共找到9條詞條名為SPARK的結果 展開
SPARK
計算引擎
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同於MapReduce的是——Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用於數據挖掘與機器學習等需要迭代的MapReduce的演演算法。
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分佈數據集,除了能夠提供互動式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕鬆地操作分散式數據集。
儘管創建 Spark 是為了支持分散式數據集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoop 文件系統中并行運行。通過名為 Mesos 的第三方集群框架可以支持此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的數據分析應用程序。
Apache Spark是專為大規模數據處理而設計的快速通用的計算引擎。現在形成一個高速發展應用廣泛的生態系統。
Spark 主要有三個特點:
首先,高級 API 剝離了對集群本身的關注,Spark 應用開發者可以專註於應用所要做的計算本身。
其次,Spark 很快,支持互動式計算和複雜演演算法。
最後,Spark 是一個通用引擎,可用它來完成各種各樣的運算,包括 SQL 查詢、文本處理、機器學習等,而在 Spark 出現之前,我們一般需要學習各種各樣的引擎來分別處理這些需求。
• 更快的速度
內存計算下,Spark 比 Hadoop 快100倍。
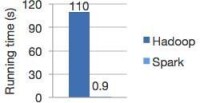
計算時間比較
Spark 提供了80多個高級運算符。
• 通用性
Spark 提供了大量的庫,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。開發者可以在同一個應用程序中無縫組合使用這些庫。
• 支持多種資源管理器
Spark 支持 Hadoop YARN,Apache Mesos,及其自帶的獨立集群管理器
• Spark生態系統
• Shark:Shark基本上就是在Spark的框架基礎上提供和Hive一樣的HiveQL命令介面,為了最大程度的保持和Hive的兼容性,Spark使用了Hive的API來實現query Parsing和 Logic Plan generation,最後的PhysicalPlan execution階段用Spark代替HadoopMapReduce。通過配置Shark參數,Shark可以自動在內存中緩存特定的RDD,實現數據重用,進而加快特定數據集的檢索。同時,Shark通過UDF用戶自定義函數實現特定的數據分析學習演演算法,使得SQL數據查詢和運算分析能結合在一起,最大化RDD的重複使用。
• SparkR:SparkR是一個為R提供了輕量級的Spark前端的R包。 SparkR提供了一個分散式的data frame數據結構,解決了 R中的data frame只能在單機中使用的瓶頸,它和R中的data frame 一樣支持許多操作,比如select,filter,aggregate等等。(類似dplyr包中的功能)這很好的解決了R的大數據級瓶頸問題。 SparkR也支持分散式的機器學習演演算法,比如使用MLib機器學習庫。 SparkR為Spark引入了R語言社區的活力,吸引了大量的數據科學家開始在Spark平台上直接開始數據分析之旅。
Spark Streaming:構建在Spark上處理Stream數據的框架,基本的原理是將Stream數據分成小的時間片段(幾秒),以類似batch批量處理的方式來處理這小部分數據。Spark Streaming構建在Spark上,一方面是因為Spark的低延遲執行引擎(100ms+),雖然比不上專門的流式數據處理軟體,也可以用於實時計算,另一方面相比基於Record的其它處理框架(如Storm),一部分窄依賴的RDD數據集可以從源數據重新計算達到容錯處理目的。此外小批量處理的方式使得它可以同時兼容批量和實時數據處理的邏輯和演演算法。方便了一些需要歷史數據和實時數據聯合分析的特定應用場合。
• Bagel: Pregel on Spark,可以用Spark進行圖計算,這是個非常有用的小項目。Bagel自帶了一個例子,實現了Google的PageRank演演算法。
• 當下Spark已不止步於實時計算,目標直指通用大數據處理平台,而終止Spark,開啟SparkSQL或許已經初見端倪。
• 近幾年來,大數據機器學習和數據挖掘的并行化演演算法研究成為大數據領域一個較為重要的研究熱點。早幾年國內外研究者和業界比較關注的是在 Hadoop 平台上的并行化演演算法設計。然而, HadoopMapReduce 平台由於網路和磁碟讀寫開銷大,難以高效地實現需要大量迭代計算的機器學習并行化演演算法。隨著 UC Berkeley AMPLab 推出的新一代大數據平台 Spark 系統的出現和逐步發展成熟,近年來國內外開始關注在 Spark 平台上如何實現各種機器學習和數據挖掘并行化演演算法設計。為了方便一般應用領域的數據分析人員使用所熟悉的 R 語言在 Spark 平台上完成數據分析,Spark 提供了一個稱為 SparkR 的編程介面,使得一般應用領域的數據分析人員可以在 R 語言的環境里方便地使用 Spark 的并行化編程介面和強大計算能力。

基本信息
- 外文名
- Spark
- 基於
- MapReduce演算法實現的分散式計算