統計機器翻譯
統計機器翻譯
統計機器翻譯(英語:c,簡寫為SMT)是機器翻譯的一種,也是目前非限定領域機器翻譯中性能較佳的一種方法。統計機器翻譯的基本思想是通過對大量的平行語料進行統計分析,構建統計翻譯模型,進而使用此模型進行翻譯。從早期基於詞的機器翻譯已經過渡到基於短語的翻譯,並正在融合句法信息,以進一步提高翻譯的精確性。
統計機器翻譯的首要任務是為語言的產生構造某種合理的統計模型,並在此統計模型基礎上,定義要估計的模型參數,並設計參數估計演演算法。早期的基於詞的統計機器翻譯採用的是雜訊通道模型,採用最大似然準則進行無監督訓練,而近年來常用的基於短語的統計機器翻譯則採用區分性訓練方法,一般來說需要參考語料進行有監督訓練。
早在1949年,瓦倫·韋弗就基於香農的資訊理論提出了統計機器翻譯的基本思想。而最早提出可行的統計機器翻譯模型的是IBM研究院的研究人員。他們在著名的文章《統計機器翻譯的數學理論:參數估計》中提出了由簡及繁的五種詞到詞的統計模型,分別被稱為IBM Model 1到IBM Model 5。這五種模型均為雜訊通道模型,而其中所提出的參數估計演演算法均基於最大似然估計。然而由於計算條件的限制和平行語料庫的缺乏,尚無法實現基於大規模數據的計算。其後,由Stephan Vogel提出了基於隱馬爾科夫模型的統計模型也受到重視,被認為可以較好的替代IBM Model 2.
在此文發表后6年,即1999年,約翰·霍普金斯大學夏季討論班集中了一批研究人員實現了GIZA軟體包,實現了IBM Model 1到IBM Model 5。Franz-Joseph Och在隨後對GIZA進行了優化,加快了訓練速度,特別是IBM Model 3到5的訓練。同時他還提出了更加複雜的Model 6。Och發布的軟體包被命名為GIZA++,直到現在,該軟體包還是絕大部分機器翻譯系統的基石。目前,針對大規模語料的訓練,已有GIZA++的若干并行化版本存在。
基於詞的統計機器翻譯雖然開闢了統計機器翻譯這條道路,其性能卻由於建模單元過小而受到極大限制。同時,產生性(generative)模型使得模型適應性較差。因此,許多研究者開始轉向基於短語的翻譯方法。Franz-Josef Och再次憑藉其出色的研究,推動了統計機器翻譯技術的發展,他提出的基於最大熵模型的區分性訓練方法使得統計機器翻譯的性能極大提高並在此後數年間遠遠超過其他方法。更進一步的,Och又提出修改最大熵方法的優化準則,直接針對客觀評價標準進行優化,從而產生了今天廣泛採用的最小錯誤訓練方法(Minimum Error Rate Training)。
另一件促進SMT進一步發展的重要發明是翻譯結果自動評價方法的出現,這些方法翻譯結果提供了客觀的評價標準,從而避免了人工評價的繁瑣與昂貴。這其中最為重要的評價是BLEU評價指標。雖然許多研究者抱怨BLEU與人工評價相差甚遠,並且對於一些小的錯誤極其敏感,絕大部分研究者仍然使用BLEU作為評價其研究結果的首要(如果不是唯一)的標準。
Moses是目前維護較好的開源機器翻譯軟體,由愛丁堡大學研究人員組織開發。其發布使得以往繁瑣複雜的處理簡單化。
雜訊通道模型假定,源語言中的句子 f(信宿)是由目標語言中的句子 e(信源)經過含有雜訊的通道編碼后得到的。那麼,如果已知了信宿 f和通道的性質,我們可以得到信源產生信宿的概率,即 p( e | f)。而尋找最佳的翻譯結果也就等同於尋找:
利用貝葉斯公式,並考慮對給定 f, p( f)為常量,上式即等同於
由此,我們得到了兩部分概率:
p( f | e),指給定信源,觀察到信號的概率。在此稱為 翻譯模型。 p( e),信源發生的概率。在此稱為 語言模型 可以這樣理解翻譯模型與語言模型,翻譯模型是一種語言到另一種語言的辭彙間的對應關係,而語言模型則體現了某種語言本身的性質。翻譯模型保證翻譯的意義,而語言模型保證翻譯的流暢。從中國對翻譯的傳統要求“信達雅”三點上看,翻譯模型體現了信與達,而雅則在語言模型中得到反映。
原則上任何語言模型均可以應用到上述公式中,因此以下討論集中於翻譯模型。在IBM提出的模型中,翻譯概率被定義為:
統計機器翻譯
其中( i, j)是詞對齊中的一條連接,表示源語言中的第 i個詞翻譯到目標語言中的第 j個詞。注意這裡的翻譯概率是詞之間而非位置之間的。IBM Model 2的參數中增加了詞在句子中的位置,公式為:
其中 I, J分別為源、目標語言的句子長度。
HMM模型將IBM Model 2中的絕對位置更改為相對位置,即相對上一個詞連接的位置,而IBM Model 3,4,5及Model 6引入了“Fertility Model”,代表一個詞翻譯為若干詞的概率。
在參數估計方面,一般採用最大似然準則進行無監督訓練,對於大量的“平行語料”,亦即一些互為翻譯的句子( fs, es)
由於並沒有直接的符號化最優解,實踐中採用EM演演算法。首先,通過現有模型,對每對句子估計( fs, es)全部可能的(或部分最可能的)詞對齊的概率,統計所有參數值發生的加權頻次,最後進行歸一化。對於IBM Model 1,2,由於不需要Fertility Model,有簡化公式可獲得全部可能詞對齊的統計量,而對於其他模型,遍歷所有詞對齊是NP難的。因此,只能採取折衷的辦法。首先,定義Viterbi對齊為當前模型參數θ下,概率最大的詞對齊:
在獲取了Viterbi對齊后,可以只統計該對齊結果的相關統計量,亦可以根據該對齊,做少許修改後(即尋找“臨近”的對齊)后再計算統計量。IBM 3,4,5及Model 6都是採用這種方法。
目前直接採用雜訊通道模型進行完整機器翻譯的系統並不多見,然而其副產品——詞對齊卻成為了各種統計機器翻譯系統的基石。時至今日,大部分系統仍然首先使用GIZA++對大量的平行語料進行詞對齊。由於所面對的平行語料越來越多,對速度的關注使得MGIZA++,PGIZA++等并行化實現得到應用。雜訊通道模型和詞對齊仍然是研究的熱點,雖然對於印歐語系諸語言,GIZA++的對齊錯誤率已經很低,在阿拉伯語,中文等語言與印歐語系語言的對齊中錯誤率仍然很高。特別是中文,錯誤率常常達到30%以上。所謂九層之台,起於累土,缺乏精確的詞對齊是中文機器翻譯遠遠落後於其他語言的原因。雖然目前出現了一些區分性詞對齊技術,無監督對齊仍然是其中的重要組成部分。
判別式模型雜訊通道模型(產生式模型)不同,它不應用貝葉斯公式,而是直接對條件概率 p( e | f)建模。
在這個框架下, M個特徵函數
通過參數化公式
其中是每個特徵函數的權重,也是模型所要估計的參數集,記為Λ。基於這個模型,獲取給定源語言句子 f,最佳翻譯的決策準則為:
簡而言之,就是找到使得特徵函數最大的解。
原則上,任何特徵函數都可以被置於此框架下,雜訊通道模型中的翻譯模型、語言模型都可以作為特徵函數。並且,在產生式模型中無法使用的“反向翻譯模型”,即 p( f, e)也可以很容易的被引入這個框架中。目前基於短語的翻譯系統中,最常用的特徵函數包括:
1.短語翻譯概率 2.詞翻譯概率(短語中每個詞的翻譯概率) 3.反向短語翻譯概率 4.反向詞翻譯概率 5.語言模型 而一些基於句法的特徵也在被加入。
優化準則指的是給定訓練語料,如何估計模型參數Λ。一般來說,訓練模型參數需要一系列已翻譯的文本,每個源語言句子 fs擁有 Rs個參考翻譯。
早期,區分性訓練被置於最大熵準則下,即:
這一準則簡單快速且由於優化目標是凸的,收斂速度快。然而,一個極大的問題是,“信息熵”本身和翻譯質量並無聯繫,優化信息熵以期獲得較好的翻譯結果在邏輯上較難說明。藉助客觀評價準則如BLEU,希望直接針對這些客觀準則進行優化能夠提升翻譯性能。由此而產生最小化錯誤率訓練演演算法。通過優化系統參數,使得翻譯系統在客觀評價準則上的得分越來越高,同時,不斷改進客觀評價準則,使得客觀評價準則與主觀評價準則越來越接近是目前統計機器翻譯的兩條主線。
使用這些客觀評價準則作為優化目標,即:
的一個主要問題是,無法保證收斂性。並且由於無法得到誤差函數(即客觀評價準則)的導數,限制了可使用的優化方法。目前常用的方法多為改進的Powell法,一般來說訓練時間頗長且無法針對大量數據進行訓練。
許多語言對的語序是有很大差別的。在前述詞對齊模型中,包含有詞調序模型,在區分性訓練中也需要較好的調序模型。調序模型可以是基於位置,也就是描述兩種語言每個句子不同位置的短語的調序概率,也可以是基於短語本身,例如Moses中的調序模型即是基於短語本身,描述在給定當前短語對條件下,其前後短語對是否互換位置。由於現實中的調序模型遠非“互換位置”這麼簡單,而是牽涉句法知識,調序的效果仍然不佳。目前重定位問題還是機器翻譯中亟待解決的問題。
無論採用哪種模型,在進行實際翻譯過程中,都需要進行解碼。所謂解碼,即是指給定模型參數和待翻譯句子,搜索使概率最大(或代價最小)的翻譯結果的過程。同許多序列標註問題,例如中文分詞問題類似,解碼搜索可以採用分支定界或啟髮式深度優先搜索(A*)方法。一般來說,搜索演演算法首先構造搜索網路,也就是將待翻譯句子與可能的翻譯結果融合為一個加權有限狀態轉換機(Weighted Finite State Transducer),而後在此網路上搜索最優路徑。
統計機器翻譯同大多數的機器學習方法相類似,有訓練及解碼兩個階段,其中訓練階段的目標是獲得模型參數,而解碼階段的目標則是利用所估計的參數和給定的優化目標,獲取待翻譯語句的最佳翻譯結果。對於基於短語的統計機器翻譯來說,“訓練”階段較難界定,嚴格來說,只有最小錯誤率訓練一個階段可稱為訓練。但是一般來說,詞對齊和短語抽取階段也被歸為訓練階段。
語料預處理階段,需要搜集或下載平行語料,所謂平行語料,指的是語料中每一行的兩個句子互為翻譯。目前網路上有大量可供下載的平行語料。搜尋適合目標領域(如醫療、新聞等)的語料是提高特定領域統計機器翻譯系統性能的重要方法。
在獲取語料后,需要進行一定得文本規範化處理,例如對英語進行詞素切分,例如將's獨立為一個詞,將與詞相連的符號隔離開等。而對中文則需要進行分詞。同是,儘可能過濾一些包含錯誤編碼的句子,過長的句子或長度不匹配(相差過大)的句子。
獲取的語料可分為三部分,第一部分用於詞對齊及短語抽取,第二部分用於最小錯誤率訓練,第三部分則用於系統評價。第二第三部分的數據中,每個源語言句子最好能有多條參考翻譯。
首先,使用GIZA++對平行語料進行對齊。由於GIZA++是“單向”的詞對齊,故而對齊應當進行兩次,一次從源到目標,第二次從目標到源。一般來說,GIZA++需要依次進行IBM Model 1, HMM及IBM Model 3,4的對齊,因IBM Model 2對齊效果不佳,而IBM Model 5耗時過長且對性能沒有較大貢獻。根據平行語料的大小不同及所設置的迭代次數多少,訓練時間可能很長。一個參考數據為,1千萬句中文-英文平行語料(約3億詞)在Inter Xeon 2.4GHz伺服器上運行時間約為6天。如果耗時過長可考慮使用MGIZA++和PGIZA++進行并行對齊(PGIZA++支持分散式對齊)。
其後,對兩個方向的GIZA++對齊結果進行合併,供短語抽取之用。
短語抽取的基本準則為,兩個短語之間有至少一個詞對有連接,且沒有任何詞連接於短語外的詞。Moses軟體包包含短語抽取程序,抽取結果將佔有大量的磁碟空間。建議若平行語料大小達到1千萬句,短語最大長度大於等於7,至少應準備500GB的存儲空間。
在短語抽取完畢后,可進行短語特徵提取,即計算短語翻譯概率及短語的詞翻譯概率。該需要對抽取的所有短語進行兩次排序,一般來說,中等規模(百萬句語料)的系統亦需要進行外部排序,磁碟讀寫速度對處理時間影響極大。建議在高速磁碟上運行。參考運行時間及磁碟空間消耗:前述千萬句語料庫,限制短語長度7,外部排序運行於SCSI Raid 0+1磁碟陣列,運行時間3日11小時,峰值磁碟空間消耗813GB。
語言模型訓練請參考語言模型。在區分性訓練框架下,允許使用多個語言模型,因此,使用由大語料訓練得到的無限領域語言模型配合領域相關的語言模型能夠得到最好的效果。
最小化錯誤率訓練通過在所準備的第二部分數據——優化集(Tuning Set)上優化特徵權重Λ,使得給定的優化準則最優化。一般常見的優化準則包括信息熵,BLEU,TER等。這一階段需要使用解碼器對優化集進行多次解碼,每次解碼產生N個得分最高的結果,並調整特徵權重。當權重被調整時,N個結果的排序也會發生變化,而得分最高者,即解碼結果,將被用於計算BLEU得分或TER。當得到一組新的權重,使得整個優化集的得分得到改進后,將重新進行下一輪解碼。如此往複直至不能觀察到新的改進。
根據選取的N值的不同,優化集的大小,模型大小及解碼器速度,訓練時間可能需要數小時或數日。
使用經最小化錯誤率訓練得到的權重,即可進行解碼。一般此時即可在測試集上進行系統性能評價。在客觀評價基礎上,有一些有條件的機構還常常進行主觀評價。
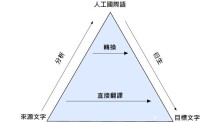
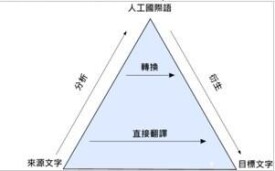
機器翻譯金字塔
同時,統計機器翻譯依賴巨大的語料庫,隨著語料庫資源越來越豐富和演演算法的日趨複雜,處理這些語料需要越來越強大的計算能力。長期以來,Google在機器翻譯領域的領先地位就得益於其強大的分散式計算能力。隨著分散式計算的普及,將機器翻譯相關技術并行化將是另一研究熱點。
最後,機器翻譯依賴客觀評價準則,而客觀評價準則最終要與主觀評價準則掛鉤。每年各類機器翻譯相關的會議上都會有若干關於客觀評價準則的研究發表,總的來說,評價翻譯的優劣本身就是一個人工智慧問題,其難度絕不在機器翻譯之下。
機器翻譯消除了不同文字和語言間的隔閡,堪稱高科技造福人類之舉。但其機譯譯文質量長期以來一直是個問題,離理想目標仍相差甚遠。中國知名數學家、語言學家周海中教授認為,在人類尚未明了大腦是如何進行語言的模糊識別和邏輯判斷的情況下,機譯要想達到“信、達、雅”的程度是不可能的。這一觀點恐怕道出了制約譯文質量的瓶頸所在。
基本信息
- 中文名
- 統計機器翻譯
- 外文名
- Statistical Machine Translation
- 類型
- 機器翻譯
- 簡寫
- SMT