Kafka
科技術語
Kafka是由Apache軟體基金會開發的一個開源流處理平台,由Scala和Java編寫。Kafka是一種高吞吐量的分散式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網路上的許多社會功能的一個關鍵因素。這些數據通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。對於像Hadoop一樣的日誌數據和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka的目的是通過Hadoop的并行載入機制來統一線上和離線的消息處理,也是為了通過集群來提供實時的消息。
kafka的架構師jay kreps對於kafka的名稱由來是這樣講的,由於jay kreps非常喜歡franz kafka,並且覺得kafka這個名字很酷,因此取了個和消息傳遞系統完全不相干的名稱kafka,該名字並沒有特別的含義。
kafka的誕生,是為了解決linkedin的數據管道問題,起初linkedin採用了ActiveMQ來進行數據交換,大約是在2010年前後,那時的ActiveMQ還遠遠無法滿足linkedin對數據傳遞系統的要求,經常由於各種缺陷而導致消息阻塞或者服務無法正常訪問,為了能夠解決這個問題,linkedin決定研發自己的消息傳遞系統,當時linkedin的首席架構師jay kreps便開始組織團隊進行消息傳遞系統的研發。
Kafka是一種高吞吐量的分散式發布訂閱消息系統,有如下特性:
• 通過O(1)的磁碟數據結構提供消息的持久化,這種結構對於即使數以TB的消息存儲也能夠保持長時間的穩定性能。
• 高吞吐量:即使是非常普通的硬體Kafka也可以支持每秒數百萬的消息。
• 支持通過Kafka伺服器和消費機集群來分區消息。
• 支持Hadoop并行數據載入。
Kafka通過官網發布了最新版本2.0.0。
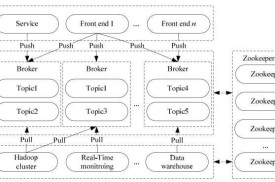
• Broker
• Kafka集群包含一個或多個伺服器,這種伺服器被稱為broker。
• Topic
• 每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存於一個或多個broker上但用戶只需指定消息的Topic即可生產或消費數據而不必關心數據存於何處)
• Partition
• Partition是物理上的概念,每個Topic包含一個或多個Partition。
• Producer
• 負責發布消息到Kafka broker。
• Consumer
• 消息消費者,向Kafka broker讀取消息的客戶端。
• Consumer Group
• 每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於默認的group)。
基本信息
- 外文名
- Kafka
- 應用平台
- 支持語言
- Scala、Java
- 開發商
- Apache軟體基金會
- 發行時間
- 2018-06-30
- 軟體大小
- 65.4 MB
- 軟體授權
- Apache License 2.0
- 軟體版本
- 2.7.0
- 軟體名稱
- Apache Kafka
- 最近更新時間
- 2020年12月21日