Swap分區
用於釋放物理內存的交換區
Swap分區在系統的物理內存不夠用的時候,把物理內存中的一部分空間釋放出來,以供當前運行的程序使用。那些被釋放的空間可能來自一些很長時間沒有什麼操作的程序,這些被釋放的空間被臨時保存到Swap分區中,等到那些程序要運行時,再從Swap分區中恢復保存的數據到內存中。
Swap分區,即交換區,系統在物理內存不夠時,與Swap進行交換。其實,Swap的調整對Linux伺服器,特別是Web伺服器的性能至關重要。通過調整Swap,有時可以越過系統性能瓶頸,節省系統升級費用。
眾所周知,現代操作系統都實現了“虛擬內存”這一技術,不但在功能上突破了物理內存的限制,使程序可以操縱大於實際物理內存的空間,更重要的是,“虛擬內存”是隔離每個進程的安全保護網,使每個進程都不受其它程序的干擾。
計算機用戶會經常遇這種現象。例如,在使用Windows系統時,可以同時運行多個程序,當你切換到一個很長時間沒有理會的程序時,會聽到硬碟“嘩嘩”直響。這是因為這個程序的內存被那些頻繁運行的程序給“偷走”了,放到了Swap區中。因此,一旦此程序被放置到前端,它就會從Swap區取回自己的數據,將其放進內存,然後接著運行。
需要說明一點,並不是所有從物理內存中交換出來的數據都會被放到Swap中(如果這樣的話,Swap就會不堪重負),有相當一部分數據被直接交換到文件系統。例如,有的程序會打開一些文件,對文件進行讀寫(其實每個程序都至少要打開一個文件,那就是運行程序本身),當需要將這些程序的內存空間交換出去時,就沒有必要將文件部分的數據放到Swap空間中了,而可以直接將其放到文件里去。如果是讀文件操作,那麼內存數據被直接釋放,不需要交換出來,因為下次需要時,可直接從文件系統恢復;如果是寫文件,只需要將變化的數據保存到文件中,以便恢復。但是那些用malloc和new函數生成的對象的數據則不同,它們需要Swap空間,因為它們在文件系統中沒有相應的“儲備”文件,因此被稱作“匿名”(Anonymous)內存數據。這類數據還包括堆棧中的一些狀態和變數數據等。所以說,Swap空間是“匿名”數據的交換空間。
突破128M Swap限制
經常看到有些Linux(國內漢化版)安裝手冊上有這樣的說明:Swap空間不能超過128M。為什麼會有這種說法?在說明“128M”這個數字的來歷之前,先給問題一個回答:根本不存在128M的限制!限制是2G!
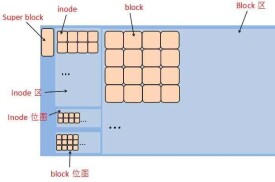
Swap空間是分頁的,每一頁的大小和內存頁的大小一樣,方便Swap空間和內存之間的數據交換。舊版本的Linux實現Swap空間時,用Swap空間的第一頁作為所有Swap空間頁的一個“位映射”(Bit map)。這就是說第一頁的每一位,都對應著一頁Swap空間。如果這一位是1,表示此頁Swap可用;如果是0,表示此頁是壞塊,不能使用。這麼說來,第一個Swap映射位應該是0,因為,第一頁Swap是映射頁。另外,最後10個映射位也被佔用,用來表示Swap的版本(原來的版本是Swap_space ,最新的版本是swapspace2)。那麼,如果說一頁的大小為s,這種Swap的實現方法共能管理“8 * ( s - 10 ) - 1”個Swap頁。對於i386系統來說s=4096,則空間大小共為133890048,如果認為1 MB=2^20 Byte的話,大小正好為128M。
之所以這樣來實現Swap空間的管理,是要防止Swap空間中有壞塊。如果系統檢查到Swap中有壞塊,則在相應的位映射上標記上0,表示此頁不可用。這樣在使用Swap時,不至於用到壞塊,而使系統產生錯誤。
系統設計者認為:
1.硬碟質量很好,壞塊很少。
2.就算有,也不多,只需要將壞塊羅列出來,而不需要為每一頁建立映射。
3.如果有很多壞塊,就不應該將此硬碟作為Swap空間使用。
於是,Linux取消了位映射的方法,也就取消了128M的限制。直接用地址訪問,限制為2G。
Swap配置對性能的影響
分配太多的Swap空間會浪費磁碟空間,而Swap空間太少,則系統會發生錯誤。
如果系統的物理內存用光了,系統就會跑得很慢,但仍能運行;如果Swap空間用光了,那麼系統就會發生錯誤。例如,Web伺服器能根據不同的請求數量衍生出多個服務進程(或線程),如果Swap空間用完,則服務進程無法啟動,通常會出現“application is out of memory”的錯誤,嚴重時會造成服務進程的死鎖。因此Swap空間的分配是很重要的。
通常情況下,Swap空間應大於或等於物理內存的大小,最小不應小於64M,通常Swap空間的大小應是物理內存的2-2.5倍。但根據不同的應用,應有不同的配置:如果是小的桌面系統,則只需要較小的Swap空間,而大的伺服器系統則視情況不同需要不同大小的Swap空間。特別是資料庫伺服器和Web伺服器,隨著訪問量的增加,對Swap空間的要求也會增加,具體配置參見各伺服器產品的說明。
另外,Swap分區的數量對性能也有很大的影響。因為Swap交換的操作是磁碟IO的操作,如果有多個Swap交換區,Swap空間的分配會以輪流的方式操作於所有的Swap,這樣會大大均衡IO的負載,加快Swap交換的速度。如果只有一個交換區,所有的交換操作會使交換區變得很忙,使系統大多數時間處於等待狀態,效率很低。用性能監視工具就會發現,此時的CPU並不很忙,而系統卻慢。這說明,瓶頸在IO上,依靠提高CPU的速度是解決不了問題的。
系統性能監視
最常用的是Vmstat命令(在大多數Unix平台下都有這樣一些命令),此命令可以查看大多數性能指標。例如:
# vmstat 3
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
****************************************************************
命令說明:
vmstat 後面的參數指定了性能指標捕獲的時間間隔。3表示每三秒鐘捕獲一次。第一行數據不用看,沒有價值,它僅反映開機以來的平均性能。從第二行開始,反映每三秒鐘之內的系統性能指標。這些性能指標中和Swap有關的包括以下幾項:
procs下的w
它表示當前(三秒鐘之內)需要釋放內存、交換出去的進程數量。
memory下的swpd
它表示使用的Swap空間的大小。
Swap下的si,so
si表示當前(三秒鐘之內)每秒交換回內存(Swap in)的總量,單位為kbytes;so表示當前(三秒鐘之內)每秒交換出內存(Swap out)的總量,單位為kbytes。
以上的指標數量越大,表示系統越忙。這些指標所表現的系統繁忙程度,與系統具體的配置有關。系統管理員應該在平時系統正常運行時,記下這些指標的數值,在系統發生問題的時候,再進行比較,就會很快發現問題,並制定本系統正常運行的標準指標值,以供性能監控使用。
另外,使用Swapon-s也能簡單地查看當前Swap資源的使用情況。例如:
# swapon -s
Filename Type Size Used Priority
/dev/hda9 partition 361420 0 3
能夠方便地看出Swap空間的已用和未用資源的大小。
應該使Swap負載保持在30%以下,這樣才能保證系統的良好性能。
增加Swap空間,分以下幾步:
1)成為超級用戶
$su - root
2)創建Swap文件
# dd if=/dev/zero of=swapfile bs=1024 count=65536
創建一個有連續空間的交換文件。
3)激活Swap文件
#/usr/sbin/swapon swapfile
swapfile指的是上一步創建的交換文件。
4)新加的Swap文件已經起作用了,但系統重新啟動以後,並不會記住前幾步的操作。因此要在/etc/fstab文件中記錄文件的名字,和Swap類型,如:
/path/swapfile none Swap sw,pri=3 0 0
5)檢驗Swap文件是否加上
/usr/sbin/swapon -s
刪除多餘的Swap空間。
1)成為超級用戶
2)使用Swapoff命令收回Swap空間。
#/usr/sbin/swapoff swapfile
3)編輯/etc/fstab文件,去掉此Swap文件的實體。
4)從文件系統中回收此文件。
#rm swapfile
5)當然,如果此Swap空間不是一個文件,而是一個分區,則需創建一個新的文件系統,再掛接到原來的文件系統上。
基本信息
- 中文名
- Swap分區
- 別名
- 交換區
- 特點
- 突破128M Swap限制
- 影響
- 分配太多浪費空間,太少系統錯誤
- 硬碟分區
- 主分區+擴展分區
- 基本分區
- 根分區和swap分區