加法器
加法器
加法器是產生數的和的裝置。加數和被加數為輸入,和數與進位為輸出的裝置為半加器。若加數、被加數與低位的進位數為輸入,而和數與進位為輸出則為全加器。常用作計算機算術邏輯部件,執行邏輯操作、移位與指令調用。在電子學中,加法器是一種數位電路,其可進行數字的加法計算。三碼,主要的加法器是以二進位作運算。由於負數可用二的補數來表示,所以加減器也就不那麼必要。
加法器是為了實現加法的。
即是產生數的和的裝置。
對於1位的二進位加法,相關的有五個的量:1,被加數A,2,加數B,3,前一位的進位CIN,4,此位二數相加的和S,5,此位二數相加產生的進位COUT。前三個量為輸入量,后兩個量為輸出量,五個量均為1位。
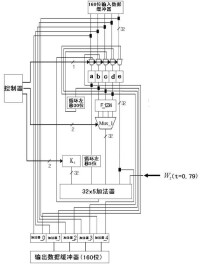
對於32位的二進位加法,相關的也有五個量:1,被加數A(32位),2,加數B(32位),3,前一位的進位CIN(1位),4,此位二數相加的和S(32位),5,此位二數相加產生的進位COUT(1位)。
要實現32位的二進位加法,一種自然的想法就是將1位的二進位加法重複32次(即逐位進位加法器)。這樣做無疑是可行且易行的,但由於每一位的CIN都是由前一位的COUT提供的,所以第2位必須在第1位計算出結果后,才能開始計算;第3位必須在第2位計算出結果后,才能開始計算,等等。而最後的第32位必須在前31位全部計算出結果后,才能開始計算。這樣的方法,使得實現32位的二進位加法所需的時間是實現1位的二進位加法的時間的32倍。
可以看出,上法是將32位的加法1位1位串列進行的,要縮短進行的時間,就應設法使上敘進行過程并行化。
加法器
進一步分析加法進行的機制,可以使加法器的結構進一步并行化。
令G = AB,P = A⊕B,則COUT(G,P) = G + PCIN,S(G,P)=P⊕CIN。由此,A,B,CIN,S,COUT五者的關係,變為了G,P,CIN,S,COUT五者的關係。
再定義點運算(·),(G,P)·(G’,P’)=(G + PG’,PP’),可以分解(G 3:2,P3:2) =(G3,P3)·(G2,P2)。點運算服從結合律,但不符合交換律。
點運算只與G,P有關而與CIN無關,也就是可以通過只對前面若干位G,P進行點運算計算,就能得到第N位的GN:M,PN:M值,當取M為0時,獲得的GN:0,PN:0即可與初使的CIN一起代入COUT(G,P) = G + PCIN,S(G,P)=P⊕CIN,得到此位的COUT,S;而每一位的G,P值又只與該位的A,B值即輸入值有關,所以在開始進行運算后,就能并行的得到每一位的G,P值。
以上分析產生了超前進位加法器的思想:三步運算,1,由輸入的A,B算出每一位的G,P;2,由各位的G,P算出每一位的GN:0,PN:0;3,由每一位的GN:0,PN:0與CIN算出每一位的COUT,S。其中第1,3步顯然是可以并行處理的,計算的主要複雜度集中在了第2步。
第2步的并行化,也就是實現GN:0,PN:0的點運算分解的并行化。
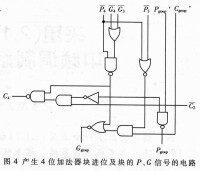
設一個n位的加法器的第i位輸入為ai、bi、ci,輸出si和ci+1,其中ci是低位來的進位,ci+1(i=n-1,n-2,…,1,0)是向高位的進位,c0是整個加法器的進位輸入,而cn是整個加法器的進位輸出。則和
si=aiii+ibii+iici+aibici ,(1) 進位ci+1=aibi+aici+bici ,(2)
令 gi=aibi, (3)
pi=ai+bi, (4)
則 ci+1= gi+pici, (5)
只要aibi=1,就會產生向i+1位的進位,稱g為進位產生函數;同樣,只要ai+bi=1,就會把ci傳遞到i+1位,所以稱p為進位傳遞函數。把式(5)展開,得到:ci+1= gi+ pigi-1+pipi-1gi-2+…+ pipi-1…p1g0+ pipi-1…p0c0(6)。
隨著位數的增加式(6)會加長,但總保持三個邏輯級的深度,因此形成進位的延遲是與位數無關的常數。一旦進位(c1~cn-1)算出以後,和也就可由式(1)得出。
使用上述公式來并行產生所有進位的加法器就是超前進位加法器。產生gi和pi需要一級門延遲,ci 需要兩級,si需要兩級,總共需要五級門延遲。與串聯加法器(一般要2n級門延遲)相比,(特別是n比較大的時候)超前進位加法器的延遲時間大大縮短了。
加法器
全加器引入了進位值的輸入,以計算較大的數。為區分全加器的兩個進位線,在輸入端的記作 Ci 或 Cin,在輸出端的則記作 Co 或 Cout。半加器簡寫為 H.A.,全加器簡寫為 F.A.。
半加器:半加器的電路圖半加器有兩個二進位的輸入,其將輸入的值相加,並輸出結果到和(Sum)和進位(Carry)。半加器雖能產生進位值,但半加器本身並不能處理進位值。
全加器:全加器三個二進位的輸入,其中一個是進位值的輸入,所以全加器可以處理進位值。全加器可以用兩個半加器組合而成。
注意,進位輸出端的最末個OR閘,也可用XOR閘來代替,且無需更改其餘的部分。因為 OR 閘和 XOR 閘只有當輸入皆為 1 時才有差別,而這個可能性已不存在。
直接使用式(6)形成的電路是不規則的,並且需要長線驅動,需要大驅動信號和大扇入門。當位數較多時,這種實現方式不太現實。
加法器
每個4位的CLA模塊分別計算各組內每一位的p、 g和組間的P、G,第二級LACG(look ahead carry generator)根據各組(包含第一級LACG邏輯)的P、G和c0計算出各組間的進位C4k+4 ,同樣,第三級LACG則根據第二級的P、G和c0計算出向高4組的進位C16k+16,依此類推。計算出的所有組進位都要送回各個4位的CLA模塊,并行算出每一位的和。
改造后,CLA的延時包括:用式(3)和式(4)產生pi和gi的1級門延時;用超前進位電路產生所有進位的2(2L-1)級門延時;用 (1) 式計算si的2級門延時。於是總的延時為[2] :
Delay(CLA adder)=1+4Log4(n) (7)
與簡單的串聯加法器相比,超前進位加法器需要較多的邏輯電路來產生進位位。但它的延遲時間的數量級為log4(n)。當n較大時,速度的改進是很明顯的。
邏輯優化設計的主要目的是減少信號的翻轉活動[3],它通過將電路的邏輯功能儘可能的分解、優化,減少邏輯深度,減少信號假翻轉,從而使翻轉活動最小,減小電路的功耗。
令gsi=ai⊙bi ,則式(1)可以改寫為si= gsi⊙ci ,先考察第一組CLA
s0=gs0⊙c0 (8)
s1=gs1⊙c1=gs1⊙(g0+p0c0) (9)
s2=gs2⊙c2=gs2⊙(g1+p1g0+p1p0c0) (10)
s3=gs3⊙c3=gs3⊙(g2+p2g1+p2p1g0+p2p1p0c0)(11)
因為g, p的值只有“00”、“01”、“11”這三種組合,結合布爾代數性質A⊙0=、A⊙1=A可知,s3的值最終可以歸結為3個表達式:gs3, 3和(gs3⊙c0),同樣,s2值的3個表達式為gs2, 2和(gs2⊙c0),s1為gs1, 1和(gs1⊙c0)。於是式(8)至式(11)就可以化為
s0=c0(gs0)+ 0 (0) (12)
s1=c0(gs1⊙p0)+0(gs1⊙g0) (13)
s2=c0(gs2⊙(g1+p1p0))+ 0 (gs2⊙(g1+p1g0))(14)
s3=c0(gs3⊙(g2+p2g1+p2p1p0))
+0(gs3⊙(g2+p2g1+p2p1g0)) (15)
其他組,如s4~s7、s8~s11等,情況和s0~s3一樣。
邏輯改造后,在進位產生邏輯上可以減少一些不必要的翻轉,減少了節點開關活動率,並且可以重複利用g,p積之和的相同部分,達到路徑平衡的效果,可以有效地消除假翻轉(glitch),同時與門和或門的最大扇入都減少了一個,較大程度地減小了功耗。
邏輯改造后,電路也應該相應地進行優化設計,因為如果用普通的門電路來實現式(12)~(15)的邏輯,晶體管數目(面積)會增加。另外,在電路級也可以採用減少節點翻轉和寄生電容的方法來降低功耗。

加法器
加法器電路上的延遲值
旁路邏輯不能實現傳輸門,因而不能用傳輸門實現同或和異或,但是容易證明,三態門在速度和功耗方面都比傳輸門優越。參照傳輸門的結合方式,我們用兩個三態反相器和一個反相器實現了同或門。
實現了式(13)括弧內的兩個同或邏輯,平均只需要1級門延時,而用普通門實現的“與非或與非”形式的同或門需要2級或3級門延時。由上面的同或門設計得到啟發,根據形如式(13)的邏輯,設計了一個10管單元utiandor2。
該單元電路實現s=c0CK+0CKN,只要把式(12)~(15)中的括弧部分從CK和CKN輸入,輸出就相應得到了s0~ s3。僅當CKN=時,電路(a)兩邊均是三態反相器,構成圖5(b)的同或門,兩個反相器交替導通,s=c0⊙CK ;當CKN=CK(發生幾率比較大),左邊P管和右邊N管,或者左邊N管和右邊P管交替導通,輸出s=CK,從而屏蔽了c0的變化。考察第一組4位CLA中的進位產生邏輯最複雜的s3,參考式(15),當g2,g1,g0均為0,p2,p1,p0均為1時,s3= gs3⊙c0,顯然這是一種特殊情況,即低位各位都不產生進位,但可以傳遞進位時,直接把c0傳至高位與gs同或即可產生和。c0在各位和生成邏輯的最後一級才加入,可以消除過早加入帶來的不必要的翻轉。左右兩塊交替導通,只存在下拉或上拉延時,有類似動態電路延遲小的優點。僅用了10個晶體管,比常規門實現的積之和節省8個。
基本信息
- 中文名
- 加法器
- 外文名
- Adder
- 原理
- BCD、加三碼
- 電子產品類別
- 一種數位電路
- 用途
- 產生數的和
- 出入
- 加數和被加數
- 定義
- 產生數的和的裝置