共找到4條詞條名為ioc的結果 展開
- 初始作戰能力
- 面向對象編程中的設計原則
- 監視並管理城市服務的運行中心
- 政府間海洋學委員會簡稱
ioc
面向對象編程中的設計原則
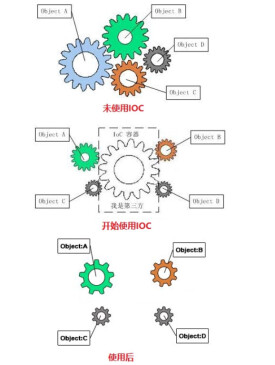
控制反轉(Inversion of Control,縮寫為IoC),是面向對象編程中的一種設計原則,可以用來減低計算機代碼之間的耦合度。其中最常見的方式叫做依賴注入(Dependency Injection,簡稱DI),還有一種方式叫“依賴查找”(Dependency Lookup)。通過控制反轉,對象在被創建的時候,由一個調控系統內所有對象的外界實體將其所依賴的對象的引用傳遞給它。也可以說,依賴被注入到對象中。
早在2004年,Martin Fowler就提出了“哪些方面的控制被反轉了?”這個問題。他總結出是依賴對象的獲得被反轉了,因為大多數應用程序都是由兩個或是更多的類通過彼此的合作來實現企業邏輯,這使得每個對象都需要獲取與其合作的對象(也就是它所依賴的對象)的引用。如果這個獲取過程要靠自身實現,那麼這將導致代碼高度耦合並且難以維護和調試。
Class A中用到了Class B的對象b,一般情況下,需要在A的代碼中顯式的new一個B的對象。
採用依賴注入技術之後,A的代碼只需要定義一個私有的B對象,不需要直接new來獲得這個對象,而是通過相關的容器控制程序來將B對象在外部new出來並注入到A類里的引用中。而具體獲取的方法、對象被獲取時的狀態由配置文件(如XML)來指定。
IoC可以認為是一種全新的 設計模式,但是理論和時間成熟相對較晚,並沒有包含在GoF中。
Interface Driven Design介面驅動,介面驅動有很多好處,可以提供不同靈活的子類實現,增加代碼穩定和健壯性等等,但是介面一定是需要實現的,也就是如下語句遲早要執行:AInterface a = new AInterfaceImp(); 這樣一來,耦合關係就產生了,如:
Class A與AInterfaceImp就是依賴關係,如果想使用AInterface的另外一個實現就需要更改代碼了。當然我們可以建立一個Factory來根據條件生成想要的AInterface的具體實現,即:
表面上是在一定程度上緩解了以上問題,但實質上這種代碼耦合併沒有改變。通過IoC模式可以徹底解決這種耦合,它把耦合從代碼中移出去,放到統一的XML 文件中,通過一個容器在需要的時候把這個依賴關係形成,即把需要的介面實現注入到需要它的類中,這可能就是“依賴注入”說法的來源了。
IoC模式,系統中通過引入實現了IoC模式的IoC容器,即可由IoC容器來管理對象的生命周期、依賴關係等,從而使得應用程序的配置和依賴性規範與實際的應用程序代碼分離。其中一個特點就是通過文本的配置文件進行應用程序組件間相互關係的配置,而不用重新修改並編譯具體的代碼。
可以把IoC模式看作工廠模式的升華,把IoC容器看作是一個大工廠,只不過這個大工廠里要生成的對象都是在XML文件中給出定義的。利用Java 的“反射”編程,根據XML中給出的類定義生成相應的對象。從實現來看,以前在工廠模式里寫死了的對象,IoC模式改為配置XML文件,這就把工廠和要生成的對象兩者隔離,極大提高了靈活性和可維護性。
IoC中最基本的Java技術就是“反射”編程。通俗的說,反射就是根據給出的類名(字元串)來生成對象。這種編程方式可以讓應用在運行時才動態決定生成哪一種對象。反射的應用是很廣泛的,像Hibernate、Spring中都是用“反射”做為最基本的技術手段。
在過去,反射編程方式相對於正常的對象生成方式要慢10幾倍,這也許也是當時為什麼反射技術沒有普遍應用開來的原因。但經SUN改良優化后,反射方式生成對象和通常對象生成方式,速度已經相差不大了(但依然有一倍以上的差距)。
現有的框架實際上使用以下三種基本技術的框架執行服務和部件間的綁定:
● ● 類型1 (基於介面): 可服務的對象需要實現一個專門的介面,該介面提供了一個對象,可以重用這個對象查找依賴(其它服務)。早期的容器Excalibur使用這種模式。
● ● 類型2 (基於setter): 通過JavaBean的屬性(setter方法)為可服務對象指定服務。HiveMind和Spring採用這種方式。
● ● 類型3 (基於構造函數): 通過構造函數的參數為可服務對象指定服務。PicoContainer只使用這種方式。HiveMind和Spring也使用這種方式。
IoC是一個很大的概念,可以用不同的方式實現。其主要形式有兩種:
• 依賴查找:容器提供回調介面和上下文條件給組件。EJB和Apache Avalon 都使用這種方式。這樣一來,組件就必須使用容器提供的API來查找資源和協作對象,僅有的控制反轉只體現在那些回調方法上(也就是上面所說的 類型1):容器將調用這些回調方法,從而讓應用代碼獲得相關資源。
• 依賴注入:組件不做定位查詢,只提供普通的Java方法讓容器去決定依賴關係。容器全權負責的組件的裝配,它會把符合依賴關係的對象通過JavaBean屬性或者構造函數傳遞給需要的對象。通過JavaBean屬性注射依賴關係的做法稱為設值方法注入(Setter Injection);將依賴關係作為構造函數參數傳入的做法稱為構造器注入(Constructor Injection)
實現數據訪問層
數據訪問層有兩個目標。第一是將資料庫引擎從應用中抽象出來,這樣就可以隨時改變資料庫—比方說,從微軟SQL變成Oracle。不過在實踐上很少會這麼做,也沒有足夠的理由和能力去通過使用實現數據訪問層而對現有的應用進行重構。
第二個目標是將數據模型從資料庫實現中抽象出來。這使得資料庫或代碼開源根據需要改變,同時只會影響主應用的一小部分——數據訪問層。這一目標是值得的,為了在現有系統中實現它進行必要的重構。
模塊與介面重構
依賴注入背後的一個核心思想是單一功能原則(single responsibility principle)。該原則指出,每一個對象應該有一個特定的目的,而應用需要利用這一目的的不同部分應當使用合適的對象。這意味著這些對象在系統的任何地方都可以重用。但在現有系統裡面很多時候都不是這樣的。
隨時增加單元測試
把功能封裝到整個對象裡面會導致自動測試困難或者不可能。將模塊和介面與特定對象隔離,以這種方式重構可以執行更先進的單元測試。按照後面再增加測試的想法繼續重構模塊是誘惑力的,但這是錯誤的。
使用服務定位器而不是構造注入
實現控制反轉不止一種方法。最常見的辦法是使用構造注入,這需要在對象首次被創建時提供所有的軟體依賴。然而,構造注入要假設整個系統都使用這一模式,這意味著整個系統必須同時進行重構。這很困難、有風險,且耗時。
基本信息
- 中文名
- 控制反轉
- 別名
- ioc
- 外文名
- Inversion of Control
- 目的
- 描述框架的重要特徵
- 起源時間
- 1988年
- 實現策略
- 依賴查找、依賴注入