兩次運算不能同時執行。
解決方案:
第一種情況,增加運算部件的數量來使他們不必爭用同一個部件;
第二種情況,用指令調度的方法重新安排指令或運算的順序。
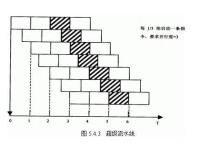
超級流水線(SuperPipeline)又叫做深度流水線,它是提高cpu速度通常採取的一種技術。CPU處理指令是通過Clock來驅動的,每個clock完成一級流水線操作。每個周期所做的操作越少,需要的時間就越短,時間越短,頻率就可以提得越高。超級流水線就是將cpu處理指令是得操作進一步細分,增加流水線級數來提高頻率。頻率高了,當流水線開足馬力運行時平均每個周期完成一條指令(單發射情況下),這樣cpu處理得速度就提高了。當然,這是理想情況下,一般是流水線級數越多,重疊執行的執行就越多,那麼發生競爭衝突得可能性就越大,對流水線性能有一定影響現在很多cpu都是將超標量和超級流水線技術一起使用,例如pentiumIV,流水線達到20級,頻率最快已經超過3GHZ。教科書上用於教學的經典MIPS只有5級流水。
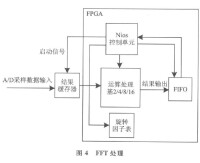
流水線技術
超長指令字(VLIW:VeryLongInstructionWord)是由美國Yale大學教授Fisher提出的。它有點類似於超級標量,是一條指令來實現多個操作的并行執行,之所以放到一條指令是為了減少內存訪問。通常一條指令多達上百位,有若干操作數,每條指令可以做不同的幾種運算。那些指令可以并行執行是由編譯器來選擇的。通常VLIW機只有一個控制器,每個周期啟動一條長指令,長指令被分為幾個欄位,每個欄位控制相應的部件。由於編譯器需要考慮數據相關性,避免衝突,並且儘可能利用并行,完成指令調度,所以硬體結構較簡單。
VLIW機器較少,可能不太容易實現,業界比較有名的VLIW公司之一是Transmeta,在加州矽谷SantaClara(矽谷聖地之一,還有SanJose,PaloAlto)。它做的機器採用X86指令集,VLIW實現,具體資料可以去訪問公司的網站。
平時接觸的計算機都是標量機,向量機都是大型計算機,一般用于軍事工業,氣象預報,以及其他大型科學計算領域,這也說明了向量機都很貴。國產的銀河計算機就是向量機普通的計算機所做的計算,例如加減乘除,只能對一組數據進行操作,被稱為標量運算。向量運算一般是若干同類型標量運算的循環。向量運算通常是對多組數據成批進行同樣運算,所得結果也是一組數據。很多做科學計算的大(巨)型機都是向量機。
單指令多數據(SingleInstructionMultipleData)簡稱SIMD。SIMD結構的CPU有多個執行部件,但都在同一個指令部件的控制下。SIMD在性能優勢呢:以加法指令為例,單指令單數據(SISD)的CPU對加法指令解碼后,執行部件先訪問內存,取得第一個操作數;之後再一次訪問內存,取得第二個操作數;隨後才能進行求和運算。而在SIMD型CPU中,指令解碼後幾個執行部件同時訪問內存,一次性獲得所有操作數進行運算。這個特點使得SIMD特別適合於多媒體應用等數據密集型運算。AMD公司的3DNOW!技術其實質就是SIMD,這使K6-2處理器在音頻解碼、視頻回放、3D遊戲等應用中顯示出優異性能。

基本信息
- 中文名
- 流水線技術
- 外文名
- pipeline
- 特點
- Intel首次在486晶元中開始使用的
- 背景
- 借鑒了工業流水線製造的思想