離散化
離散化
離散化,把無限空間中無限的個體映射到有限的空間中去,以此提高演演算法的時空效率。
離散化是程序設計中一個非常常用的技巧,它可以有效的降低時間複雜度。其基本思想就是在眾多可能的情況中“只考慮我需要用的值”。離散化可以改進一個低效的演演算法,甚至實現根本不可能實現的演演算法。要掌握這個思想,必須從大量的題目中理解此方法的特點。
如果說今年這時候OIBH問得最多的問題是二分圖,那麼去年這時候問得最多的算是離散化了。對於“什麼是離散化”,搜索帖子你會發現有各種說法,比如“排序后處理”、“對坐標的近似處理”等等。哪個是對的呢?哪個都對。關鍵在於,這需要一些例子和不少的講解才能完全解釋清楚。
離散化是程序設計中一個非常常用的技巧,它可以有效的降低時間和空間複雜度。其基本思想就是在眾多可能的情況中“只考慮我需要用的值”。下面我將用三個例子說明,如何運用離散化改進一個低效的,甚至根本不可能實現的演演算法。
《演演算法藝術與信息學競賽》中的計算幾何部分,黃亮舉了一個經典的例子,我認為很適合用來介紹離散化思想。這個問題是UVA10173題目意思很簡單,給定平面上n個點的坐標,求能夠覆蓋所有這些點的最小矩形面積。這個問題難就難在,這個矩形可以傾斜放置(邊不必平行於坐標軸)。
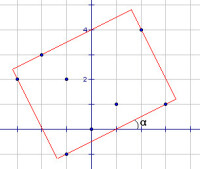
UVA10173
演演算法很顯然了:枚舉矩形的傾角,對於每一個傾角,我們都能計算出最小的矩形面積,最後取一個最小值。
這個演演算法是否是正確的呢?我們不能說它是否正確,因為它根本不可能實現。矩形的傾角是一個實數,它有無數種可能,你永遠不可能枚舉每一種情況。我們說,矩形的傾角是一個“連續的”變數,它是我們無法枚舉這個傾角的根本原因。我們需要一種方法,把這個“連續的”變數變成一個一個的值,變成一個“離散的”變數。這個過程也就是所謂的離散化。
可以證明,最小面積的矩形不但要求四條邊上都有一個點,而且還要求至少一條邊上有兩個或兩個以上的點。試想,如果每條邊上都只有一個點,則我們總可以把這個矩形旋轉一點使得這個矩形變“松”,從而有餘地得到更小的矩形。於是我們發現,矩形的某條邊的斜率必然與某兩點的連線相同。如果我們計算出了所有過兩點的直線的傾角,那麼α的取值只有可能是這些傾角或它減去90度后的角(直線按“\”方向傾斜時)這麼C(n,2)種。我們說,這個“傾角”已經被我們“離散化”了。雖然這個演演算法仍然有優化的餘地,但此時我們已經達到了本文開頭所說的目的。
對於某些坐標雖然已經是整數(已經是離散的了)但範圍極大的問題,我們也可以用離散化的思想縮小這個規模。最近搞模擬賽vijos似乎火了一把,我就拿兩道Vijos的題開刀。

VOJ1056
最後簡單講一下計算幾何以外的一個運用實例(實質仍然是坐標的離散)。VOJ1238中,標程開了一個與時間範圍一樣大的數組來儲存時間段的位置。這種方法在空間上來看十分危險。一旦時間取值範圍再大一點,盲目的空間開銷將導致Memory Limit Exceeded。我們完全可以採用離散化避免這種情況。我們對所有給出的時間坐標進行一次排序,然後同樣用時間段的開始點和結束點來計算每個時刻的遊戲數,只是一次性加的經驗值數將乘以排序后這兩個相鄰時間點的實際差。這樣,一個1..n的數組就足夠了。
離散化的應用相當廣泛,以後你會看到還有很多其它的用途。