共找到2條詞條名為數據挖掘的結果 展開
- 計算機科學術語
- 期刊
數據挖掘
計算機科學術語
數據挖掘是一個計算機科學術語,讀音shù jù wā jué,意思一般是指從大量的數據中通過演演算法搜索隱藏於其中信息的過程。數據挖掘通常與計算機科學有關,並通過統計、在線分析處理、情報檢索、機器學習、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實現上述目標。
數據挖掘(英語:Data mining),又譯為資料探勘、數據採礦。它是資料庫知識發現(英語:Knowledge-Discovery in Databases,簡稱:KDD)中的一個步驟。數據挖掘一般是指從大量的數據中自動搜索隱藏於其中的有著特殊關係性(屬於Association rule learning)的信息的過程。數據挖掘通常與計算機科學有關,並通過統計、在線分析處理、情報檢索、機器學習、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實現上述目標。
需要是發明之母。近年來,數據挖掘引起了信息產業界的極大關注,其主要原因是存在大量數據,可以廣泛使用,並且迫切需要將這些數據轉換成有用的信息和知識。獲取的信息和知識可以廣泛用於各種應用,包括商務管理,生產控制,市場分析,工程設計和科學探索等。
數據挖掘利用了來自如下一些領域的思想:(1) 來自統計學的抽樣、估計和假設檢驗,(2)人工智慧、模式識別和機器學習的搜索演演算法、建模技術和學習理論。數據挖掘也迅速地接納了來自其他領域的思想,這些領域包括最優化、進化計算、資訊理論、信號處理、可視化和信息檢索。一些其他領域也起到重要的支撐作用。特別地,需要資料庫系統提供有效的存儲、索引和查詢處理支持。源於高性能(并行)計算的技術在處理海量數據集方面常常是重要的。分散式技術也能幫助處理海量數據,並且當數據不能集中到一起處理時更是至關重要。
20世紀90年代,隨著資料庫系統的廣泛應用和網路技術的高速發展,資料庫技術也進入一個全新的階段,即從過去僅管理一些簡單數據發展到管理由各種計算機所產生的圖形、圖像、音頻、視頻、電子檔案、Web頁面等多種類型的複雜數據,並且數據量也越來越大。資料庫在給我們提供豐富信息的同時,也體現出明顯的海量信息特徵。信息爆炸時代,海量信息給人們帶來許多負面影響,最主要的就是有效信息難以提煉,過多無用的信息必然會產生信息距離(信息狀態轉移距離)是對一個事物信息狀態轉移所遇到障礙的測度,簡稱DIST或DIT)和有用知識的丟失。這也就是約翰·內斯伯特( John Nalsbert)稱為的“信息豐富而知識貧乏”窘境。因此,人們迫切希望能對海量數據進行深入分析,發現並提取隱藏在其中的信息,以更好地利用這些數據。但僅以資料庫系統的錄入、查詢、統計等功能,無法發現數據中存在的關係和規則,無法根據現有的數據預測未來的發展趨勢,更缺乏挖掘數據背後隱藏知識的手段。正是在這樣的條件下,數據挖掘技術應運而生。
數據的類型可以是結構化的、半結構化的,甚至是異構型的。發現知識的方法可以是數學的、非數學的,也可以是歸納的。最終被發現了的知識可以用於信息管理、查詢優化、決策支持及數據自身的維護等。
數據挖掘的對象可以是任何類型的數據源。可以是關係資料庫,此類包含結構化數據的數據源;也可以是數據倉庫、文本、多媒體數據、空間數據、時序數據、Web數據,此類包含半結構化數據甚至異構性數據的數據源。
發現知識的方法可以是數字的、非數字的,也可以是歸納的。最終被發現的知識可以用於信息管理、查詢優化、決策支持及數據自身的維護等。
數據挖掘分為有指導的數據挖掘和無指導的數據挖掘。有指導的數據挖掘是利用可用的數據建立一個模型,這個模型是對一個特定屬性的描述。無指導的數據挖掘是在所有的屬性中尋找某種關係。具體而言,分類、估值和預測屬於有指導的數據挖掘;關聯規則和聚類屬於無指導的數據挖掘。
1.分類。它首先從數據中選出已經分好類的訓練集,在該訓練集上運用數據挖掘技術,建立一個分類模型,再將該模型用於對沒有分類的數據進行分類。
2.估值。估值與分類類似,但估值最終的輸出結果是連續型的數值,估值的量並非預先確定。估值可以作為分類的準備工作。
3.預測。它是通過分類或估值來進行,通過分類或估值的訓練得出一個模型,如果對於檢驗樣本組而言該模型具有較高的準確率,可將該模型用於對新樣本的未知變數進行預測。
4.相關性分組或關聯規則。其目的是發現哪些事情總是一起發生。
5.聚類。它是自動尋找並建立分組規則的方法,它通過判斷樣本之間的相似性,把相似樣本劃分在一個簇中。
1、數據挖掘幫助Credilogros Cía Financiera S.A.改善客戶信用評分
Credilogros Cía Financiera S.A. 是阿根廷第五大信貸公司,資產估計價值為9570萬美元,對於Credilogros而言,重要的是識別與潛在預先付款客戶相關的潛在風險,以便將承擔的風險最小化。
該公司的第一個目標是創建一個與公司核心繫統和兩家信用報告公司系統交互的決策引擎來處理信貸申請。同時,Credilogros還在尋找針對它所服務的低收入客戶群體的自定義風險評分工具。除這些之外,其他需求還包括解決方案能在其35個分支辦公地點和200多個相關的銷售點中的任何一個實時操作,包括零售家電連鎖店和手機銷售公司。
最終Credilogros 選擇了SPSS Inc.的數據挖掘軟體PASWModeler,因為它能夠靈活並輕鬆地整合到 Credilogros 的核心信息系統中。通過實現PASW Modeler,Credilogros將用於處理信用數據和提供最終信用評分的時間縮短到了8秒以內。這使該組織能夠迅速批准或拒絕信貸請求。該決策引擎還使 Credilogros 能夠最小化每個客戶必須提供的身份證明文檔,在一些特殊情況下,只需提供一份身份證明即可批准信貸。此外,該系統還提供監控功能。Credilogros目前平均每月使用PASW Modeler處理35000份申請。僅在實現 3 個月後就幫助Credilogros 將貸款支付失職減少了 20%。
2、數據挖掘幫助DHL實時跟蹤貨箱溫度
DHL是國際快遞和物流行業的全球市場領先者,它提供快遞、水陸空三路運輸、合同物流解決方案,以及國際郵件服務。DHL的國際網路將超過220個國家及地區聯繫起來,員工總數超過28.5萬人。在美國 FDA 要求確保運送過程中藥品裝運的溫度達標這一壓力之下,DHL的醫藥客戶強烈要求提供更可靠且更實惠的選擇。這就要求DHL在遞送的各個階段都要實時跟蹤集裝箱的溫度。
雖然由記錄器方法生成的信息準確無誤,但是無法實時傳遞數據,客戶和DHL都無法在發生溫度偏差時採取任何預防和糾正措施。因此,DHL的母公司德國郵政世界網(DPWN)通過技術與創新管理(TIM)集團明確擬定了一個計劃,準備使用RFID技術在不同時間點全程跟蹤裝運的溫度。通過IBM全球企業諮詢服務部繪製決定服務的關鍵功能參數的流程框架。DHL獲得了兩方面的收益:對於最終客戶來說,能夠使醫藥客戶對運送過程中出現的裝運問題提前做出響應,並以引人注目的低成本全面切實地增強了運送可靠性。對於DHL來說,提高了客戶滿意度和忠實度;為保持競爭差異奠定堅實的基礎;並成為重要的新的收入增長來源。
3、電信行業應用
價格競爭空前激烈,語音業務增長趨緩,快速增長的中國移動通信市場正面臨著前所未有的生存壓力。中國電信業改革的加速推進形成了新的競爭態勢,移動運營市場的競爭廣度和強度將進一步加大,這特別表現在集團客戶領域。移動信息化和集團客戶已然成為未來各運營商應對競爭、獲取持續增長的新引擎。
隨著國內三足鼎立全業務競爭態勢和3G牌照發放,各運營商為集團客戶提供融合的信息化解決方案將是大勢所趨,而移動信息化將成為全面進入信息化服務領域的先導力量。傳統移動運營商因此面臨著從傳統個人業務轉向同時拓展集團客戶信息化業務領域的挑戰。如何應對來自內外部的挑戰,迅速以移動信息化業務作為融合業務的競爭利器之一拓展集團客戶市場,在新興市場中立於不敗之地,是傳統移動運營商需要解決的緊迫問題。
目前,數據挖掘的演演算法主要包括神經網路法、決策樹法、遺傳演演算法、粗糙集法、模糊集法、關聯規則法等。
神經網路法
神經網路法是模擬生物神經系統的結構和功能,是一種通過訓練來學習的非線性預測模型,它將每一個連接看作一個處理單元,試圖模擬人腦神經元的功能,可完成分類、聚類、特徵挖掘等多種數據挖掘任務。神經網路的學習方法主要表現在權值的修改上。其優點是具有抗干擾、非線性學習、聯想記憶功能,對複雜情況能得到精確的預測結果;缺點首先是不適合處理高維變數,不能觀察中間的學習過程,具有“黑箱”性,輸出結果也難以解釋;其次是需較長的學習時間。神經網路法主要應用於數據挖掘的聚類技術中。
決策樹法
決策樹是根據對目標變數產生效用的不同而建構分類的規則,通過一系列的規則對數據進行分類的過程,其表現形式是類似於樹形結構的流程圖。最典型的演演算法是J.R.Quinlan於1986年提出的ID3演演算法,之後在ID3演演算法的基礎上又提出了極其流行的C4.5演演算法。採用決策樹法的優點是決策制定的過程是可見的,不需要長時間構造過程、描述簡單,易於理解,分類速度快;缺點是很難基於多個變數組合發現規則。決策樹法擅長處理非數值型數據,而且特別適合大規模的數據處理。決策樹提供了一種展示類似在什麼條件下會得到什麼值這類規則的方法。比如,在貸款申請中,要對申請的風險大小做出判斷。
遺傳演演算法
遺傳演演算法模擬了自然選擇和遺傳中發生的繁殖、交配和基因突變現象,是一種採用遺傳結合、遺傳交叉變異及自然選擇等操作來生成實現規則的、基於進化理論的機器學習方法。它的基本觀點是“適者生存”原理,具有隱含并行性、易於和其他模型結合等性質。主要的優點是可以處理許多數據類型,同時可以并行處理各種數據;缺點是需要的參數太多,編碼困難,一般計算量比較大。遺傳演演算法常用於優化神經元網路,能夠解決其他技術難以解決的問題。
粗糙集法
粗糙集法也稱粗糙集理論,是由波蘭數學家Z Pawlak在20世紀80年代初提出的,是一種新的處理含糊、不精確、不完備問題的數學工具,可以處理數據約簡、數據相關性發現、數據意義的評估等問題。其優點是演演算法簡單,在其處理過程中可以不需要關於數據的先驗知識,可以自動找出問題的內在規律;缺點是難以直接處理連續的屬性,須先進行屬性的離散化。因此,連續屬性的離散化問題是制約粗糙集理論實用化的難點。粗糙集理論主要應用於近似推理、數字邏輯分析和化簡、建立預測模型等問題。
模糊集法
模糊集法是利用模糊集合理論對問題進行模糊評判、模糊決策、模糊模式識別和模糊聚類分析。模糊集合理論是用隸屬度來描述模糊事物的屬性。系統的複雜性越高,模糊性就越強。
關聯規則法
關聯規則反映了事物之間的相互依賴性或關聯性。其最著名的演演算法是R.Agrawal等人提出的Apriori演演算法。其演演算法的思想是:首先找出頻繁性至少和預定意義的最小支持度一樣的所有頻集,然後由頻集產生強關聯規則。最小支持度和最小可信度是為了發現有意義的關聯規則給定的2個閾值。在這個意義上,數據挖掘的目的就是從源資料庫中挖掘出滿足最小支持度和最小可信度的關聯規則。
與數據挖掘有關的,還牽扯到隱私問題,例如:一個僱主可以通過訪問醫療記錄來篩選出那些有糖尿病或者嚴重心臟病的人,從而意圖削減保險支出。然而,這種做法會導致倫理和法律問題。對於政府和商業數據的挖掘,可能會涉及到的,是國家安全或者商業機密之類的問題。這對於保密也是個不小的挑戰。數據挖掘有很多合法的用途,例如可以在患者群的資料庫中查出某藥物和其副作用的關係。這種關係可能在1000人中也不會出現一例,但藥物學相關的項目就可以運用此方法減少對藥物有不良反應的病人數量,還有可能挽救生命;但這當中還是存在著資料庫可能被濫用的問題。 數據挖掘實現了用其他方法不可能實現的方法來發現信息,但它必須受到規範,應當在適當的說明下使用。 如果數據是收集自特定的個人,那麼就會出現一些涉及保密、法律和倫理的問題。
第一階段:電子郵件階段
這個階段可以認為是從70年代開始,平均的通訊量以每年幾倍的速度增長。
第二階段:信息發布階段
從1995年起,以Web技術為代表的信息發布系統,爆炸式地成長起來,成為目前Internet的主要應用。中小企業如何把握好從“粗放型”到“精準型”營銷時代的電子商務。
第三階段: EC(Electronic Commerce),即電子商務階段
EC在美國也才剛剛開始,之所以把EC列為一個劃時代的東西,是因為Internet的最終主要商業用途,就是電子商務。同時反過來也可以說,若干年後的商業信息,主要是通過Internet傳遞。Internet即將成為我們這個商業信息社會的神經系統。1997年底在加拿大溫哥華舉行的第五次亞太經合組織非正式首腦會議(APEC)上美國總統柯林頓提出敦促各國共同促進電子商務發展的議案,其引起了全球首腦的關注,IBM、HP和Sun等國際著名的信息技術廠商已經宣布1998年為電子商務年。
第四階段:全程電子商務階段
隨著SaaS(Software as a service)軟體服務模式的出現,軟體紛紛登陸網際網路,延長了電子商務鏈條,形成了當下最新的“全程電子商務”概念模式。也因此形成了一門獨立的學科——數據挖掘與客戶關係管理碩士。
數據挖掘
· 估計(Estimation)
· 預測(Prediction)
· 相關性分組或關聯規則(Affinity grouping or association rules)
· 聚類(Clustering)
· 複雜數據類型挖掘(Text, Web ,圖形圖像,視頻,音頻等)
·分類(Classification)
首先從數據中選出已經分好類的訓練集,在該訓練集上運用數據挖掘分類的技術,建立分類模型,對於沒有分類的數據進行分類。
例子:
a. 信用卡申請者,分類為低、中、高風險
b. 故障診斷:中國寶鋼集團與上海天律信息技術有限公司合作,採用數據挖掘技術對鋼材生產的全流程進行質量監控和分析,構建故障地圖,實時分析產品出現瑕疵的原因,有效提高了產品的優良率。
注意:類的個數是確定的,預先定義好的
· 估計(Estimation)
估計與分類類似,不同之處在於,分類描述的是離散型變數的輸出,而估值處理連續值的輸出;分類的類別是確定數目的,估值的量是不確定的。
例子:
a. 根據購買模式,估計一個家庭的孩子個數
b. 根據購買模式,估計一個家庭的收入
c. 估計real estate的價值
一般來說,估值可以作為分類的前一步工作。給定一些輸入數據,通過估值,得到未知的連續變數的值,然後,根據預先設定的閾值,進行分類。例如:銀行對家庭貸款業務,運用估值,給各個客戶記分(Score 0~1)。然後,根據閾值,將貸款級別分類。
· 預測(Prediction)
通常,預測是通過分類或估值起作用的,也就是說,通過分類或估值得出模型,該模型用於對未知變數的預言。從這種意義上說,預言其實沒有必要分為一個單獨的類。預言其目的是對未來未知變數的預測,這種預測是需要時間來驗證的,即必須經過一定時間后,才知道預言準確性是多少。
· 相關性分組或關聯規則(Affinity grouping or association rules)
決定哪些事情將一起發生。
例子:
a. 超市中客戶在購買A的同時,經常會購買B,即A => B(關聯規則)
b. 客戶在購買A后,隔一段時間,會購買B (序列分析)
· 聚類(Clustering)
聚類是對記錄分組,把相似的記錄在一個聚集里。聚類和分類的區別是聚集不依賴於預先定義好的類,不需要訓練集。
例子:
a. 一些特定癥狀的聚集可能預示了一個特定的疾病
b. 租VCD類型不相似的客戶聚集,可能暗示成員屬於不同的亞文化群
聚集通常作為數據挖掘的第一步。例如,"哪一種類的促銷對客戶響應最好?",對於這一 類問題,首先對整個客戶做聚集,將客戶分組在各自的聚集里,然後對每個不同的聚集,回答問題,可能效果更好。
· 描述和可視化(Description and Visualization)
是對數據挖掘結果的表示方式。一般只是指數據可視化工具,包含報表工具和商業智能分析產品(BI)的統稱。譬如通過Yonghong Z-Suite等工具進行數據的展現,分析,鑽取,將數據挖掘的分析結果更形象,深刻的展現出來。
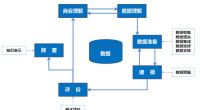
第一,目標律:業務目標是所有數據解決方案的源頭。
第二,知識律:業務知識是數據挖掘過程每一步的核心。
第三,準備律:數據預處理比數據挖掘其他任何一個過程都重要。
第四,試驗律(NFL律:No Free Lunch):對於數據挖掘者來說,天下沒有免費的午餐,一個正確的模型只有通過試驗(experiment)才能被發現。
第五,模式律(大衛律):數據中總含有模式。
第六,洞察律:數據挖掘增大對業務的認知。
第七,預測律:預測提高了信息泛化能力。
第八,價值律:數據挖掘的結果的價值不取決於模型的穩定性或預測的準確性。
第九,變化律:所有的模式因業務變化而變化。
在描述關聯規則的一些細節之前,我們先來看一個有趣的故事: "尿布與啤酒"的故事。
在一家超市裡,有一個有趣的現象:尿布和啤酒赫然擺在一起出售。但是這個奇怪的舉措卻使尿布和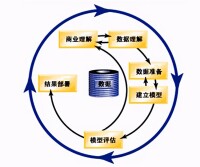 啤酒的銷量雙雙增加了。這不是一個笑話,而是發生在美國沃爾瑪連鎖店超市的真實案例,並一直為商家所津津樂道。沃爾瑪擁有世界上最大的數據倉庫系統,為了能夠準確了解顧客在其門店的購買習慣,沃爾瑪對其顧客的購物行為進行購物籃分析,想知道顧客經常一起購買的商品有哪些。沃爾瑪數據倉庫里集中了其各門店的詳細原始交易數據。在這些原始交易數據的基礎上,沃爾瑪利用數據挖掘方法對這些數據進行分析和挖掘。一個意外的發現是:"跟尿布一起購買最多的商品竟是啤酒!經過大量實際調查和分析,揭示了一個隱藏在"尿布與啤酒"背後的美國人的一種行為模式:在美國,一些年輕的父親下班后經常要到超市去買嬰兒尿布,而他們中有30%~40%的人同時也為自己買一些啤酒。產生這一現象的原因是:美國的太太們常叮囑她們的丈夫下班後為小孩買尿布,而丈夫們在買尿布后又隨手帶回了他們喜歡的啤酒。
啤酒的銷量雙雙增加了。這不是一個笑話,而是發生在美國沃爾瑪連鎖店超市的真實案例,並一直為商家所津津樂道。沃爾瑪擁有世界上最大的數據倉庫系統,為了能夠準確了解顧客在其門店的購買習慣,沃爾瑪對其顧客的購物行為進行購物籃分析,想知道顧客經常一起購買的商品有哪些。沃爾瑪數據倉庫里集中了其各門店的詳細原始交易數據。在這些原始交易數據的基礎上,沃爾瑪利用數據挖掘方法對這些數據進行分析和挖掘。一個意外的發現是:"跟尿布一起購買最多的商品竟是啤酒!經過大量實際調查和分析,揭示了一個隱藏在"尿布與啤酒"背後的美國人的一種行為模式:在美國,一些年輕的父親下班后經常要到超市去買嬰兒尿布,而他們中有30%~40%的人同時也為自己買一些啤酒。產生這一現象的原因是:美國的太太們常叮囑她們的丈夫下班後為小孩買尿布,而丈夫們在買尿布后又隨手帶回了他們喜歡的啤酒。
數據挖掘
按常規思維,尿布與啤酒風馬牛不相及,若不是藉助數據挖掘技術對大量交易數據進行挖掘分析,沃爾瑪是不可能發現數據內在這一有價值的規律的。
數據關聯是資料庫中存在的一類重要的可被發現的知識。若兩個或多個變數的取值之間存在某種規律性,就稱為關聯。關聯可分為簡單關聯、時序關聯、因果關聯。關聯分析的目的是找出資料庫中隱藏的關聯網。有時並不知道資料庫中數據的關聯函數,即使知道也是不確定的,因此關聯分析生成的規則帶有可信度。關聯規則挖掘發現大量數據中項集之間有趣的關聯或相關聯繫。Agrawal等於1993年首先提出了挖掘顧客交易資料庫中項集間的關聯規則問題,以後諸多的研究人員對關聯規則的挖掘問題進行了大量的研究。他們的工作包括對原有的演演算法進行優化,如引入隨機採樣、并行的思想等,以提高演演算法挖掘規則的效率;對關聯規則的應用進行推廣。關聯規則挖掘在數據挖掘中是一個重要的課題,最近幾年已被業界所廣泛研究。
關聯規則挖掘過程主要包含兩個階段:第一階段必須先從資料集合中找出所有的高頻項目組(FrequentItemsets),第二階段再由這些高頻項目組中產生關聯規則(Association Rules)。
關聯規則挖掘的第一階段必須從原始資料集合中,找出所有高頻項目組(Large Itemsets)。高頻的意思是指某一項目組出現的頻率相對於所有記錄而言,必須達到某一水平。一項目組出現的頻率稱為支持度(Support),以一個包含A與B兩個項目的2-itemset為例,我們可以經由公式(1)求得包含{A,B}項目組的支持度,若支持度大於等於所設定的最小支持度(Minimum Support)門檻值時,則{A,B}稱為高頻項目組。一個滿足最小支持度的k-itemset,則稱為高頻k-項目組(Frequent k-itemset),一般表示為Large k或Frequent k。演演算法並從Large k的項目組中再產生Large k+1,直到無法再找到更長的高頻項目組為止。
關聯規則挖掘的第二階段是要產生關聯規則(Association Rules)。從高頻項目組產生關聯規則,是利用前一步驟的高頻k-項目組來產生規則,在最小信賴度(Minimum Confidence)的條件門檻下,若一規則所求得的信賴度滿足最小信賴度,稱此規則為關聯規則。例如:經由高頻k-項目組{A,B}所產生的規則AB,其信賴度可經由公式(2)求得,若信賴度大於等於最小信賴度,則稱AB為關聯規則。
就沃爾瑪案例而言,使用關聯規則挖掘技術,對交易資料庫中的紀錄進行資料挖掘,首先必須要設定最小支持度與最小信賴度兩個門檻值,在此假設最小支持度min_support=5% 且最小信賴度min_confidence=70%。因此符合此該超市需求的關聯規則將必須同時滿足以上兩個條件。若經過挖掘過程所找到的關聯規則「尿布,啤酒」,滿足下列條件,將可接受「尿布,啤酒」的關聯規則。用公式可以描述Support(尿布,啤酒)>=5%且Confidence(尿布,啤酒)>=70%。其中,Support(尿布,啤酒)>=5%於此應用範例中的意義為:在所有的交易紀錄資料中,至少有5%的交易呈現尿布與啤酒這兩項商品被同時購買的交易行為。Confidence(尿布,啤酒)>=70%於此應用範例中的意義為:在所有包含尿布的交易紀錄資料中,至少有70%的交易會同時購買啤酒。因此,今後若有某消費者出現購買尿布的行為,超市將可推薦該消費者同時購買啤酒。這個商品推薦的行為則是根據「尿布,啤酒」關聯規則,因為就該超市過去的交易紀錄而言,支持了“大部份購買尿布的交易,會同時購買啤酒”的消費行為。
從上面的介紹還可以看出,關聯規則挖掘通常比較適用與記錄中的指標取離散值的情況。如果原始資料庫中的指標值是取連續的數據,則在關聯規則挖掘之前應該進行適當的數據離散化(實際上就是將某個區間的值對應於某個值),數據的離散化是數據挖掘前的重要環節,離散化的過程是否合理將直接影響關聯規則的挖掘結果。
按照不同情況,關聯規則可以進行分類如下:
1.基於規則中處理的變數的類別,關聯規則可以分為布爾型和數值型。
布爾型關聯規則處理的值都是離散的、種類化的,它顯示了這些變數之間的關係;而數值型關聯規則可以和多維關聯或多層關聯規則結合起來,對數值型欄位進行處理,將其進行動態的分割,或者直接對原始的數據進行處理,當然數值型關聯規則中也可以包含種類變數。例如:性別=“女”=>職業=“秘書” ,是布爾型關聯規則;性別=“女”=>avg(收入)=2300,涉及的收入是數值類型,所以是一個數值型關聯規則。
2.基於規則中數據的抽象層次,可以分為單層關聯規則和多層關聯規則。
在單層的關聯規則中,所有的變數都沒有考慮到現實的數據是具有多個不同的層次的;而在多層的關聯規則中,對數據的多層性已經進行了充分的考慮。例如:IBM台式機=>Sony印表機,是一個細節數據上的單層關聯規則;台式機=>Sony印表機,是一個較高層次和細節層次之間的多層關聯規則。
3.基於規則中涉及到的數據的維數,關聯規則可以分為單維的和多維的。
在單維的關聯規則中,我們只涉及到數據的一個維,如用戶購買的物品;而在多維的關聯規則中,要處理的數據將會涉及多個維。換成另一句話,單維關聯規則是處理單個屬性中的一些關係;多維關聯規則是處理各個屬性之間的某些關係。例如:啤酒=>尿布,這條規則只涉及到用戶的購買的物品;性別=“女”=>職業=“秘書”,這條規則就涉及到兩個欄位的信息,是兩個維上的一條關聯規則。
1.Apriori演演算法:使用候選項集找頻繁項集
Apriori演演算法是一種最有影響的挖掘布爾關聯規則頻繁項集的演演算法。其核心是基於兩階段頻集思想的遞推演演算法。該關聯規則在分類上屬於單維、單層、布爾關聯規則。在這裡,所有支持度大於最小支持度的項集稱為頻繁項集,簡稱頻集。
該演演算法的基本思想是:首先找出所有的頻集,這些項集出現的頻繁性至少和預定義的最小支持度一樣。然後由頻集產生強關聯規則,這些規則必須滿足最小支持度和最小可信度。然後使用第1步找到的頻集產生期望的規則,產生只包含集合的項的所有規則,其中每一條規則的右部只有一項,這裡採用的是中規則的定義。一旦這些規則被生成,那麼只有那些大於用戶給定的最小可信度的規則才被留下來。為了生成所有頻集,使用了遞推的方法。
可能產生大量的候選集,以及可能需要重複掃描資料庫,是Apriori演演算法的兩大缺點。
2.基於劃分的演演算法
Savasere等設計了一個基於劃分的演演算法。這個演演算法先把資料庫從邏輯上分成幾個互不相交的塊,每次單獨考慮一個分塊並對它生成所有的頻集,然後把產生的頻集合併,用來生成所有可能的頻集,最後計算這些項集的支持度。這裡分塊的大小選擇要使得每個分塊可以被放入主存,每個階段只需被掃描一次。而演演算法的正確性是由每一個可能的頻集至少在某一個分塊中是頻集保證的。該演演算法是可以高度并行的,可以把每一分塊分別分配給某一個處理器生成頻集。產生頻集的每一個循環結束后,處理器之間進行通信來產生全局的候選k-項集。通常這裡的通信過程是演演算法執行時間的主要瓶頸;而另一方面,每個獨立的處理器生成頻集的時間也是一個瓶頸。
3.FP-樹頻集演演算法
針對Apriori演演算法的固有缺陷,J. Han等提出了不產生候選挖掘頻繁項集的方法:FP-樹頻集演演算法。採用分而治之的策略,在經過第一遍掃描之後,把資料庫中的頻集壓縮進一棵頻繁模式樹(FP-tree),同時依然保留其中的關聯信息,隨後再將FP-tree分化成一些條件庫,每個庫和一個長度為1的頻集相關,然後再對這些條件庫分別進行挖掘。當原始數據量很大的時候,也可以結合劃分的方法,使得一個FP-tree可以放入主存中。實驗表明,FP-growth對不同長度的規則都有很好的適應性,同時在效率上較之Apriori演演算法有巨大的提高。
就目前而言,關聯規則挖掘技術已經被廣泛應用在西方金融行業企業中,它可以成功預測銀行客戶需求。一旦獲得了這些信息,銀行就可以改善自身營銷。現在銀行天天都在開發新的溝通客戶的方法。各銀行在自己的ATM機上就捆綁了顧客可能感興趣的本行產品信息,供使用本行ATM機的用戶了解。如果資料庫中顯示,某個高信用限額的客戶更換了地址,這個客戶很有可能新近購買了一棟更大的住宅,因此會有可能需要更高信用限額,更高端的新信用卡,或者需要一個住房改善貸款,這些產品都可以通過信用卡賬單郵寄給客戶。當客戶打電話諮詢的時候,資料庫可以有力地幫助電話銷售代表。銷售代表的電腦屏幕上可以顯示出客戶的特點,同時也可以顯示出顧客會對什麼產品感興趣。
同時,一些知名的電子商務站點也從強大的關聯規則挖掘中的受益。這些電子購物網站使用關聯規則中規則進行挖掘,然後設置用戶有意要一起購買的捆綁包。也有一些購物網站使用它們設置相應的交叉銷售,也就是購買某種商品的顧客會看到相關的另外一種商品的廣告。
但是目前在我國,“數據海量,信息缺乏”是商業銀行在數據大集中之後普遍所面對的尷尬。目前金融業實施的大多數資料庫只能實現數據的錄入、查詢、統計等較低層次的功能,卻無法發現數據中存在的各種有用的信息,譬如對這些數據進行分析,發現其數據模式及特徵,然後可能發現某個客戶、消費群體或組織的金融和商業興趣,並可觀察金融市場的變化趨勢。可以說,關聯規則挖掘的技術在我國的研究與應用並不是很廣泛深入。
近年來,電信業從單純的語音服務演變為提供多種服務的綜合信息服務商。隨著網路技術和電信業務的發展,電信市場競爭也日趨激烈,電信業務的發展提出了對數據挖掘技術的迫切需求,以便幫助理解商業行為,識別電信模式,捕捉盜用行為,更好地利用資源,提高服務質量並增強自身的競爭力。下面運用一些簡單的實例說明如何在電信行業使用數據挖掘技術。可以使用上面提到的K 均值、EM 等聚類演演算法,針對運營商積累的大量用戶消費數據建立客戶分群模型,通過客戶分群模型對客戶進行細分,找出有相同特徵的目標客戶群,然後有針對性地進行營銷。而且,聚類演演算法也可以實現離群點檢測,即在對用戶消費數據進行聚類的過程中,發現一些用戶的異常消費行為,據此判斷這些用戶是否存在欺詐行為,決定是否採取防範措施。可以使用上面提到的C4.5、SVM 和貝葉斯等分類演演算法,針對用戶的行為數據,對用戶進行信用等級評定,對於信用等級好的客戶可以給予某些優惠服務等,對於信用等級差的用戶不能享受促銷等優惠。可以使用預測相關的演演算法,對電信客戶的網路使用和客戶投訴數據進行建模,建立預測模型,預測大客戶離網風險,採取激勵和挽留措施防止客戶流失。可以使用相關分析找出選擇了多個套餐的客戶在套餐組合中的潛在規律,哪些套餐容易被客戶同時選取,例如,選擇了流量套餐的客戶中大部分選擇了彩鈴業務,然後基於相關性的法則,對選擇流量但是沒有選擇彩鈴的客戶進行交叉營銷,向他們推銷彩鈴業務。
由於許多應用問題往往比超市購買問題更複雜,大量研究從不同的角度對關聯規則做了擴展,將更多的因素集成到關聯規則挖掘方法之中,以此豐富關聯規則的應用領域,拓寬支持管理決策的範圍。如考慮屬性之間的類別層次關係,時態關係,多表挖掘等。近年來圍繞關聯規則的研究主要集中於兩個方面,即擴展經典關聯規則能夠解決問題的範圍,改善經典關聯規則挖掘演演算法效率和規則興趣性。
類似區別
一個經常問的問題是,數據挖掘和OLAP到底有何不同。下面將會解釋,他們是完全不同的工具,基於的技術也大相徑庭。
OLAP是決策支持領域的一部分。傳統的查詢和報表工具是告訴你資料庫中都有什麼(what happened),OLAP則更進一步告訴你下一步會怎麼樣(What next)、和如果我採取這樣的措施又會怎麼樣(What if)。用戶首先建立一個假設,然後用OLAP檢索資料庫來驗證這個假設是否正確。比如,一個分析師想找到什麼原因導致了貸款拖欠,他可能先做一個初始的假定,認為低收入的人信用度也低,然後用OLAP來驗證他這個假設。如果這個假設沒有被證實,他可能去察看那些高負債的賬戶,如果還不行,他也許要把收入和負債一起考慮,一直進行下去,直到找到他想要的結果或放棄。
也就是說,OLAP分析師是建立一系列的假設,然後通過OLAP來證實或推翻這些假設來最終得到自己的結論。OLAP分析過程在本質上是一個演繹推理的過程。但是如果分析的變數達到幾十或上百個,那麼再用OLAP手動分析驗證這些假設將是一件非常困難和痛苦的事情。
數據挖掘與OLAP不同的地方是,數據挖掘不是用於驗證某個假定的模式(模型)的正確性,而是在資料庫中自己尋找模型。他在本質上是一個歸納的過程。比如,一個用數據挖掘工具的分析師想找到引起貸款拖欠的風險因素。數據挖掘工具可能幫他找到高負債和低收入是引起這個問題的因素,甚至還可能發現一些分析師從來沒有想過或試過的其他因素,比如年齡。
數據挖掘和OLAP具有一定的互補性。在利用數據挖掘出來的結論採取行動之前,你也許要驗證一下如果採取這樣的行動會給公司帶來什麼樣的影響,那麼OLAP工具能回答你的這些問題。
而且在知識發現的早期階段,OLAP工具還有其他一些用途。可以幫你探索數據,找到哪些是對一個問題比較重要的變數,發現異常數據和互相影響的變數。這都能幫你更好的理解你的數據,加快知識發現的過程。
相關技術
數據挖掘利用了人工智慧(AI)和統計分析的進步所帶來的好處。這兩門學科都致力於模式發現和預測。
數據挖掘不是為了替代傳統的統計分析技術。相反,他是統計分析方法學的延伸和擴展。大多數的統計分析技術都基於完善的數學理論和高超的技巧,預測的準確度還是令人滿意的,但對使用者的要求很高。而隨著計算機計算能力的不斷增強,我們有可能利用計算機強大的計算能力只通過相對簡單和固定的方法完成同樣的功能。
一些新興的技術同樣在知識發現領域取得了很好的效果,如神經元網路和決策樹,在足夠多的數據和計算能力下,他們幾乎不用人的關照自動就能完成許多有價值的功能。
數據挖掘就是利用了統計和人工智慧技術的應用程序,他把這些高深複雜的技術封裝起來,使人們不用自己掌握這些技術也能完成同樣的功能,並且更專註於自己所要解決的問題。
相關影響
使數據挖掘這件事情成為可能的關鍵一點是計算機性能價格比的巨大進步。在過去的幾年裡磁碟存儲器的價格幾乎降低了99%,這在很大程度上改變了企業界對數據收集和存儲的態度。如果每兆的價格是¥10,那存放1TB的價格是¥10,000,000,但當每兆的價格降為1毛錢時,存儲同樣的數據只有¥100,000!
計算機計算能力價格的降低同樣非常顯著。每一代晶元的誕生都會把CPU的計算能力提高一大步。內存RAM也同樣降價迅速,幾年之內每兆內存的價格由幾百塊錢降到現在只要幾塊錢。通常PC都有64M內存,工作站達到了256M,擁有上G內存的伺服器已經不是什麼新鮮事了。
在單個CPU計算能力大幅提升的同時,基於多個CPU的并行系統也取得了很大的進步。目前幾乎所有的伺服器都支持多個CPU,這些SMP伺服器簇甚至能讓成百上千個CPU同時工作。
基於并行系統的資料庫管理系統也給數據挖掘技術的應用帶來了便利。如果你有一個龐大而複雜的數據挖掘問題要求通過訪問資料庫取得數據,那麼效率最高的辦法就是利用一個本地的并行資料庫。
所有這些都為數據挖掘的實施掃清了道路,隨著時間的延續,我們相信這條道路會越來越平坦。
與數據挖掘有關的,還牽扯到隱私問題,例如:一個僱主可以通過訪問醫療記錄來篩選出那些有糖尿病或者嚴重心臟病的人,從而意圖削減保險支出。然而,這種做法會導致倫理和法律問題。對於政府和商業數據的挖掘,可能會涉及到的,是國家安全或者商業機密之類的問題。這對於保密也是個不小的挑戰。數據挖掘有很多合法的用途,例如可以在患者群的資料庫中查出某藥物和其副作用的關係。這種關係可能在1000人中也不會出現一例,但藥物學相關的項目就可以運用此方法減少對藥物有不良反應的病人數量,還有可能挽救生命;但這當中還是存在著資料庫可能被濫用的問題。數據挖掘實現了用其他方法不可能實現的方法來發現信息,但它必須受到規範,應當在適當的說明下使用。如果數據是收集自特定的個人,那麼就會出現一些涉及保密、法律和倫理的問題。
基本信息
- 中文名
- 數據挖掘
- 外文名
- Data mining
- 別名
- 資料探勘、數據採礦
- 術語類別
- 計算機科學術語
- 應用領域
- 統計、情報檢索、模式識別等
- 釋義
- 從大量的數據中通過演算法搜索隱藏於其中信息的過程
- 拼音
- shù jù wā jué