共找到13條詞條名為CMA的結果 展開
CMA
連續的內存分配器
徠Contiguous Memory Allocator是智能連續內存分配技術是Linux Kernel內存管理系統的擴展
CMA的全稱是contiguous memory allocator,其工作原理是:預留一段的內存給驅動使用,但當驅動不用的時候,memory allocator(buddy system)可以分配給用戶進程用作匿名內存或者頁緩存。而當驅動需要使用時,就將進程佔用的內存通過回收或者遷移的方式將之前佔用的預留內存騰出來,供驅動使用。本文對CMA的初始化,分配和釋放做一下源碼分析(源碼版本v3.10).
CMA的初始化必須在buddy 物理內存管理初始化之前和memory
block early allocator分配器初始化之後(可參考dma_contiguous_reserve函數的註釋:This function reserves memory from early allocator. It should be called by arch specific code once the early allocator (memblock or bootmem) has
been activated and all other subsystems have already allocated/reserved
memory.)。
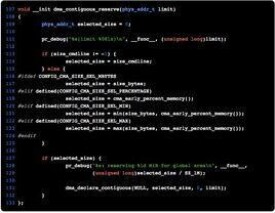
在ARM中,初始化CMA的介面是:dma_contiguous_reserve(phys_addr_t limit)。參數limit是指該CMA區域的上限。
setup_arch->arm_memblock_init->dma_contiguous_reserve:
107 void __init dma_contiguous_reserve(phys_addr_t limit)
108 {
109 phys_addr_t selected_size = 0;
110
111 pr_debug("%s(limit %08lx)\n", __func__, (unsigned long)limit);
112
113 if (size_cmdline != -1) {
114 selected_size = size_cmdline;
115 } else {
116 #ifdef CONFIG_CMA_SIZE_SEL_MBYTES
117 selected_size = size_bytes;
118 #elif defined(CONFIG_CMA_SIZE_SEL_PERCENTAGE)
119 selected_size = cma_early_percent_memory();
1徠20 #elif defined(CONFIG_CMA_SIZE_SEL_MIN)
121 selected_size = min(size_bytes, cma_early_percent_memory());
122 #elif defined(CONFIG_CMA_SIZE_SEL_MAX)
123 selected_size = max(size_bytes, cma_early_percent_memory());
124 #endif
125 }
126
127 if (selected_size) {
128 pr_debug("%s: reserving %ld MiB for global area\n", __func__,
129 (unsigned long)selected_size / SZ_1M);
130
131 dma_declare_contiguous(NULL, selected_size, 0, limit);
132 }
133 };
在該函數中,需要弄清楚倆值,分別是selected_size和limit。selectetd_size是聲明CMA區域的大小,limit規定了CMA區域在分配時候的上界。
首先介紹下怎樣獲得selected_size: 若cmdline中定義了cma=”xxx”,那麼就用cmdline中規定的(114行)。若cmdline中沒有定義,則看有沒有在config文件中定義CONFIG_CMA_SIZE_SEL_MBYTES(117行)或者CONFIG_CMA_SIZE_SEL_PERCENTAGE(119行)。如果前面兩個配置項都沒有定義,則從CONFIG_CMA_SIZE_MBYTES和CONFIG_CMA_SIZE_PERCENTAGE中選擇兩者的最小值(121行)或者最大值(123行)。
計算好CMA的size並得到了limit后,就進入dma_declare_contiguous中。
setup_arch->arm_memblock_init->dma_contiguous_reserve->
dma_declare_contiguous:
218
230 int __init dma_declare_contiguous(struct device *dev, phys_addr_t size,
231 phys_addr_t base, phys_addr_t limit)
232 {
233 struct cma_reserved *r = &cma_reserved[cma_reserved_count];
234 phys_addr_t alignment;
235
…
248
249
250 alignment = PAGE_SIZE << max(MAX_ORDER - 1, pageblock_order);
251 base = ALIGN(base, alignment);
252 size = ALIGN(size, alignment);
253 limit &= ~(alignment - 1);
254
255
256 if (base) {
257 if (memblock_is_region_reserved(base, size) ||
258 memblock_reserve(base, size) < 0) {
259 base = -EBUSY;
260 goto err;
261 }
262 } else {
263
267 phys_addr_t addr = __memblock_alloc_base(size, alignment, limit);
268 if (!addr) {
269 base = -ENOMEM;
270 goto err;
271 } else {
272 base = addr;
273 }
274 }
275
276
280 r->start = base;
281 r->size = size;
282 r->dev = dev;
283 cma_reserved_count++;
284 pr_info("CMA: reserved %ld MiB at %08lx\n", (unsigned long)size / SZ_1M,
285 (unsigned long)base);
286
287
288 dma_contiguous_early_fixup(base, size);
289 return 0;
290 err:
291 pr_err("CMA: failed to reserve %ld MiB\n", (unsigned long)size / SZ_1M);
292 return base;
293 }
在該函數中,首先根據輸入的參數size和limit,得到CMA區域的基址和大小。基址若沒有指定的話(在該初始化的情境中是0),就需要用early allocator分配了。而大小需要進行一個alignment,這個alignment一般是4MB(250行,MAX_ORDER是11, pageblock_order是10)。用early allocator分配的這個CMA會從物理內存lowmem的高地址開始分配。
得到CMA區域的基址和大小后,會存入到cma_reserved[]全局數組中(280~282行)。全局變數cma_reserved_count來標識在cma_reserved[]數組中,保留了多少個cma區(283行)
在ARM的kernel code中,得到的CMA區域還會保存到dma_mmu_remap數組中(這個dma_mmu_remap數據結構只記錄基址和大小,下面396~410行)。
396 struct dma_contig_early_reserve {
397 phys_addr_t base;
398 unsigned long size;
399 };
400
401 static struct dma_contig_early_reserve dma_mmu_remap[MAX_CMA_AREAS] __initdata;
402
403 static int dma_mmu_remap_num __initdata;
404
405 void __init dma_contiguous_early_fixup(phys_addr_t base, unsigned long size)
406 {
407 dma_mmu_remap[dma_mmu_remap_num].base = base;
408 dma_mmu_remap[dma_mmu_remap_num].size = size;
409 dma_mmu_remap_num++;
410 }
以上,只是將CMA區域reserve下來並記錄到相關的數組中。當buddy系統初始化結束后,會對reserved的CMA區域進行進一步的處理:
200 static int __init cma_init_reserved_areas(void) 201 { 202 struct cma_reserved *r = cma_reserved; 203 unsigned i = cma_reserved_count; 204 205 pr_debug("%s()\n", __func__); 206 207 for (; i; --i, ++r) { 208 struct cma *cma; 209 cma = cma_create_area(PFN_DOWN(r->start), 210 r->size >> PAGE_SHIFT); 211 if (!IS_ERR(cma)) 212 dev_set_cma_area(r->dev, cma); 213 } 214 return 0; 215 } 216 core_initcall(cma_init_reserved_areas);
212行,創建的struct cma結構會設置在dev->cma_area中。這樣,當某個外設進行CMA分配的時候,便根據dev->cma_area中設定的區間進行CMA
buffer的分配。
cma_init_reserved_areas->
cma_create_area:
159 static __init struct cma *cma_create_area(unsigned long base_pfn, 160 unsigned long count) 161 { 162 int bitmap_size = BITS_TO_LONGS(count) * sizeof(long); 163 struct cma *cma; 164 int ret = -ENOMEM; 165 166 pr_debug("%s(base %08lx, count %lx)\n", __func__, base_pfn, count); 167 168 cma = kmalloc(sizeof *cma, GFP_KERNEL); 169 if (!cma) 170 return ERR_PTR(-ENOMEM); 171 172 cma->base_pfn = base_pfn; 173 cma->count = count; 174 cma->bitmap = kzalloc(bitmap_size, GFP_KERNEL); 175 176 if (!cma->bitmap) 177 goto no_mem; 178 179 ret = cma_activate_area(base_pfn, count); 180 if (ret) 181 goto error; 182 183 pr_debug("%s: returned %p\n", __func__, (void *)cma); 184 return cma; 185 186 error: 187 kfree(cma->bitmap); 188 no_mem: 189 kfree(cma); 190 return ERR_PTR(ret); 191 }
cma_init_reserved_areas->
cma_create_area-> cma_create_area:
137 static __init int cma_activate_area(unsigned long base_pfn, unsigned long count) 138 { 139 unsigned long pfn = base_pfn; 140 unsigned i = count >> pageblock_order; 141 struct zone *zone; 142 143 WARN_ON_ONCE(!pfn_valid(pfn)); 144 zone = page_zone(pfn_to_page(pfn)); 145 146 do { 147 unsigned j; 148 base_pfn = pfn; 149 for (j = pageblock_nr_pages; j; --j, pfn++) { 150 WARN_ON_ONCE(!pfn_valid(pfn)); 151 if (page_zone(pfn_to_page(pfn)) != zone) 152 return -EINVAL; 153 } 154 init_cma_reserved_pageblock(pfn_to_page(base_pfn)); 155 } while (--i); 156 return 0; 157 }
在之前CMA初始化的時候,看到其base和size都會pageblock_order對齊。pageblock_order的值是10,即一個pageblock_order代表4MB的內存塊(2^10 * PAGE_SIZE)。因此,該函數cma_activate_area是對每一個用於CMA的block進行初始化(140行,155行)。由於CMA規定了,其區域內的頁面必須在一個zone中,因此149~153行對每一個頁面進行甄別是否都在同一個zone中,然後對CMA區域內的每一個pageblock進行初始化。
cma_init_reserved_areas->
cma_create_area-> cma_create_area-> init_cma_reserved_pageblock:
769 #ifdef CONFIG_CMA 770 771 void __init init_cma_reserved_pageblock(struct page *page) 772 { 773 unsigned i = pageblock_nr_pages; 774 struct page *p = page; 775 776 do { 777 __ClearPageReserved(p); 778 set_page_count(p, 0); 779 } while (++p, --i); 780 781 set_page_refcounted(page); 782 set_pageblock_migratetype(page, MIGRATE_CMA); 783 __free_pages(page, pageblock_order); 784 totalram_pages += pageblock_nr_pages; 785 #ifdef CONFIG_HIGHMEM 786 if (PageHighMem(page)) 787 totalhigh_pages += pageblock_nr_pages; 788 #endif 789 }
進入buddy的空閑頁面其page->_count都需要為0.因此在778行設置pageblock 區內的每一個page的使用技術都為0.而781行將一個pageblock塊的第一個page的_count設置為1的原因是在783行的__free_pages的時候會put_page_testzero減1. 同時還需要設置pageblock的第一個頁面的migratetype為MIGRATE_CMA. 所有頁面都有一個migratetype放在zone->pageblock_flags中,每個migratetype佔3個bit,但對於buddy
system中的pageblock的第一個頁面的migratetype才有意義(其他頁面設置了也用不上)。
對頁面的初始化做完后,就通過__free_pages將其存放在buddy system中(783行)。
由此可見在初始化的時候,所有的CMA都放在order為10的buddy鏈表中,具體放在相關zone的zone->free_area[10].free_list[MIGRATE_CMA]鏈表上。
CMA並不直接開放給driver的開發者。開發者只需要在需要分配dma緩衝區的時候,調用dma相關函數就可以了,例如dma_alloc_coherent。最終dma相關的分配函數會到達cma的分配函數:dma_alloc_from_contiguous
295 306 struct page *dma_alloc_from_contiguous(struct device *dev, int count, 307 unsigned int align) 308 { 309 unsigned long mask, pfn, pageno, start = 0; 310 struct cma *cma = dev_get_cma_area(dev); 311 struct page *page = NULL; 312 int ret; 313 314 if (!cma || !cma->count) 315 return NULL; 316 317 if (align > CONFIG_CMA_ALIGNMENT) 318 align = CONFIG_CMA_ALIGNMENT; 319 320 pr_debug("%s(cma %p, count %d, align %d)\n", __func__, (void *)cma, 321 count, align); 322 323 if (!count) 324 return NULL; 325 326 mask = (1 << align) - 1; 327 328 mutex_lock(&cma_mutex); 329 330 for (;;) { 331 pageno = bitmap_find_next_zero_area(cma->bitmap, cma->count, 332 start, count, mask); 333 if (pageno >= cma->count) 334 break; 335 336 pfn = cma->base_pfn + pageno; 337 ret = alloc_contig_range(pfn, pfn + count, MIGRATE_CMA); 338 if (ret == 0) { 339 bitmap_set(cma->bitmap, pageno, count); 340 page = pfn_to_page(pfn); 341 break; 342 } else if (ret != -EBUSY) { 343 break; 344 } 345 pr_debug("%s(): memory range at %p is busy, retrying\n", 346 __func__, pfn_to_page(pfn)); 347 348 start = pageno + mask + 1; 349 } 350 351 mutex_unlock(&cma_mutex); 352 pr_debug("%s(): returned %p\n", __func__, page); 353 return page; 354 }
301~304行的註釋,告訴該函數的目的是從特定的driver(或者系統默認)CMA中分配一段buffer. 310行是獲取特定driver的CMA區域,若dev沒有對應的CMA,則從系統默認的CMA區中查找。每一個CMA區域都有一個bitmap用來記錄對應的page是否已經被使用(struct cma->bitmap)。因此從CMA區域查找一定數量的連續內存頁的方法就是在cma->bitmap中查找連續的N個為0的bit,代表連續的N個物理頁。若找到的話就返回一個不大於CMA邊界的索引(333行)並設置對應的cma->bitmap中的bit位(339行)。
dma_alloc_from_contiguous-> dma_alloc_from_contiguous:
5908 5928 int alloc_contig_range(unsigned long start, unsigned long end, 5929 unsigned migratetype) 5930 { 5931 unsigned long outer_start, outer_end; 5932 int ret = 0, order; 5933 5934 struct compact_control cc = { 5935 .nr_migratepages = 0, 5936 .order = -1, 5937 .zone = page_zone(pfn_to_page(start)), 5938 .sync = true, 5939 .ignore_skip_hint = true, 5940 }; 5941 INIT_LIST_HEAD(&cc.migratepages); 5942 5943 5966 5967 ret = start_isolate_page_range(pfn_max_align_down(start), 5968 pfn_max_align_up(end), migratetype, 5969 false); 5970 if (ret) 5971 return ret; 5972 5973 ret = __alloc_contig_migrate_range(&cc, start, end); 5974 if (ret) 5975 goto done; 5976 5977 5993 5994 lru_add_drain_all(); 5995 drain_all_pages(); 5996 5997 order = 0; 5998 outer_start = start; 5999 while (!PageBuddy(pfn_to_page(outer_start))) { 6000 if (++order >= MAX_ORDER) { 6001 ret = -EBUSY; 6002 goto done; 6003 } 6004 outer_start &= ~0UL << order; 6005 } 6006 6007 6008 if (test_pages_isolated(outer_start, end, false)) { 6009 pr_warn("alloc_contig_range test_pages_isolated(%lx, %lx) failed\n", 6010 outer_start, end); 6011 ret = -EBUSY; 6012 goto done; 6013 } 6014 6015 6016 6017 outer_end = isolate_freepages_range(&cc, outer_start, end); 6018 if (!outer_end) { 6019 ret = -EBUSY; 6020 goto done; 6021 } 6022 6023 6024 if (start != outer_start) 6025 free_contig_range(outer_start, start - outer_start); 6026 if (end != outer_end) 6027 free_contig_range(end, outer_end - end); 6028 6029 done: 6030 undo_isolate_page_range(pfn_max_align_down(start), 6031 pfn_max_align_up(end), migratetype); 6032 return ret; 6033 }
該函數的註釋中講述了調用該函數需要注意的事項:對齊,所分配的頁面都在一個zone中。釋放時,需要使用free_contig_range。
在5967行,先對始末區間進行對齊,然後通過start_isolate_page_range,先確認該區間內沒有unmovable的頁,如果有unmovable的頁,那unmovable的頁占著內存而不能被遷移,導致整個區間就都不能被用作CMA(start_isolate_page_range->set_migratetype_isolate->has_unmovable_pages)。確認沒有unmovable頁后,將該區間的pageblock標誌為MIGRATE_ISOLATE。並將對應的page在buddy中都移到freearea[].free_list[MIGRATE_ISLOATE]的鏈表上,並調用drain_all_pages(start_isolate_page_range->set_migratetype_isolate),將每處理器上暫存的空閑頁都釋放給buddy(因為有可能在要分配的CMA區間中有頁面還在pcp的pageset中—pageset記錄了每cpu暫存的空閑熱頁)。然後通過5973行的__alloc_contig_migrate_range,將被隔離出的頁中,已經被buddy分配出去的頁摘出來,然後遷移到其他地方,以騰出物理頁給CMA用。騰出連續的物理頁后,便會通過6017行的isolate_freepages_range來將這段連續的空閑物理頁從buddy
system取下來。
__alloc_contig_migrate_range的代碼如下:
dma_alloc_from_contiguous-> dma_alloc_from_contiguous-> __alloc_contig_migrate_range:
5862 5863 static int __alloc_contig_migrate_range(struct compact_control *cc, 5864 unsigned long start, unsigned long end) 5865 { 5866 5867 unsigned long nr_reclaimed; 5868 unsigned long pfn = start; 5869 unsigned int tries = 0; 5870 int ret = 0; 5871 5872 migrate_prep(); 5873 5874 while (pfn < end || !list_empty(&cc->migratepages)) { 5875 if (fatal_signal_pending(current)) { 5876 ret = -EINTR; 5877 break; 5878 } 5879 5880 if (list_empty(&cc->migratepages)) { 5881 cc->nr_migratepages = 0; 5882 pfn = isolate_migratepages_range(cc->zone, cc, 5883 pfn, end, true); 5884 if (!pfn) { 5885 ret = -EINTR; 5886 break; 5887 } 5888 tries = 0; 5889 } else if (++tries == 5) { 5890 ret = ret < 0 ? ret : -EBUSY; 5891 break; 5892 } 5893 5894 nr_reclaimed = reclaim_clean_pages_from_list(cc->zone, 5895 &cc->migratepages); 5896 cc->nr_migratepages -= nr_reclaimed; 5897 5898 ret = migrate_pages(&cc->migratepages, alloc_migrate_target, 5899 0, MIGRATE_SYNC, MR_CMA); 5900 } 5901 if (ret < 0) { 5902 putback_movable_pages(&cc->migratepages); 5903 return ret; 5904 } 5905 return 0; 5906 }
該函數主要進行遷移工作。由於CMA區域的頁是允許被buddy system當作movable頁分配出去的,所以,如果某些頁之前被buddy分配出去了,但在cma->bitmap上仍然記錄該頁可以被用作CMA,所以這時候就需要將該頁遷移到別的地方以將該頁騰出來供CMA用。
5882行做的事情是,將被buddy分配出去的頁掛到cc->migratepages的鏈表上。然後通過5894行的reclaim_clean_pages_from_list看是否某些頁是clean可以直接回收掉,之後在通過5898行的migrate_pages將暫時不能回收的內存內容遷移到物理內存的其他地方。
隔離需要遷移和回收頁的函數isolate_migratepages_range如下:
dma_alloc_from_contiguous-> dma_alloc_from_contiguous-> __alloc_contig_migrate_range-> isolate_migratepages_range:
427 447 unsigned long 448 isolate_migratepages_range(struct zone *zone, struct compact_control *cc, 449 unsigned long low_pfn, unsigned long end_pfn, bool unevictable) 450 { 451 unsigned long last_pageblock_nr = 0, pageblock_nr; 452 unsigned long nr_scanned = 0, nr_isolated = 0; 453 struct list_head *migratelist = &cc->migratepages; 454 isolate_mode_t mode = 0; 455 struct lruvec *lruvec; 456 unsigned long flags; 457 bool locked = false; 458 struct page *page = NULL, *valid_page = NULL; 459 460 465 while (unlikely(too_many_isolated(zone))) { 466 467 if (!cc->sync) 468 return 0; 469 470 congestion_wait(BLK_RW_ASYNC, HZ/10); 471 472 if (fatal_signal_pending(current)) 473 return 0; 474 } 475 476 477 cond_resched(); 478 for (; low_pfn < end_pfn; low_pfn++) { 479 480 if (locked && !((low_pfn+1) % SWAP_CLUSTER_MAX)) { 481 if (should_release_lock(&zone->lru_lock)) { 482 spin_unlock_irqrestore(&zone->lru_lock, flags); 483 locked = false; 484 } 485 } 486 487 493 if ((low_pfn & (MAX_ORDER_NR_PAGES - 1)) == 0) { 494 if (!pfn_valid(low_pfn)) { 495 low_pfn += MAX_ORDER_NR_PAGES - 1; 496 continue; 497 } 498 } 499 500 if (!pfn_valid_within(low_pfn)) 501 continue; 502 nr_scanned++; 503 504 510 page = pfn_to_page(low_pfn); 511 if (page_zone(page) != zone) 512 continue; 513 514 if (!valid_page) 515 valid_page = page; 516 517 518 pageblock_nr = low_pfn >> pageblock_order; 519 if (!isolation_suitable(cc, page)) 520 goto next_pageblock; 521 522 523 if (PageBuddy(page)) 524 continue; 525 526 531 if (!cc->sync && last_pageblock_nr != pageblock_nr && 532 !migrate_async_suitable(get_pageblock_migratetype(page))) { 533 cc->finished_update_migrate = true; 534 goto next_pageblock; 535 } 536 537 542 if (!PageLRU(page)) { 543 if (unlikely(balloon_page_movable(page))) { 544 if (locked && balloon_page_isolate(page)) { 545 546 cc->finished_update_migrate = true; 547 list_add(&page->lru, migratelist); 548 cc->nr_migratepages++; 549 nr_isolated++; 550 goto check_compact_cluster; 551 } 552 } 553 continue; 554 } 555 556 566 if (PageTransHuge(page)) { 567 if (!locked) 568 goto next_pageblock; 569 low_pfn += (1 << compound_order(page)) - 1; 570 continue; 571 } 572 573 574 locked = compact_checklock_irqsave(&zone->lru_lock, &flags, 575 locked, cc); 576 if (!locked || fatal_signal_pending(current)) 577 break; 578 579 580 if (!PageLRU(page)) 581 continue; 582 if (PageTransHuge(page)) { 583 low_pfn += (1 << compound_order(page)) - 1; 584 continue; 585 } 586 587 if (!cc->sync) 588 mode |= ISOLATE_ASYNC_MIGRATE; 589 590 if (unevictable) 591 mode |= ISOLATE_UNEVICTABLE; 592 593 lruvec = mem_cgroup_page_lruvec(page, zone); 594 595 596 if (__isolate_lru_page(page, mode) != 0) 597 continue; 598 599 VM_BUG_ON(PageTransCompound(page)); 600 601 602 cc->finished_update_migrate = true; 603 del_page_from_lru_list(page, lruvec, page_lru(page)); 604 list_add(&page->lru, migratelist); 605 cc->nr_migratepages++; 606 nr_isolated++; 607 608 check_compact_cluster: 609 610 if (cc->nr_migratepages == COMPACT_CLUSTER_MAX) { 611 ++low_pfn; 612 break; 613 } 614 615 continue; 616 617 next_pageblock: 618 low_pfn = ALIGN(low_pfn + 1, pageblock_nr_pages) - 1; 619 last_pageblock_nr = pageblock_nr; 620 } 621 622 acct_isolated(zone, locked, cc); 623 624 if (locked) 625 spin_unlock_irqrestore(&zone->lru_lock, flags); 626 627 628 if (low_pfn == end_pfn) 629 update_pageblock_skip(cc, valid_page, nr_isolated, true); 630 631 trace_mm_compaction_isolate_migratepages(nr_scanned, nr_isolated); 632 633 count_compact_events(COMPACTMIGRATE_SCANNED, nr_scanned); 634 if (nr_isolated) 635 count_compact_events(COMPACTISOLATED, nr_isolated); 636 637 return low_pfn; 638 }
上面函數的作用是在指定分配到的CMA區域的範圍內將被使用到的內存(PageLRU(Page)不為空)隔離出來掛到cc->migratepages鏈表上,以備以後遷移。要遷移的頁分兩類,一類是可以直接被回收的(比如頁緩存),另一類是暫時不能被回收,內容需要遷移到其他地方。可以被回收的物理頁流程如下:
dma_alloc_from_contiguous-> dma_alloc_from_contiguous-> __alloc_contig_migrate_range-> reclaim_clean_pages_from_list:
968 unsigned long reclaim_clean_pages_from_list(struct zone *zone, 969 struct list_head *page_list) 970 { 971 struct scan_control sc = { 972 .gfp_mask = GFP_KERNEL, 973 .priority = DEF_PRIORITY, 974 .may_unmap = 1, 975 }; 976 unsigned long ret, dummy1, dummy2; 977 struct page *page, *next; 978 LIST_HEAD(clean_pages); 979 980 list_for_each_entry_safe(page, next, page_list, lru) { 981 if (page_is_file_cache(page) && !PageDirty(page)) { 982 ClearPageActive(page); 983 list_move(&page->lru, &clean_pages); 984 } 985 } 986 987 ret = shrink_page_list(&clean_pages, zone, &sc, 988 TTU_UNMAP|TTU_IGNORE_ACCESS, 989 &dummy1, &dummy2, true); 990 list_splice(&clean_pages, page_list); 991 __mod_zone_page_state(zone, NR_ISOLATED_FILE, -ret); 992 return ret; 993 }
在該函數中,對於那些用於文件緩存的頁,如果是乾淨的,就進行直接回收(981~989行),下次該內容需要被用到,再次從文件中讀取就是了。如果由於一些原因不能被回收掉的,那就掛回cc->migratepages鏈表上進行遷移(990行)。
遷移頁的流程如下:
dma_alloc_from_contiguous-> dma_alloc_from_contiguous-> __alloc_contig_migrate_range-> migrate_pages:
988 1007 int migrate_pages(struct list_head *from, new_page_t get_new_page, 1008 unsigned long private, enum migrate_mode mode, int reason) 1009 { 1010 int retry = 1; 1011 int nr_failed = 0; 1012 int nr_succeeded = 0; 1013 int pass = 0; 1014 struct page *page; 1015 struct page *page2; 1016 int swapwrite = current->flags & PF_SWAPWRITE; 1017 int rc; 1018 1019 if (!swapwrite) 1020 current->flags |= PF_SWAPWRITE; 1021 1022 for(pass = 0; pass < 10 && retry; pass++) { 1023 retry = 0; 1024 1025 list_for_each_entry_safe(page, page2, from, lru) { 1026 cond_resched(); 1027 1028 rc = unmap_and_move(get_new_page, private, 1029 page, pass > 2, mode); 1030 1031 switch(rc) { 1032 case -ENOMEM: 1033 goto out; 1034 case -EAGAIN: 1035 retry++; 1036 break; 1037 case MIGRATEPAGE_SUCCESS: 1038 nr_succeeded++; 1039 break; 1040 default: 1041 1042 nr_failed++; 1043 break; 1044 } 1045 } 1046 } 1047 rc = nr_failed + retry; 1048 out: 1049 if (nr_succeeded) 1050 count_vm_events(PGMIGRATE_SUCCESS, nr_succeeded); 1051 if (nr_failed) 1052 count_vm_events(PGMIGRATE_FAIL, nr_failed); 1053 trace_mm_migrate_pages(nr_succeeded, nr_failed, mode, reason); 1054 1055 if (!swapwrite) 1056 current->flags &= ~PF_SWAPWRITE; 1057 1058 return rc; 1059 }
該函數最重要的一句是1028行的unmap_and_move. 通過get_new_page新分配一個頁,然後將內容move過去,並進行unmap.
dma_alloc_from_contiguous-> dma_alloc_from_contiguous-> __alloc_contig_migrate_range-> migrate_pages-> unmap_and_move:
858 862 static int unmap_and_move(new_page_t get_new_page, unsigned long private, 863 struct page *page, int force, enum migrate_mode mode) 864 { 865 int rc = 0; 866 int *result = NULL; 867 struct page *newpage = get_new_page(page, private, &result); 868 869 if (!newpage) 870 return -ENOMEM; 871 872 if (page_count(page) == 1) { 873 874 goto out; 875 } 876 877 if (unlikely(PageTransHuge(page))) 878 if (unlikely(split_huge_page(page))) 879 goto out; 880 881 rc = __unmap_and_move(page, newpage, force, mode); 882 883 if (unlikely(rc == MIGRATEPAGE_BALLOON_SUCCESS)) { 884 889 dec_zone_page_state(page, NR_ISOLATED_ANON + 890 page_is_file_cache(page)); 891 balloon_page_free(page); 892 return MIGRATEPAGE_SUCCESS; 893 } 894 out: 895 if (rc != -EAGAIN) { 896 902 list_del(&page->lru); 903 dec_zone_page_state(page, NR_ISOLATED_ANON + 904 page_is_file_cache(page)); 905 putback_lru_page(page); 906 } 907 911 putback_lru_page(newpage); 912 if (result) { 913 if (rc) 914 *result = rc; 915 else 916 *result = page_to_nid(newpage); 917 } 918 return rc; 919 }
該函數是先進行unmap,然後再進行move(881行),這個move實際上是一個copy動作(__unmap_and_move->move_to_new_page->migrate_page->migrate_page_copy)。隨後將遷移后老頁釋放到buddy系統中(905行)。
至此,CMA分配一段連續空閑物理內存的準備工作已經做完了(已經將連續的空閑物理內存放在一張鏈表上了cc->freepages)。但這段物理頁還在buddy 系統上。因此,需要把它們從buddy 系統上摘除下來。摘除的操作並不通過通用的alloc_pages流程,而是手工進行處理(dma_alloc_from_contiguous-> dma_alloc_from_contiguous –>isolate_freepages_range)。在處理的時候,需要將連續的物理塊進行打散(order為N->order為0),並將物理塊打頭的頁的page->lru從buddy的鏈表上取下。設置連續物理頁塊中的每一個物理頁的struct page結構(split_free_page函數),設置其在zone->pageblock_flags遷移屬性為MIGRATE_CMA。
釋放的流程比較簡單。同分配一樣,釋放CMA的介面直接給dma。比如,dma_free_coherent。它會最終調用到CMA中的釋放介面:free_contig_range。
6035 void free_contig_range(unsigned long pfn, unsigned nr_pages) 6036 { 6037 unsigned int count = 0; 6038 6039 for (; nr_pages--; pfn++) { 6040 struct page *page = pfn_to_page(pfn); 6041 6042 count += page_count(page) != 1; 6043 __free_page(page); 6044 } 6045 WARN(count != 0, "%d pages are still in use!\n", count); 6046 }
直接遍歷每一個物理頁將其釋放到buddy系統中便是了(6039~6044行)。
CMA的使用避免了因內存預留給指定驅動而減少了系統可用內存的缺點。其CMA內存在驅動不用的時候可以分配給用戶進程使用,而當其需要被驅動用作DMA傳輸時,將之前分配給用戶進程的內存通過回收或者遷移的方式騰給驅動使用。