共找到4條詞條名為hive的結果 展開
- 數據倉庫工具
- 噬神者中術語
- Windows註冊表HIVE文件
- APP
hive
數據倉庫工具
hive是基於Hadoop的一個數據倉庫工具,用來進行數據提取、轉化、載入,這是一種可以存儲、查詢和分析存儲在Hadoop中的大規模數據的機制。hive數據倉庫工具能將結構化的數據文件映射為一張資料庫表,並提供SQL查詢功能,能將SQL語句轉變成MapReduce任務來執行。Hive的優點是學習成本低,可以通過類似SQL語句實現快速MapReduce統計,使MapReduce變得更加簡單,而不必開發專門的MapReduce應用程序。hive十分適合對數據倉庫進行統計分析。
hive是基於Hadoop構建的一套數據倉庫分析系統,它提供了豐富的SQL查詢方式來分析存儲在Hadoop分散式文件系統中的數據:可以將結構化的數據文件映射為一張資料庫表,並提供完整的SQL查詢功能;可以將SQL語句轉換為MapReduce任務運行,通過自己的SQL查詢分析需要的內容,這套SQL簡稱Hive SQL,使不熟悉mapreduce的用戶可以很方便地利用SQL語言查詢、匯總和分析數據。而mapreduce開發人員可以把自己寫的mapper和reducer作為插件來支持hive做更複雜的數據分析。它與關係型資料庫的SQL略有不同,但支持了絕大多數的語句如DDL、DML以及常見的聚合函數、連接查詢、條件查詢。它還提供了一系列的工具進行數據提取轉化載入,用來存儲、查詢和分析存儲在Hadoop中的大規模數據集,並支持UDF(User-Defined Function)、UDAF(User-Defnes AggregateFunction)和UDTF(User-Defined Table-Generating Function),也可以實現對map和reduce函數的定製,為數據操作提供了良好的伸縮性和可擴展性。
hive不適合用於聯機(online)事務處理,也不提供實時查詢功能。它最適合應用在基於大量不可變數據的批處理作業。hive的特點包括:可伸縮(在Hadoop的集群上動態添加設備)、可擴展、容錯、輸入格式的鬆散耦合。
Hive 構建在基於靜態批處理的Hadoop 之上,Hadoop 通常都有較高的延遲並且在作業提交和調度的時候需要大量的開銷。因此,Hive 並不能夠在大規模數據集上實現低延遲快速的查詢,例如,Hive 在幾百MB 的數據集上執行查詢一般有分鐘級的時間延遲。
因此,Hive 並不適合那些需要低延遲的應用,例如,聯機事務處理(OLTP)。Hive 查詢操作過程嚴格遵守Hadoop MapReduce 的作業執行模型,Hive 將用戶的HiveQL 語句通過解釋器轉換為MapReduce 作業提交到Hadoop 集群上,Hadoop 監控作業執行過程,然後返回作業執行結果給用戶。Hive 並非為聯機事務處理而設計,Hive 並不提供實時的查詢和基於行級的數據更新操作。Hive 的最佳使用場合是大數據集的批處理作業,例如,網路日誌分析。
Hive 是一種底層封裝了Hadoop 的數據倉庫處理工具,使用類SQL 的HiveQL 語言實現數據查詢,所有Hive 的數據都存儲在Hadoop 兼容的文件系統(例如,Amazon S3、HDFS)中。Hive 在載入數據過程中不會對數據進行任何的修改,只是將數據移動到HDFS 中Hive 設定的目錄下,因此,Hive 不支持對數據的改寫和添加,所有的數據都是在載入的時候確定的。Hive 的設計特點如下。
● 支持索引,加快數據查詢。
● 不同的存儲類型,例如,純文本文件、HBase 中的文件。
● 將元數據保存在關係資料庫中,大大減少了在查詢過程中執行語義檢查的時間。
● 可以直接使用存儲在Hadoop 文件系統中的數據。
● 內置大量用戶函數UDF 來操作時間、字元串和其他的數據挖掘工具,支持用戶擴展UDF 函數來完成內置函數無法實現的操作。
● 類SQL 的查詢方式,將SQL 查詢轉換為MapReduce 的job 在Hadoop集群上執行。
主要分為以下幾個部分:
用戶介面
用戶介面主要有三個:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 啟動的時候,會同時啟動一個 Hive 副本。Client 是 Hive 的客戶端,用戶連接至 Hive Server。在啟動 Client 模式的時候,需要指出 Hive Server 所在節點,並且在該節點啟動 Hive Server。 WUI 是通過瀏覽器訪問 Hive。
元數據存儲
Hive 將元數據存儲在資料庫中,如 mysql、derby。Hive 中的元數據包括表的名字,表的列和分區及其屬性,表的屬性(是否為外部表等),表的數據所在目錄等。
解釋器、編譯器、優化器、執行器
解釋器、編譯器、優化器完成HQL 查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在 HDFS 中,並在隨後由 MapReduce 調用執行。
Hadoop
Hive 的數據存儲在 HDFS 中,大部分的查詢由 MapReduce 完成(不包含 * 的查詢,比如 select * from tbl 不會生成 MapReduce 任務)。
首先,Hive 沒有專門的數據存儲格式,也沒有為數據建立索引,用戶可以非常自由的組織 Hive 中的表,只需要在創建表的時候告訴 Hive 數據中的列分隔符和行分隔符,Hive 就可以解析數據。
其次,Hive 中所有的數據都存儲在 HDFS 中,Hive 中包含以下數據模型:表(Table),外部表(External Table),分區(Partition),桶(Bucket)。
Hive 中的 Table 和資料庫中的 Table 在概念上是類似的,每一個 Table 在 Hive 中都有一個相應的目錄存儲數據。例如,一個表 pvs,它在 HDFS 中的路徑為:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的數據倉庫的目錄,所有的 Table 數據(不包括 External Table)都保存在這個目錄中。
Partition 對應於資料庫中的 Partition 列的密集索引,但是 Hive 中 Partition 的組織方式和資料庫中的很不相同。在 Hive 中,表中的一個 Partition 對應於表下的一個目錄,所有的 Partition 的數據都存儲在對應的目錄中。例如:pvs 表中包含 ds 和 city 兩個 Partition,則對應於 ds = 20090801, city = US 的 HDFS 子目錄為:/wh/pvs/ds=20090801/city=US;對應於 ds = 20090801, city = CA 的 HDFS 子目錄為;/wh/pvs/ds=20090801/city=CA
Buckets 對指定列計算 hash,根據 hash 值切分數據,目的是為了并行,每一個 Bucket 對應一個文件。將 user 列分散至 32 個 bucket,首先對 user 列的值計算 hash,對應 hash 值為 0 的 HDFS 目錄為:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值為 20 的 HDFS 目錄為:/wh/pvs/ds=20090801/ctry=US/part-00020
External Table 指向已經在 HDFS 中存在的數據,可以創建 Partition。它和 Table 在元數據的組織上是相同的,而實際數據的存儲則有較大的差異。
Table 的創建過程和數據載入過程(這兩個過程可以在同一個語句中完成),在載入數據的過程中,實際數據會被移動到數據倉庫目錄中;之後對數據對訪問將會直接在數據倉庫目錄中完成。刪除表時,表中的數據和元數據將會被同時刪除。
● External Table 只有一個過程,載入數據和創建表同時完成(CREATE EXTERNAL TABLE ……LOCATION),實際數據是存儲在 LOCATION 後面指定的 HDFS 路徑中,並不會移動到數據倉庫目錄中。當刪除一個 External Table 時,僅刪除元數據,表中的數據不會真正被刪除。
你可以下載一個已打包好的hive穩定版,也可以下載源碼自己build一個版本。
安裝需要
● ● java 1.6,java 1.7或更高版本。
● ● Hadoop 2.x或更高, 1.x. Hive 0.13 版本也支持 0.20.x, 0.23.x
● ● Linux,mac,windows操作系統。以下內容適用於linux系統。
安裝打包好的hive
需要先到apache下載已打包好的hive鏡像,然後解壓開該文件
$ tar -xzvf hive-x.y.z.tar.gz
設置hive環境變數
$ cd hive-x.y.z$ export HIVE_HOME={{pwd}}
設置hive運行路徑
$ export PATH=$HIVE_HOME/bin:$PATH
編譯Hive源碼
下載hive源碼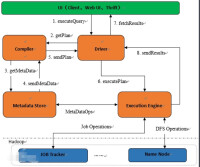 此處使用maven編譯,需要下載安裝maven。
此處使用maven編譯,需要下載安裝maven。
hive
以Hive 0.13版為例
● ● 編譯hive 0.13源碼基於hadoop 0.23或更高版本$cdhive$mvncleaninstall-Phadoop-2,dist$cdpackaging/target/apache-hive-{version}-SNAPSHOT-bin/apache-hive-{version}-SNAPSHOT-bin$lsLICENSENOTICEREADME.txtRELEASE_NOTES.txtbin/(alltheshellscripts)lib/(requiredjarfiles)conf/(configurationfiles)examples/(sampleinputandqueryfiles)hcatalog/(hcataloginstallation)scripts/(upgradescriptsforhive-metastore)
● ● 編譯hive 基於hadoop 0.20$cdhive$antcleanpackage$cdbuild/dist#lsLICENSENOTICEREADME.txtRELEASE_NOTES.txtbin/(alltheshellscripts)lib/(requiredjarfiles)conf/(configurationfiles)examples/(sampleinputandqueryfiles)hcatalog/(hcataloginstallation)scripts/(upgradescriptsforhive-metastore)
運行hive
Hive運行依賴於hadoop,在運行hadoop之前必需先配置好hadoopHome。
export HADOOP_HOME=
在hdfs上為hive創建\tmp目錄和/user/hive/warehouse(akahive.metastore.warehouse.dir) 目錄,然後你才可以運行hive。
在運行hive之前設置HiveHome。
$ export HIVE_HOME=
在命令行窗口啟動hive
$ $HIVE_HOME/bin/hive
1、join連接時的優化:當三個或多個以上的表進行join操作時,如果每個on使用相同的欄位連接時只會產生一個mapreduce。
2、join連接時的優化:當多個表進行查詢時,從左到右表的大小順序應該是從小到大。原因:hive在對每行記錄操作時會把其他表先緩存起來,直到掃描最後的表進行計算
3、在where字句中增加分區過濾器。
4、當可以使用left semi join 語法時不要使用inner join,前者效率更高。原因:對於左表中指定的一條記錄,一旦在右表中找到立即停止掃描。
5、如果所有表中有一張表足夠小,則可置於內存中,這樣在和其他表進行連接的時候就能完成匹配,省略掉reduce過程。設置屬性即可實現,set hive.auto.covert.join=true; 用戶可以配置希望被優化的小表的大小 set hive.mapjoin.smalltable.size=2500000; 如果需要使用這兩個配置可置入$HOME/.hiverc文件中。
6、同一種數據的多種處理:從一個數據源產生的多個數據聚合,無需每次聚合都需要重新掃描一次。
例如:insert overwrite table student select * from employee; insert overwrite table person select * from employee;
可以優化成:from employee insert overwrite table student select * insert overwrite table person select *
7、limit調優:limit語句通常是執行整個語句后返回部分結果。set hive.limit.optimize.enable=true;
8、開啟併發執行。某個job任務中可能包含眾多的階段,其中某些階段沒有依賴關係可以併發執行,開啟併發執行后job任務可以更快的完成。設置屬性:set hive.exec.parallel=true;
9、hive提供的嚴格模式,禁止3種情況下的查詢模式。
a:當表為分區表時,where字句后沒有分區欄位和限制時,不允許執行。
b:當使用order by語句時,必須使用limit欄位,因為order by 只會產生一個reduce任務。
c:限制笛卡爾積的查詢。
10、合理的設置map和reduce數量。
11、jvm重用。可在hadoop的mapred-site.xml中設置jvm被重用的次數。

基本信息
- 外文名
- hive
- 定義
- 在 Hadoop 上的數據倉庫基礎構架
- 依賴
- jdk,hadoop
- 兼容性
- hadoop生態圈
- 所屬學科
- 大數據 數據分析