網路信息挖掘
網路信息挖掘
網路信息挖掘是數據挖掘技術在網路信息處理中的應用。網路信息挖掘是從大量訓練樣本的基礎上得到數據對象間的內在特徵,並以此為依據進行有目的的信息提取。網路信息挖掘技術沿用了Robot、全文檢索等網路信息檢索中的優秀成果,同時以知識庫技術為基礎,綜合運用人工智慧、模式識別、神經網路領域的各種技術。應用網路信息挖掘技術的智能搜索引擎系統能夠獲取用戶個性化的信息需求,根據目標特徵信息在網路上或者信息庫中進行有目的的信息搜尋。
Web信息挖掘可以廣義地定義為從WWW中發現和分析有用的信息。網路信息挖掘(Web Mining)技術是在已知數據樣本的基礎上,通過歸納學習、機器學習、統計分析等方法得到數據對象間的內在特性,據此採用信息過濾技術在網路中提取用戶感興趣的信息,獲得更高層次的知識和規律。
網路信息挖掘大致分為4個步驟,資源發現,即檢索所需的網路文檔;信息選擇和預處理,即從檢索到的網路資源中自動挑選和預先處理得到專門的信息;概括化,即從單個的Web站點以及多個站點之間發現普遍的模式,分析,即對挖掘出的模式進行確認或解釋。根據挖掘的對象不同,網路信息挖掘可以分為網路內容挖掘、網路結構挖掘和網路用法挖掘。
網路信息挖掘系統採用向量空間模型,用特徵詞條及其權值代表目標信息。在進行信息匹配時,使用這些特徵項評價未知文本與目標樣本的相關程度。特徵詞條及其權值的選取稱為目標樣本的特徵提取,特徵提取演演算法的優劣將直接影響到系統的運行效果。詞條在不同內容的文檔中所呈現出的頻率分佈是不同的,因此可以根據詞條的頻率特性進行特徵提取和權重評價。
一個有效的特徵項集應該既能體現目標內容,也能將目標同其它文檔相區分,因此詞條權重正比於詞條的文檔內頻數,反比於訓練文本內出現該詞條的文檔頻數。
與普通的文本文件相比,HTML文檔中有明顯的標識符,結構信息更加明顯,對象的屬性更為豐富。系統在計算特徵詞條權值時,充分考慮HTML文檔的特點,對於標題和特徵信息較多的文本賦予較高權重。為了提高運行效率,系統對特徵向量進行降維處理,僅保留權值較高的詞條作為文檔的特徵項,從而形成維數較低的目標特徵向量。
我們要處理的信息主要是文本信息。為使準確提取文檔的主題信息,更好地建立特徵模型,就要建立主詞庫、同義詞庫、蘊含詞庫等詞典庫,並以此作為提取主題。一個好的專業詞典將會極大的提高主題提取的準確性。中文詞的切分問題是網路信息挖掘中的一項關鍵技術之一。《中國分類主題詞表》由於其學科體系的完整性和規範性,無疑是非常適合作詞庫。對於專業要求較高的數據挖掘以及在實際使用中出現的不符合要求的地方,可在該詞表的基礎上進行擴充和修改,這裡引入了圖書館學中后控的思想,即通過對詞表的規範來控制URL標引的準確性。
Robot是傳統搜索引擎的重要組成部分,它依照HTTP協議讀取Web頁面並根據HTML文檔中的超鏈在WWW上進行自動漫遊,Robot也被稱為Spider、Worm或Crawler。但Robot只能獲取Web上的靜態頁面,而有價值的信息往往存放在網路資料庫中,人們無法通過搜索引擎獲取這些數據,只能登錄專業信息網站,利用網站提供的查詢介面提交查詢請求,獲取並瀏覽系統生成的動態頁面。網路信息挖掘系統則通過網站提供的查詢介面對網路資料庫中的信息進行遍歷,並根據專業知識庫對遍歷的結果進行自動的分析整理,最後導入本地的信息庫。
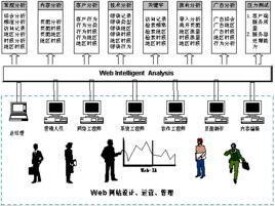
上圖給出了網路信息挖掘技術實現的總體流程圖,其具體步驟如下
第一步,確立目標樣本,即由用戶選擇目標文本提取用戶的特徵信息。
第二步:提取特徵信息,即根據目標樣本的詞頻分佈,從統計詞典中提取出挖掘目標的特徵向量並計算出相應的權值。
第三步網路信息獲取,即先利用搜索引擎站點選擇待採集站點,再利用Robot程序採集靜態Web頁面,最後獲取被訪問站點網路資料庫中的動態信息,生成WWW資源索引庫。
第四步信息特徵匹配,即提取索引庫中的源信息的特徵向量,並與目標樣本的特徵向量進行匹配,將符合閾值條件的信息返回給用戶。
網路信息挖掘技術在搜索引擎中的應用
信息檢索研究涉及到建立模型、文檔分類與歸類、用戶交互、數據可視化、數據過濾等等。功能網路信息挖掘作為信息檢索過程的一部分,最明顯的一個功能就是Web文檔的分類與歸類。
下面以Google為例,剖析網路信息挖掘技術在搜索引擎中的應用。
Google的搜索機制是:幾個分佈的Crawler(自動搜索軟體)同時工作——在網上“爬行”,URL伺服器則負責向這些Crawler提供URL的列表。Crawler所找到的網頁被送到存儲伺服器中。存儲伺服器於是就把這些網頁壓縮后存入一個知識庫中。每個網頁都有一個關聯ID
doc ID,當一個新的URL從一個網頁中解析出來時,就被分配一個doc ID。索引庫和排序器負責建立索引,索引庫從知識庫中讀取記錄,將文檔解壓並進行解析。每個文檔就轉換成一組詞的出現狀況,稱為hits。hits記錄了詞、詞在文檔中的位置、字體大小、大小寫等。索引庫把這些"hits"又分成一組"barrels",產生經過部分排序后的索引。索引庫同時分析網頁中所有的鏈接並將重要信息存在Anchors文檔中。這個文檔包含了足夠信息,可以用來判斷一個鏈接被鏈入或鏈出的結點信息。
URL分解器閱讀Anchors文檔,並把相對的URL轉換成絕對的URLs,並生成doc ID,它進一步為Anchor文本編製索引,並與Anchor所指向的doc ID建立關聯。同時,它還產生由doc ID對所形成的資料庫。這個鏈接資料庫用於計算所有文檔的頁面等級。
排序器會讀取barrels,並根據詞的ID號列表來生成倒排擋。一個名為DumpLexicon的程序則把上面的列表和由索引庫產生的一個新的詞表結合起來產生另一個新的詞表供搜索器使用。這個搜索器就是利用一個Web伺服器、由DumpLexicon所生成的詞表和上述倒排擋以及頁面等級來回答用戶的提問。
從Google的體系結構、搜索原理中可以看到,其關鍵而具有特色的一步是 利用URL分解器獲得Links信息,並且運用一定的演演算法得出了頁面等級的信息,這採用的技術正是網路結構挖掘技術。作為一個新興的搜索引擎,Google正是利用這種對WWW的連接進行分析和大規模的數據挖掘技術,使其搜索技術略勝一籌。
Google搜索的最大特色就體現 在它所採用的對網頁Links信息的挖掘技術上。而實際上,網路信息挖掘是網路信息檢索發展的一個關鍵。如通過對網頁內容挖掘,可以實現對網頁的聚類、分類,實現網路信息的分類瀏覽與檢索;同時,通過用戶所使用的提問式的歷史記錄的分析,可以有效地進行提問擴展,提高用戶的檢索效果(查全率,查准率);另外,運用網路內容挖掘技術改進關鍵詞加權演演算法,提高網路信息的標引準確度,從而改善檢索效果。
信息現代定義。[2006年,醫學信息(雜誌),鄧宇等].
信息是 物質、能量、信息及其屬性的標示。逆維納信息定義
信息是 確定性的增加。逆香農信息定義
信息是 事物現象及其屬性標識的集合。2002年
基本信息
- 外文名
- Web Mining