共找到2條詞條名為scanf的結果 展開
- 計算機語言函數
- 英語單詞
scanf
計算機語言函數
scanf()是C語言中的一個輸入函數。與printf函數一樣,都被聲明在頭文件stdio.h里,因此在使用scanf函數時要加上#include 。(在有一些實現中,printf函數與scanf函數在使用時可以不使用預編譯命令#include 。)它是格式輸入函數,即按用戶指定的格式從鍵盤上把數據輸入到指定的變數之中。
函數 scanf() 是從標準輸入流stdin(標準輸入設備,一般指向鍵盤)中讀內容的通用子程序,可以說明的格式讀入多個字元,並保存在對應地址的變數中。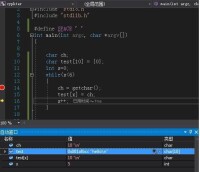
scanf
函數的第一個參數是格式字元串,它指定了輸入的格式,並按照格式說明符解析輸入對應位置的信息並存儲於可變參數列表中對應的指針所指位置。每一個指針要求非空,並且與字元串中的格式符一一順次對應。
scanf函數返回成功讀入的數據項數,讀入數據時遇到了“文件結束”則返回EOF。
如:
函數返回值為int型。如果a和b都被成功讀入,那麼scanf的返回值就是2;
如果只有a被成功讀入,返回值為1;
如果a和b都未被成功讀入,返回值為0;
如果遇到錯誤或遇到end of file,返回值為EOF。end of file為Ctrl+z 或者Ctrl+d。
例:使用scanf函數輸入數據。
&a,&b,&c中的&是定址操作符,&a表示對象a在內存中的地址,是一個右值。變數a,b,c的地址是在編譯階段分配的(存儲順序由編譯器決定)。
這裡注意:如果scanf中%d是連著寫的如“%d%d%d”,在輸入數據時,數據之間不可以用逗號分隔,只能用空白字元(空格或tab鍵或者回車鍵)分隔——“2 (空格)3(tab) 4”或“2(tab)3(回車)4”等。若是“%d,%d,%d”,則在輸入數據時需要加“,”,如“2,3,4”。
format指向的字元串包含的格式指令由以下字元序列組成:
*
表示讀入的數據將被捨棄。帶有*的格式指令不對應可變參數列表中的任何數據。
域寬
以一個非零的十進位整數形式出現。表示該格式指令最多讀入的字元數。
格式說明符
c 讀入域寬指定的數目個字元組成的字元序列(後面不會加上空位元組),如果省略寬度則讀入單字元。如%c或%1c讀入單字元,%2c讀入兩個字元(後面不會加上空位元組),以此類推。
s讀入一個的字元序列,後面會加上空位元組,遇到空白字元(\t \r \n 空格等)完成讀取。
d 讀入可選有符號(可選有符號表示輸入時可以帶符號也可以不帶符號,不帶符號則視為非負)十進位整數。輸入格式應該像strtol函數的base實參為10調用時識別的字元序列一樣。
u 讀入無符號符號十進位整數。輸入格式應該像strtol函數的base實參為10調用時識別的字元序列一樣。
i 讀入可選有符號整數。輸入格式應該像strtol函數的base實參為0調用時識別的字元序列一樣。
a,e,f,g,A,E,F,G 讀入可選有符號浮點數,輸入格式應該像strtod函數識別的字元序列一樣。
o 讀入可選有符號八進位整數。輸入格式應該像strtoul函數的base實參為8調用時識別的字元序列一樣。
x,X讀入可選有符號十六進位整數。輸入格式應該像strtoul函數的base實參為16調用時識別的字元序列一樣。
p 讀入一個指針值。讀入的字元序列應該與fprintf的%p產生的字元序列形式相同。
n 不讀入任何字元,而是把到該位置已讀入的字元數存儲到與之對應的int*指向的位置。本轉換說明符如果帶有*或者帶有域寬信息(如:%*n或%3n等),則後果是未定義的。
掃描字符集合
% 讀入% 符號(百分號)
無效的轉換說明符將引起未定義的行為。
長度修飾符
hh與d, i, o, u, x, X, or n配合使用,表示對應一個signed char或unsigned char數據。
h與d, i, o, u, x, X, or n配合使用,表示對應一個short int或unsigned short int數據。
l 與d, i, o, u, x, X, or n配合使用,表示對應一個long int或unsigned long int數據;與a, A, e, E, f, F, g, or G配合使用表示對應一個double數據;與c,s,[配合使用表示對應wchar_t數據。
ll與d, i, o, u, x, X, or n配合使用,表示對應一個long long int或unsigned long long int數據。
j與d, i, o, u, x, X, or n配合使用,表示對應一個intmax_t或uintmax_t數據。
z與d, i, o, u, x, X, or n配合使用,表示對應一個size_t數據(或與size_t對應的有符號整型數據)。
t與d, i, o, u, x, X, or n配合使用,表示對應一個ptrdiff_t數據(或與ptrdiff_t對應的無符號整型數據)。
L 與a, A, e, E, f, F, g, or G配合使用,表示對應一個long double數據。
如果長度修飾符與格式說明符不匹配則引起未定義的行為。
空白字元會使scanf函數在讀操作中略去輸入中的一個或多個空白字元。
一個非空白字元會使scanf()函數在讀入時剔除掉與這個非空白字元相同的字元。
說明:
(1)%s 表示讀字元串,而 %d 表示讀整數。格式串的處理順序為從左到右,格式說明符逐一與變元表中的變元匹配。為了讀取長整數,可以將 L / l 放在格式說明符的前面;為了讀取短整數,可以將 h 放在格式說明符的前面。這些修飾符可以與 d、i、o、u 和 x 格式代碼一起使用。
(2)默認情況下,a、f、e 和 g 告訴 scanf() 為 float 分配數據。如果將 L / l放在這些修飾符的前面,則 scanf() 為 double 分配數據。使用 L 就是告訴 scanf(),接收數據的變數是 long double 型變數。
(3)如果使用的現代編譯器程序支持 1995 年增加的寬字元特性,則可以與 c 格式代碼一起,用 l 修飾符說明類型 wchar_t 的寬字元指針;也可以與 s 格式代碼一起,用 l 修飾符說明寬字元串的指針。l 修飾符也可以用於修飾掃描集,以說明寬字元。
(4)控制串中的空白符使 scanf() 在輸入流中跳過一個或多個空白行。空白符可以是空格(space)、製表符(tab)和新行符(newline)。本質上,控制串中的空白符使 scanf() 在輸入流中讀,但不保存結果,直到發現非空白字元為止。
(5)非空白符使 scanf() 在流中讀一個匹配的字元並忽略之。例如,"%d,%d" 使 scanf() 先讀入一個整數,讀入中放棄逗號,然後讀另一個整數。如未發現匹配,scanf() 返回。
(6)scanf() 中用於保存讀入值的變元必須都是變數指針,即相應變數的地址。
(7)在輸入流中,數據項必須由空格、製表符和新行符分割。逗號和分號等不是分隔符,比如以下代碼:
將接受輸入 10 20,但遇到 10,20 則失敗。
(8)百分號(%)與格式符之間的星號(*)表示讀指定類型的數據但不保存。因此,
對 10/20 的讀入操作中,10 放入變數 x,20 放入 y。
(9)格式命令可以說明最大域寬。在百分號(%)與格式碼之間的整數用於限制從對應域讀入的最大字元數。例如,希望向 address 讀入不多於 20 個字元時,可以書寫成如下形式:
如果輸入流的內容多於 20 個字元,則下次 scanf() 從此次停止處開始讀入。若達到最大域寬前已遇到空白符,則對該域的讀立即停止;此時,scanf() 跳到下一個域。
(10)雖然空格、製表符和新行符都用做域分割符號,但讀單字元操作中卻按一般字元處理。例如,對輸入流 "x y" 調用:
返回后,x 在變數 a 中,空格在變數 b 中,y 在變數 c 中。
注意,控制串中的其它字元,包括空格、製表符和新行符,都用於從輸入流中匹配並放棄字元,被匹配的字元都放棄。例如,給定輸入流 "10t20",調用:
將把 10 和 20 分別放到 x 和 y 中,t 被放棄,因為 t 在控制串中。
(11)ANSI C 標準向 scanf() 增加了一種新特性,稱為掃描集(scanset)。掃描集定義一個字符集合,可由 scanf() 讀入其中允許的字元並賦給對應字元數組。掃描集合由一對方括弧中的一串字元定義,左方括弧前必須綴以百分號。例如,以下的掃描集使 scanf() 讀入字元 A、B 和 C:
使用掃描集時,scanf() 連續吃進集合中的字元並放入對應的字元數組,直到發現不在集合中的字元為止(即掃描集僅讀匹配的字元)。返回時,數組中放置以 null 結尾、由讀入字元組成的字元串。
用字元 ^ 可以說明補集。把 ^ 字元放為掃描集的第一字元時,構成其它字元組成的命令的補集合,指示 scanf() 只接受未說明的其它字元。
對於許多實現來說,用連字元可以說明一個範圍(ISO C99標準沒有規定)。例如,以下掃描集使 scanf() 接受字母 A 到 Z:
重要的是要注意掃描集是區分大小寫的。因此,希望掃描大、小寫字元時,應該分別說明大、小寫字母。
(12) scanf() 返回等於成功賦值的域數的值,但由於星號修飾符而讀入未賦值的域不計算在內。遇到文件結束則返回EOF;若出錯則返回0。
(1)在高版本的 Visual Studio 編譯器中,scanf 被認為是不安全的,被棄用,應當使用scanf_s代替 scanf。
(2)對於字元串數組或字元串指針變數,由於數組名可以轉換為數組和指針變數名本身就是地址,因此使用scanf()函數時,不需要在它們前面加上"&"操作符。
(3)可以在格式化字元串中的"%"各格式化規定符之間加入一個整數,表示任何讀操作中的最大位數。
(4) scanf函數中沒有類似printf的精度控制。
如: scanf("%5.2f",&a); 是非法的。不能企圖用此語句輸入小數為2位的實數。
(5) scanf中要求給出變數地址,如給出變數名則會出錯
如 scanf("%d",a);是非法的,應改為scanf("%d",&a);才是合法的。
(6)在輸入多個數值數據時,若格式控制串中沒有非格式字元作輸入數據之間的間隔,則可用空格,TAB或回車作間隔。
C編譯在碰到空格,TAB,回車或非法數據(如對“%d”輸入“12A”時,A即為非法數據)時即認為該數據結束。
(7)在輸入字元數據(%c)時,若格式控制串中無非格式字元,則認為所有輸入的字元均為有效字元。
例如:
| 1 | scanf("%c%c%c",&a,&b,&c); |
輸入為:
| 1 | d e f |
則把'd'賦予a, ' '(空格)賦予b,'e'賦予c。因為%c 只要求讀入一個字元,後面不需要用空格作為兩個字元的間隔,因此把' '作為下一個字元送給b。
只有當輸入為:def(字元間無空格)時,才能把'd'賦於a,'e'賦予b,'f'賦予c。如果在格式控制中加入空格作為間隔,
如
| 1 | scanf("%c %c %c",&a,&b,&c); |
則輸入時各數據之間可加空格。
我們用一些例子來說明一些規則:
1 2 3 4 5 6 7 8 9 | #include int main(void) { char a,b; printf("input character a,b\n"); scanf("%c%c",&a,&b); printf("%c%c\n",a,b); return 0; } |
由於scanf函數"%c%c"中沒有空格,輸入M N,結果輸出只有M。而輸入改為MN時則可輸出MN兩字元,見下面的輸入運行情況: input character a,b
輸入:
| 1 |
屏幕顯示:
| 1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include int main(void) { char a,b; printf("input character a,b\n"); scanf("%c %c",&a,&b); printf("\n%c%c\n",a,b); return 0; } |
本例表示scanf格式控制串"%c %c"之間有空格時,輸入的數據之間可以有空格間隔。
(8)如果格式控制串中有非格式字元則輸入時也要輸入該非格式字元。
例如:
| 1 | scanf("%d,%d,%d",&a,&b,&c); |
其中用非格式符“ , ”作間隔符,故輸入時應為:
| 1 | 5,6,7 |
又如:
| 1 | scanf("a=%d,b=%d,c=%d",&a,&b,&c); |
則輸入應為
| 1 | a=5,b=6,c=7 |
如輸入的數據與輸出的類型不一致時,雖然編譯能夠通過,但結果將不正確。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include int main(void) { int a; printf("input a number"); scanf("%d",&a); printf("%ld",a); return 0; } |
由於輸入數據類型為整型,而輸出語句的格式串中說明為長整型,因此輸出結果和輸入數據不符。輸出並不是輸入的值。
如將scanf("%d",&a); 語句改為 scanf("%ld",&a);
輸入數據為長整型,輸入輸出數據才相等。
如何讓scanf()函數正確接受有空格的字元串?如: I love you!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include int main(void) { char str[80]; scanf("%s",str); printf("%s",str); return 0; } |
輸入:
| 1 | I love you! |
輸出:
| 1 | I |
上述程序並不能達到預期目的。因為scanf掃描到"I"後面的空格就認為對str的掃描結束(空格沒有被掃描),並忽略後面的" love you!"。值得注意的是,我們改動一下上面的程序來驗證一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #include #include int main(void) { char str[80],str1[80],str2[80]; scanf("%s",str); printf("%s\n",str); Sleep(5000); scanf("%s",str1); scanf("%s",str2); printf("%s\n",str1); printf("%s\n",str2); return 0; } |
輸入:
| 1 | I love you! |
輸出:
1 2 3 | I love you! |
好了,原因知道了,所以結論是:殘留的信息 love you是存在於stdin流中,而不是在鍵盤緩衝區中。那麼scanf()函數能不能完成這個任務?回答是:能!別忘了scanf()函數還有一個 %[] 格式控制符(如果對%[]不了解的請查看本文的上篇),請看下面的程序:
1 2 3 4 5 6 7 8 | #include int main(void) { char str[50]; scanf("%[^\n]",str); printf("%s\n",str); return 0; } |
鍵盤緩衝區殘餘信息問題
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include int main(void) { int a; char c; while(c!='N') { scanf("%d",&a); scanf("%c",&c); printf("a=%dc=%c\n",a,c); } return 0; } |
scanf("%c", &c);這句不能正常接收字元,什麼原因呢?我們用printf("c = %d\n", c);將C用int表示出來,啟用printf("c = %d\n", c);這一句,看看scanf()函數賦給C到底是什麼,結果是c=10 ,ASCII值為10是什麼?換行即\n.對了,我們每擊打一下"Enter"鍵,向鍵盤緩衝區發去一個“回車”(\r),一個“換行"(\n),在這裡\r被scanf()函數處理掉了(姑且這麼認為吧^_^),而\n被scanf()函數“錯誤”地賦給了c.解決辦法:可以在兩個scanf()函數之間加getchar(),但是要視具體scanf()語句加那個,這裡就不分析了,讀者自己去摸索吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include int main(void) { int a; char c; while(c!='N') { scanf("%d",&a); fflush(stdin); scanf("%c",&c); fflush(stdin); printf("a=%dc=%c\n",a,c); } return 0; } |
這裡再給一個用“空格符”來處理緩衝區殘餘信息的示例:
版本1:運行出錯的程序
1 2 3 4 5 6 7 8 9 10 | #include int main(void) { int i; char j; for(i=0;i<10;++i) scanf("%c",&j); printf("%c",j); return 0; } |
版本2:使用了空格控制符后
1 2 3 4 5 6 7 8 9 10 | #include int main(void) { int i; char j; for(i=0;i<10;++i) scanf(" %c",&j); printf("%c",j); return 0; } |
接著,我們運行看看,首先,運行第一個版本(錯誤的程序)
我們輸入:
0 1 2 3 4 5 6 7 8 9
結果是一個空字元
再運行第二個版本(正確的程序)
同樣輸入:
0 1 2 3 4 5 6 7 8 9
這一次就顯示字元9,故此程序正確。
那麼為什麼第二個程序就正確呢,原因何在,在%前面加一個空格就這麼有用,答案是肯定的,就是%前面的空格在起作用,讀者看看此文章的前面部分,在scanf的使用過程中應注意的問題中已經指出:“scanf()的格式控制串可以使用空白字元或其它非空白字元,使用空白字元會使scanf()函數在讀操作中略去輸入中的零個或多個空白字元。”
所以在%前面加上了空格(空格屬於空白字元,此外還有像製表符等也屬於空白字元),在輸入過程中,將略去輸入中的一個或多個空白字元,所以我們輸入的0 1 2 3 4 5 6 7 8 9這些字元中的空白字元就被略去了,字元9也就正確的列印出來了,這樣子解釋,相信大家都看明白勒吧!
輸入類型與格式化字元串不匹配導致stdin流的阻塞。
1 2 3 4 5 6 7 8 9 10 | #include int main(void) { int a=0,b=0,c=0,ret=0; ret=scanf("%d%d%d",&a,&b,&c); printf("第一次讀入數量:%d\n",ret); ret=scanf("%d%d%d",&a,&b,&c); printf("第二次讀入數量:%d\n",ret); return 0; } |
我們定義了a,b,c三個變數來接受輸入的內容,定義了變數ret來接收scanf函數的返回值。
正確輸入的話:
![scanf[計算機語言函數]](https://i1.twwiki.net/cover/w200/m0/c/m0ccc6cf333c12fd8c18495407a6ca2e8.jpg)
scanf[計算機語言函數]
![scanf[計算機語言函數]](https://i1.twwiki.net/cover/w200/md/a/mda32fb48f38eddf839e489e795a1c56a.jpg)
scanf[計算機語言函數]
執行到第二個scanf時,字元’b’還是與格式化字元串不匹配,stdin流仍然被阻塞,所以沒有提示輸入,scanf函數將0返回。
將代碼作如下修改,可以有力的證明上述結論。
1 2 3 4 5 6 7 8 9 10 | #include int main(void) { int a=0,b=0,c=0,ret=0; ret=scanf("%d%d%d",&a,&b,&c); printf("第一次讀入數量:%d\n",ret); ret=scanf("%c%d%d",&a,&b,&c); printf("第二次讀入數量:%d\n",ret); return 0; } |
當把第二個scanf函數內的格式化字元串改為”%c%d%d”時,運行結果如下:
![scanf[計算機語言函數]](https://i1.twwiki.net/cover/w200/m1/0/m10fd263f1665091bb30408975a56bb16.jpg)
scanf[計算機語言函數]
執行到第二個scanf函數時,字元’b’與格式化字元串”%c%d%d”中的%c匹配,stdin流終於疏通,在輸入6,則將變數a,b,c分別賦值為98(‘b’的ASCII碼)、2、6,scanf函數返回3。
有上述問題可知,當使用scanf函數時,如果遇到一些匪夷所思的問題,在scanf函數后正確使用fflush(stdin);,清空輸入緩衝區,可以解決很多問題。以本題為例:
1 2 3 4 5 6 7 8 9 10 11 12 | #include int main(void) { int a=0,b=0,c=0,ret=0; ret=scanf("%d%d%d",&a,&b,&c); fflush(stdin); printf("第一次讀入數量:%d\n",ret); ret=scanf("%d%d%d",&a,&b,&c); fflush(stdin); printf("第二次讀入數量:%d\n",ret); return 0; } |
運行結果:
![scanf[計算機語言函數]](https://i1.twwiki.net/cover/w200/m7/c/m7c84e32f990e6a1833e4af4284254b30.jpg)
scanf[計算機語言函數]
如何處理scanf()函數誤輸入造成程序死鎖或出錯
1 2 3 4 5 6 7 8 9 | #include int main(void) { int a,b,c; scanf("%d,%d",&a,&b); c=a+b; printf("%d+%d=%d",a,b,c); return 0; } |
如上程序,如果正確輸入a,b的值,那麼沒什麼問題,但是,你不能保證使用者每一次都能正確輸入,一旦輸入了錯誤的類型,你的程序不是死鎖,就是得到一個錯誤的結果,呵呵,這可能所有人都遇到過的問題吧?解決方法:scanf()函數執行成功時的返回值是成功讀取的變數數,也就是說,你這個scanf()函數有幾個變數,如果scanf()函數全部正常讀取,它就返回幾。但這裡還要注意另一個問題,如果輸入了非法數據,鍵盤緩衝區就可能還個有殘餘信息問題。正確的常式:
1 2 3 4 5 6 7 8 9 10 | #include int main(void) { int a,b,c; while(scanf("%d%d",&a,&b)!=2) fflush(stdin); c=a+b; printf("%d+%d=%d",a,b,c); return 0; } |
補充
fflush(stdin)這個方法在GCC下不可用。(在VC6.0下可以)
以下是 C99 對 fflush 函數的定義:
int fflush(FILE *stream);
如果stream指向輸出流或者更新流(update stream),並且這個更新流
執行的操作不是輸入,那麼fflush函數將把任何未被寫入的數據寫入stream
指向的文件(如標準輸出文件stdout)。否則,fflush函數的行為是不確定的。
C和C++的標準里從來沒有定義過 fflush(stdin)。
fflush(NULL)清空所有輸出流和上面提到的更新流。如果發生寫錯誤,fflush
函數會給那些流打上錯誤標記,並且返回EOF,否則返回0。
由此可知,如果 stream 指向輸入流(如 stdin),那麼 fflush 函數的行為是不確定的。故而使用
fflush(stdin) 是不正確的,至少是移植性不好的。
可採用如下方法:
方法一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #include void flush() { char c; while((c=getchar())!='\n'&&c!=EOF); } intmain(void) { int a,b,c; while(scanf("%d%d",&a,&b)!=2) flush(); c=a+b; printf("%d+%d=%d",a,b,c); return 0; } |
方法二:
使用getchar()代替fflush(stdin)
程序示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include int main(void) { inti,c; while(1) { printf("Pleaseinputaninteger:"); scanf("%d",&i); if(feof(stdin)||ferror(stdin)) { //如果用戶輸入文件結束標誌(或文件已被讀完),或者發生讀寫錯誤,則退出循環 //dosomething break; } //沒有發生錯誤,清空輸入流。通過while循環把輸入流中的余留數據“吃”掉 while((c=getchar())!='\n'&&c!=EOF); //可直接將這句代碼當成fflush(stdin)的替代,直接運行可清除輸入緩存流 //使用scanf("%*[^\n]");也可以清空輸入流,不過會殘留\n字元。 printf("%d\n",i); } return 0; } |
使用scanf函數進行輸入,必須指定輸入的數據的類型和格式,不僅繁瑣複雜,而且很容易出錯。C++保留scanf只是為了和C兼容,以便過去用C語言寫的程序可以在C++的環境下運行。C++的編程人員都願意使用cin進行輸入,很少使用scanf。
但是scanf有一個明顯的優點,速度比cin函數快
基本信息
- 中文名
- 格式輸入
- 外文名
- Scan Format
- 定義
- 標準庫函數
- 開發語言
- C/C++
- 應用科學
- 計算機科學
- 外語縮寫
- scanf