共找到11條詞條名為編譯原理的結果 展開
編譯原理
計算機專業課程
編譯原理是計算機專業的一門重要專業課,旨在介紹編譯程序構造的一般原理和基本方法。內容包括語言和文法、詞法分析、語法分析、語法制導翻譯、中間代碼生成、存儲管理、代碼優化和目標代碼生成。
編譯原理是計算機專業設置的一門重要的專業課程。雖然只有少數人從事編譯方面的工作,但是這門課在理論、技術、方法上都對學生提供了系統而有效的訓練,有利於提高軟體人員的素質和能力。目前各個大學使用的教材機械工業出版社、國防工業出版社出版的《編譯原理》。
編譯器是將彙編或高級計算機語言翻譯為二進位機器語言代碼的計算機程序。編譯器將源程序(source language)編寫的程序作為輸入,翻譯產生目標語言(target language)機器代碼的等價程序。通常地,源程序為高級語言(high-level language),像C或C++、漢語語言程序等,而目標則是機器語言的目標代碼(object code,有時也稱作機器代碼(machine code)),也就是可以在計算機硬體中運行的機器代碼軟體程序。這一過程可以表示為:
源程序→編譯器→目標機器代碼程序
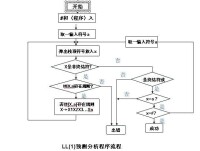
編譯原理實驗程序
C7 06 0000 0002 表示在IBM PC 上使用的Intel 8x86處理器將數字2移至地址0 0 0 0 (16進位)的指令。
但編寫這樣的代碼是十分費時和乏味的,這種代碼形式很快就被彙編語言(assembly language )代替了。在彙編語言中,都是以符號形式給出指令和存儲地址的。例如,彙編語言指令 MOV X,2 就與前面的機器指令等價(假設符號存儲地址X是0 0 0 0 )。彙編程序(assembler )將彙編語言的符號代碼和存儲地址翻譯成與機器語言相對應的數字代碼。
彙編語言大大提高了編程的速度和準確度,人們至今仍在使用著它,在編碼需要極快的速度和極高的簡潔程度時尤為如此。但是,彙編語言也有許多缺點:編寫起來也不容易,閱讀和理解很難;而且彙編語言的編寫嚴格依賴於特定的機器,所以為一台計算機編寫的代碼在應用於另一台計算機時必須完全重寫。
發展編程技術的下一個重要步驟就是以一個更類似於數學定義或自然語言的簡潔形式來編寫程序的操作,它應與任何機器都無關,而且也可由一個程序翻譯為可執行的代碼。例如,前面的彙編語言代碼可以寫成一個簡潔的與機器無關的形式 x = 2。
在1954年至1957年期間,IBM的John Backus帶領的一個研究小組對FORTRAN語言及其編譯器的開發,使得上面的擔憂不必要了。但是,由於當時處理中所涉及到的大多數程序設計語言的翻譯並不為人所掌握,所以這個項目的成功也伴隨著巨大的辛勞。幾乎與此同時,人們也在開發著第一個編譯器, Noam Chomsky開始了他的自然語言結構的研究。他的發現最終使得編譯器結構異常簡單,甚至還帶有了一些自動化。Chomsky的研究導致了根據語言文法(grammar ,指定其結構的規則)的難易程度以及識別它們所需的演演算法來為語言分類。正如現在所稱的-與喬姆斯基分類結構(Chomsky hierarchy )一樣-包括了文法的4個層次:0型、1型、2型和3型文法,且其中的每一個都是其前者的專門化。2型(或上下文無關文法(context-free grammar ))被證明是程序設計語言中最有用的,而且今天它已代表著程序設計語言結構的標準方式。
分析問題( parsing problem ,用於限定上下文無關語言的識別的有效演演算法)的研究是在20世紀60年代和70年代,它相當完善地解決了這一問題,現在它已是編譯理論的一個標準部分。它們與喬姆斯基的3型文法相對應。對它們的研究與喬姆斯基的研究幾乎同時開始,並且引出了表示程序設計語言的單詞(或稱為記號)的符號方式。
人們接著又深化了生成有效的目標代碼的方法,這就是最初的編譯器,它們被一直使用至今。人們通常將其誤稱為優化技術(optimization technique ),但因其從未真正地得到過被優化了的目標代碼而僅僅改進了它的有效性,因此實際上應稱作代碼改進技術(code improvement technique )。
這些程序最初被稱為編譯程序-編譯器,但更確切地應稱為分析程序生成器(parser generator ),這是因為它們僅僅能夠自動處理編譯的一部分。這些程序中最著名的是 Yacc (yet another compiler- compiler),它是由Steve Johnson在1975年為Unix系統編寫的。
類似地,有窮自動機的研究也發展了另一種稱為掃描程序生成器(scanner generator )的工具,Lex (與Yacc同時,由Mike Lesk為Unix系統開發的)是這其中的佼佼者。在20世紀70年代後期和80年代早期,大量的項目都關注於編譯器其他部分的生成自動化,這其中就包括代碼生成。這些嘗試並未取得多少成功,這大概是因為操作太複雜而人們又對其不甚了解。
編譯器設計最近的發展包括:首先,編譯器包括了更為複雜的演演算法的應用程序,它用於推斷或簡化程序中的信息;這又與更為複雜的程序設計語言(可允許此類分析)的發展結合在一起。其中典型的有用於函數語言編譯的Hindle y - Milner類型檢查的統一演演算法。
其次,編譯器已越來越成為基於窗口的交互開發環境(interactive development environment,IDE )的一部 分,它包括了編輯器、鏈接程序、調試程序以及項目管理程序。這樣的IDE的標準並沒有多少,但是已沿著這一方向對標準的窗口環境進行開發了。
C語言編譯器是一種現代化的設備,其需要藉助計算機編譯程序,C語言編譯器的設計是一項專業性比較強的工作,設計人員需要考慮計算機程序繁瑣的設計流程,還要考慮計算機用戶的需求。計算機的種類在不斷增加,所以,在對C語言編譯器進行設計時,一定要增加其適用性。C語言具有較強的處理能力,其屬於結構化語言,而且在計算機系統維護中應用比較多,C語言具有高效率的優點,在其不同類型的計算機中應用比較多。
C語言編譯器前端設計
編譯過程一般是在計算機系統中實現的,是將源代碼轉化為計算機通用語言的過程。編譯器中包含入口點的地址、名稱以及機器代碼。編譯器是計算機程序中應用比較多的工具,在對編譯器進行前端設計時,一定要充分考慮影響因素,還要對詞法、語法、語義進行分析。
1.詞法分析
詞法分析是編譯器前端設計的基礎階段,在這一階段,編譯器會根據設定的語法規則,對源程序進行標記,在標記的過程中,每一處記號都代表著一類單詞,在做記號的過程中,主要有標識符、關鍵字、特殊符號等類型,編譯器中包含詞法分析器、輸入源程序、輸出識別記號符,利用這些功能可以將字型大小轉化為熟悉的單詞。
2.語法分析
語法分析是指利用設定的語法規則,對記號中的結構進行標識,這包括句子、短語等方式,在標識的過程中,可以形成特殊的結構語法樹。語法分析對編譯器功能的發揮有著重要影響,在設計的過程中,一定要保證標識的準確性。
3.語義分析
語義分析也需要藉助語法規則,在對語法單元的靜態語義進行檢查時,要保證語法規則設定的準確性。在對詞法或者語法進行轉化時,一定要保證語法結構設置的合法性。在對語法、詞法進行檢查時,語法結構設定不合理,則會出現編譯錯誤的問題。前端設計對精確性要求比較好,設計人員能夠要做好校對工作,這會影響到編譯的準確性,如果前端設計存在失誤,則會影響C語言編譯的效果。
C語言編譯器總體設計
C語言編譯器是一種先進的設備,其可以將繁瑣複雜的程序轉換為機器語言,具有化繁為簡的功能,在對C語言編譯器進行劃分的過程中,需要了解語法構成原理,設計人員需要靈活掌握語言語法知識,還要應用C語言代碼轉化方式,在對C語言編譯器進行總體設計時,需要從以下幾個方面入手。
1.詞法分析
C語言程序具有一定的複雜性,語法分析是編譯的初級階段,這一過程主要是對詞法進行掃描,所以詞法分析階段,編譯器也被用作是掃描器,其主要的任務是將源程序中的字元進行連接,並且對其中的詞語進行識別,並且對辭彙進行轉化,將其轉換為內部編碼,並且對其語法進行分析與標記。單詞符號在編譯的過程中,一般會被轉化為二元式,單詞類別主要有二進位、分隔符、單詞等,計算機在正常工作時,會通過掃描器自動完成詞法掃描工作,這一過程也會自動將註釋進行刪除,會將源程序中的單詞進行自動識別,還會將其轉換為內部編碼。從工作方式角度來分析,編譯流程與語法屬於兩種介面方式,若是從功能上講,編譯器詞法分分析的過程主要就是將相應的字元源程序進行轉換處理,從而變成單詞串的形式。
2.語義分析
將編譯程序轉換為一種內部表現形式后,我們將該種內部表現形式稱之為中間語言或者是中間代碼,它含義明確、結構簡單,屬於一種記號系統。比如一些編譯程序,基本上沒有中間代碼,但是為了在實際應用中,確保機器的獨立運行,易於實現目標代碼的優化,在許多的編譯程序中均設置了中間語言。這種中間語言介於機器語言和源程序語言中,程序相對複雜,而C語言編譯器卻在很大程度上改變以上現狀,其語義分析和語法分析相對成熟,理論和演演算法比較完善,可仍舊存在的問題是沒有公認的形式系統,中間代碼仍舊接近於形式化的方法。
3.語法分析
語法分析主要是以單詞串形式的源程序作為分析與輸入對象,其最為根本的目標和任務就是為了以設計語言的語法規則為標準,對源程序的語法結構進行具體的分析,根據設計語言的語法規則,對組成這些源程序的語法成分進行分析,如函數、下標變數、各種程序語句、各種表達式等等,並且要通過正確性的語法檢查,將中間代碼進行階段處理。但是要注意的一點是根據需要進行了歸約處理,必然存在著相應語法錯誤,那麼可以將其中全部輸入的符號刪除,改變上述格局,進行移進和歸約分析,並且在此基礎上,不斷地尋找一個相應的策略,從而形成有效的語法分析方法。
《編譯原理》作為計算機專業的一門重要專業課程,是日後深入研究專業領域知識的基礎。這門課作為計算機科學與技術的專業課,融合了離散數學、數據結構、操作系統、計算機組成原理等多個學科的知識,屬於綜合性與理論性較強的一門課,由於編譯原理課程內容的以上特點,目前在實驗教學中仍存在一些問題。編譯原理實驗部分若要設計製作完整的編譯器,實驗周期長,涉及的模塊較多,各模塊間銜接較複雜,不易立即看到整體效果。
傳統編譯原理課程教學中存在的問題
計算機類專業本科生學習本專業的第一門語言課程是C語言。C語言由於其類型不安全性,容易出現一些難以捉摸的錯誤,使得學生難以定位和解決問題。如果能讓學生根據編譯器提供的提示信息,精確定位程序中的錯誤類型和位置,把編譯原理中所學用於實際C語言編程需求,這既完成了課程的教學內容,也提升了學生的軟體編程和系統分析的能力。
從普通高等院校的編譯原理教學實際出發,其課程覆蓋範圍一般僅限於編譯器的前端,即詞法分析、語法分析和語法制導翻譯等內容。這其中包括大量抽象且邏輯複雜的理論知識點,如形式語言理論、正規式、有限自動機、上下文無關文法、屬性文法和語法制導翻譯等。傳統的教學方式強調知識點的灌輸,讓學生解決孤立的單一問題,缺乏各知識點之間的關聯。這種“只見樹木,不見森林”的教學方式會極大地削弱學生的學習積極性,導致整體效果不佳。
以實踐為導向的互助式編譯原理教學
(一) 理論與實踐相銜接
理論知識的來源一般都有其確定的問題背景。脫離實際問題來進行理論教學,對學生實際能力的提升沒有益處。編譯原理課程中的大量理論知識,存在一種銜接遞進的關係,每個知識點的引入和拓展,都是對於現實遇到問題的解決路徑再現。因此,整個授課過程就在重現這種解決方案演變的變化歷程。而實現這一目標的關鍵之處,是教師從之前的“站到講台前”變到現在的“坐在學生中”。這一變化絕不僅僅是簡單地將所有問題留給學生,從“講授”變成“答疑”,而是從問題設計、思考啟迪、討論引導到過程管理等各方面都對教師提高了要求。特別是現代高級語言發展日新月異,各種新問題層出不窮,如何在面對開放性的未知問題時,從系統和整體的角度給出學生解決問題的方式方法,而不是給出具體每個問題的回答,這是對教師能力的一種新考驗。
(二) 編譯器設計實現方案
編譯原理課程教學理想情況,學生應該能夠獨立自主完成小型編譯系統的構造。實際教學中,學生只需吃透關鍵的幾條原理知識,如NFA的確定化,LL (1) 文法中FIRST和FOLLOW集合的構造,LR (1) 文法中識別活前綴DFA構造等,基本上已經滿足了課程考試要求。然而,僅靠理論學習對實現一個基礎編譯器來說是遠遠不足的。相比較於學生對理論知識的接受程度,學生自主動手完成編譯系統的能力缺乏就更為明顯。如何面對全體學生,制定出一套適用的實踐方案,是課程實際效用的關鍵。
解釋程序(interpreter):解釋程序是如同編譯器的一種語言翻譯程序。它與編譯器的不同之處在於:它立即執行源程序而不是生成在翻譯完成之後才執行的目標代碼。從原理上講,任何程序設計語言都可被解釋或被編譯,但是根據所使用的語言和翻譯情況,很可能會選用解釋程序而不用編譯器。例如,我們經常解釋BASIC語言而不是去編譯它。類似地,諸如LISP 的函數語言也常常是被解釋的。
解釋程序也經常用於教育和軟體的開發,此處的程序很有可能被翻譯若干次。而另一方面,當執行的速度是最為重要的因素時就使用編譯器,這是因為被編譯的目標代碼比被解釋的源代碼要快得多,有時要快10倍或更多。但是,解釋程序具有許多與編譯器共享的操作,而兩者之間也有一些混合之處。
彙編程序(assembler):彙編程序是用於特定計算機上的彙編語言的翻譯程序。正如前面所提到的,彙編語言是計算機的機器語言的符號形式,它極易翻譯。有時,編譯器會生成彙編語言以作為其目標語言,然後再由一個彙編程序將它翻譯成目標代碼。
連接程序(linker):編譯器和彙編程序都經常依賴於連接程序,它將分別在不同的目標文件中編譯或彙編的代碼收集到一個可直接執行的文件中。在這種情況下,目標代碼,即還未被連接的機器代碼,與可執行的機器代碼之間就有了區別。連接程序還連接目標程序和用於標準庫函數的代碼,以及連接目標程序和由計算機的操作系統提供的資源(例如,存儲分配程序及輸入與輸出設備)。連接程序現在正在完成編譯器最早的一個主要活動(這也是“編譯”一詞的用法,即通過收集不同的來源來構造)。連接過程對操作系統和處理器有極大的依賴性。
裝入程序(loader):編譯器、彙編程序或連接程序生成的代碼經常還不完全適用或不能執行,但是它們的主要存儲器訪問卻可以在存儲器的任何位置中且與一個不確定的起始位置相關。這樣的代碼被稱為是可重定位的(relocatable ),而裝入程序可處理所有的與指定的基地址或起始地址有關的可重定位的地址。裝入程序使得可執行代碼更加靈活,但是裝入處理通常是在後台(作為操作環境的一部分)或與連接相聯合時才發生,裝入程序極少會是實際的獨立程序。
預處理器(preprocessor ):預處理器是在真正的翻譯開始之前由編譯器調用的獨立程序。預處理器可以刪除註釋、包含其他文件以及執行宏(宏macro是一段重複文字的簡短描寫)替代。預處理器可由語言(如 C )要求或以後作為提供額外功能(諸如為FORTRAN提供Ratfor預處理器)的附加軟體。
調試程序(debugger ):調試程序是可在被編譯了的程序中判定執行錯誤的程序,它也經常與編譯器一起放在IDE 中。運行一個帶有調試程序的程序與直接執行不同,這是因為調試程序保存著所有的或大多數源代碼信息(諸如行數、變數名和過程)。它還可以在預先指定的位置(稱為斷點(breakpoint ))暫停執行,並提供有關已調用的函數以及變數的當前值的信息。為了執行這些函數,編譯器必須為調試程序提供恰當的符號信息,而這有時卻相當困難,尤其是在一個要優化目標代碼的編譯器中。因此,調試又變成了一個編譯問題。
描述器(profiler):描述器是在執行中搜集目標程序行為統計的程序。程序員特別感興趣的統計是每一個過程的調用次數和每一個過程執行時間所佔的百分比。這樣的統計對於幫助程序員提高程序的執行速度極為有用。有時編譯器也甚至無需程序員的干涉就可利用描述器的輸出來自動改進目標代碼。
項目管理程序(project manager):軟體項目通常大到需要由一組程序員來完成,這時對那些由不同人員操作的文件進行整理就非常重要了,而這正是項目管理程序的任務。例如,項目管理程序應將由不同的程序員製作的文件的各個獨立版本整理在一起,它還應保存一組文件的更改歷史,這樣就能維持一個正在開發的程序的連貫版本了(這對那些由單個程序員管理的項目也很有用)。項目管理程序的編寫可與語言無關,但當其與編譯器捆綁在一起時,它就可以保持有關特定的編譯器和建立一個完整的可執行程序的鏈接程序操作的信息。在Unix系統中有兩個流行的項目管理程序:sccs (source code control system )和rcs (revision control system )。
編譯器內部包括了許多步驟或稱為階段源代碼(phase),它們執行不同的邏輯操作。將這些階段設想為編譯器中一個個單獨的片斷是很有用的,儘管在應用中它們是經常組合在一起的,但它們掃描程序確實是作為單獨的代碼操作來編寫的。
掃描程序(scanner):在這個階段編譯器實際閱讀源程序(通常以分析程序字元流的形式表示)。掃描程序執行詞法分析註釋樹符號表(Lexical analysis ):它將字元序列收集到稱作記號錯誤處(token )的有意義單元中,記號同自然語言,如英源代碼理器語中的字詞相似。因此可以認為掃描程序執行與優化程序拼寫相似的任務。中間代碼例如在下面的代碼行(它可以是C程序的一部分)中:代碼生成器 a [index] = 4 + 2 這個代碼包括了1 2個非空字元,但只有 8個目標代碼記號:a 標識符目標代碼優化程序 [ 左括弧 i n d e x 標識符 ] 右括弧 = 賦值目標代碼 4 數字編譯器的階段 + 加號 2 數字 每一個記號均由一個或多個字元組成,在進一步處理之前它已被收集在一個單元中。掃描程序還可完成與識別記號一起執行的其他操作。例如,它可將標識符輸入到符號表中,將文字(litral)輸入到文字表中(文字包括諸如3 . 1415926535的數字常量,以及諸如“Hello,world ! ”的引用字元串)。
語法分析(parser ):語法分析程序從掃描程序中獲取記號形式的源代碼,並完成定義程序結構的語法分析(syntax analysis ),這與自然語言中句子的語法分析類似。語法分析定義了程序的結構元素及其關係。通常將語法分析的結果表示為分析樹(parse tree)或語法樹(syntax tree)。例如,還是那行C代碼,它表示一個稱為表達式的結構元素,該表達式是一個由左邊為下標表達式、右邊為整型表達式的賦值表達式組成。這個結構可按下面的形式表示為一個分析樹:請注意,分析樹的內部節點均由其表示的結構名標示出,而分析樹的葉子則表示輸入中的記號序列(結構名以不同字體表示以示與記號的區別)。分析樹對於顯示程序的語法或程序元素很有幫助,但是對於表示該結構卻顯得力不從心了。分析程序更趨向於生成語法樹,語法樹是分析樹中所含信息的濃縮(有時因為語法樹表示從分析樹中的進一步抽取,所以也被稱為抽象的語法樹(abstract syntax tree ))。下面是一個C賦值語句的抽象語法樹的例子:請注意,在語法樹中,許多節點(包括記號節點在內)已經消失。例如,如果知道表達式是一個下標運算,則不再需要用括弧“[”和“]”來表示該操作是在原始輸入中。
語義分析(semantic analyzer ):程序的語義就是它的“意思”,它與語法或結構不同。程序的語義確定程序的運行,但是大多數的程序設計語言都具有在執行之前被確定而不易由語法表示和由分析程序分析的特徵。這些特徵被稱作靜態語義(static semantic),而語義分析程序的任務就是分析這樣的語義(程序的“動態”語義具有隻有在程序執行時才能確定的特性,由於編譯器不能執行程序,所以它不能由編譯器來確定)。一般的程序設計語言的典型靜態語義包括聲明和類型檢查。由語義分析程序計算的額外信息(諸如數據類型)被稱為屬性(attribute),它們通常是作為註釋或“裝 飾”增加到樹中(還可將屬性添加到符號表中)。在正運行的C表達式 a [index] = 4 + 2 中,該行分析之前收集的典型類型信息可能是:a是一個整型值的數組,它帶有來自整型子範圍的下標;index則是一個整型變數。接著,語義分析程序將用所有的子表達式類型來標註語法樹,並檢查賦值是否使這些類型有意義了,如若沒有,則聲明一個類型匹配錯誤。在上例中,所有的類型均有意義,有關語法樹的語義分析結果可用以下註釋了的樹來表示。
優化程序(source code optimizer):編譯器通常包括許多代碼改進或優化步驟。絕大多數最早的優化步驟是在語義分析之後完 成的,而此時代碼改進可能只依賴於源代碼。這種可能性是通過將這一操作提供為編譯過程中的單獨階段指出的。每個編譯器不論在已完成的優化種類方面還是在優化階段的定位中都有很大的差異。在上例中,我們包括了一個源代碼層次的優化機會,也就是:表達式4 + 2可由編譯器計算先得到結果6 (這種優化稱為常量合併(constant folding ))。當然,還會有更複雜的情況。還是在上例中,通過將根節點右面的子樹合併為它的常量值,這個優化就可以直接在(註釋)語法樹上完成:儘管許多優化可以直接在樹上完成,但是在很多情況下,優化接近於彙編代碼線性化形式的樹更為簡便。這樣節點的變形有許多,但是三元式代碼(three-address code )(之所以這樣稱呼是因為它在存儲器中包含了3個(或3個以上)位置的地址)卻是標準選擇。另一個常見的選 擇是P -代碼(P - code ),它常用於Pascal編譯器中。在前面的例子中,原先的C表達式的三元式代碼應是:t = 4 + 2 a [ index] = t (請注意,這裡利用了一個額外的臨時變數t 存放加法的中間值)。這樣,優化程序就將這個代碼改進為兩步。首先計算加法的結果:t = 6 a [index] = t 接著,將t替換為該值以得到三元語句 a [index] = 6 ,指出源代碼優化程序可能通過將其輸出稱為中間代碼(intermediate code )來使用三元式代碼。中間代碼一直是指一種位於源代碼和目標代碼(例如三元式代碼或類似的線性表示)之間的代碼表示形式。但是,我們可以更概括地認為它是編譯器使用的源代碼的任何一個內部表示。此時,也可將語法樹稱作中間代碼,源代碼優化程序則確實能繼續在其輸出中使用這個表示。有時,這個中間代碼也稱作中間表示(intermediate representation,IR)。
代碼生成(code generator):代碼生成器得到中間代碼(IR),並生成目標機器的代碼。正是在編譯的這個階段中,目標機器的特性成為了主要因素。當它存在於目標機器時,使用指令不僅是必須的而且數據的形式表示也起著重要的作用。例如,整型數據類型的變數和浮點數據類型的變數在存儲器中所佔的位元組數或字數也很重要。在上面的示例中,現在必須決定怎樣存儲整型數來為數組索引生成代碼。例如,下面是所給表達式的一個可能的樣本代碼序列(在假設的彙編語言中):
M O V R0,index ;;
value of index -> R0 M U L R0,2 ;;
double value in R0 M O V R1,&a ;;
address of a -> R1 A D D R1,R0 ;;
add R0 to R1 M O V *R1,6 ;;
constant 6 -> address in R1
在以上代碼中,為編址模式使用了一個類似C的協定,因此& a是a的地址(也就是數組的基地址),* R1則意味著間接寄存器地址(因此最後一條指令將值6存放在R1包含的地址中)。這個代碼還假設機器執行位元組編址,並且整型數佔據存儲器的兩個位元組(所以在第2條指令中用2作為乘數)。
目標代碼(target code optimizer ):在這個階段中,編譯器嘗試著改進由代碼生成器生成的目標代碼。這種改進包括選擇編址模式以提高性能、將速度慢的指令更換成速度快的,以及刪除多餘的操作。在上面給出的樣本目標代碼中,還可以做許多更改:在第2條指令中,利用移位指令替代乘法(通常地,乘法很費時間),還可以使用更有效的編址模式(例如用索引地址來執行數組 存儲)。使用了這兩種優化后,目標代碼就變成:
MOV R0,index ;;
value of index -> R0 SHL R0 ;;
double value in R0 MOV &a[R0],6 ;;
constant 6 -> address a + R0
到這裡就是編譯原理的簡要描述,但還應特彆強調編譯器在其結構細節上差別很大。
編譯原理一直是計算機學習的必修課.
當然,由編譯器的階段使用的演演算法與支持這些階段的數據結構之間的交互是非常強大的。編譯器的編寫者儘可能有效實施這些方法且不引起複雜性。理想的情況是:與程序大小成線性比例的時間內編譯器,換言之就是,在0 ( n )時間內,n是程序大小的度量(通常是字元數)。本節將講述一些主要的數據結構,它們是其操作部分階段所需要的,並用來在階段中交流信息。
記號(token):當掃描程序將字元收集到一個記號中時,它通常是以符號表示這個記號;這也就是說,作為一個枚舉數據類型的值來表示源程序的記號集。有時還必須保留字元串本身或由此派生出的其他信息(例如:與標識符記號相關的名字或數字記號值)。在大多數語言中,掃描程序一次只需要生成一個記號(這稱為單符號先行(single symbol lookahead))。在這種情況下,可以用全程變數放置記號信息;而在別的情況(最為明顯的是FORTRAN)下,則可能會需要一個記號數組。
語法樹(syntax tree):如果分析程序確實生成了語法樹,它的構造通常為基於指針的標準結構,在進行分析時動態分配該結構,則整棵樹可作為一個指向根節點的單個變數保存。結構中的每一個節點都是一個記錄,它的域表示由分析程序和之後的語義分析程序收集的信息。例如,一個表達式的數據類型可作為表達式的語法樹節點中的域。有時為了節省空間,這些域也是動態分配或存放在諸如符號表的其他數據結構中,這樣就可以有選擇地進行分配和釋放。實際上,根據它所表示的語言結構的類型(例如:表達式節點對於語句節點或聲明節點都有不同的要求),每一個語法樹節點本身都可能要求存儲不同的屬性。在這種情況下,可由不同的記錄表示語法樹中的每個節點,每個節點類型只包含與本身相關的信息。
符號表(symbol table):這個數據結構中的信息與標識符有關:函數、變數、常量以及數據類型。符號表幾乎與編譯器的所有階段交互:掃描程序、分析程序或將標識符輸入到表格中的語義分析程序;語義分析程序將增加數據類型和其他信息;優化階段和代碼生成階段也將利用由符號表提供的信息選 出恰當的代碼。因為對符號表的訪問如此頻繁,所以插入、刪除和訪問操作都必須比常規操作更有效。儘管可以使用各種樹的結構,但雜湊表卻是達到這一要求的標準數據結構。有時在一個列表或棧中可使用若干個表格。
常數表(literal table):常數表的功能是存放在程序中用到的常量和字元串,因此快速插入和查找在常數表中也十分重要。但是,在其中卻無需刪除,這是因為它的數據全程應用於程序而且常量或字元串在該表中只出現一次。通過允許重複使用常量和字元串,常數表對於縮小程序在存儲器中的大小顯得非常重要。在代碼生成器中也需要常數表來構造用於常數和在目標代碼文件中輸入數據定義的符號地址。
中間代碼(intermediate code):根據中間代碼的類型(例如三元式代碼和P -代碼)和優化的類型,該代碼可以是文本串的數組、臨時文本文件或是結構的連接列表。對於進行複雜優化的編譯器,應特別注意選擇允許簡單重組的表示。
臨時文件(temporary file):計算機過去一直未能在編譯器時將整個程序保留在存儲器中。這一問題已經通過使用臨時文件來保存翻譯時中間步驟的結果或通過“匆忙地”編譯(也就是只保留源程序早期部分的足夠信息用以處理翻譯)解決了。存儲器的限制現在也只是一個小問題了,現在可以將整個編譯單元放在存儲器之中,特別是在可以分別編譯的語言中時。但是偶爾還是會發現需要在某些運行步驟中生成中間文件。其中典型的是代碼生成時需要反填(backpatch)地址。例如,當翻譯如下的條件語句時 if x = 0 then ... else ... 在知道else部分代碼的位置之前必須由文本跳到else部分:
CMP X,0 JNE NEXT ;;
location of NEXT not yet known < code for then-part > NEXT : < code for else-part >
通常,必須為NEXT的值留出一個空格,一旦知道該值后就會將該空格填上,利用臨時文件可以很容易地做到這一點。
如果想利用上面的編譯原理開發一套屬於自己的編程語言,或者想在一個產品中嵌入編程語言,可以參考zengl開源網開發的zengl編程語言,該編程語言為國人使用C語言開發,裡面包含兩個部分,一個是編譯器,一個是解釋執行中間代碼的虛擬機。編譯器包含了詞法掃描,語法分析,中間代碼輸出等,虛擬機則類似JAVA一樣解釋執行中間代碼。作者將所有的版本都公布出來,好讓讀者可以由淺入深的做研究,並且為了證明該編程語言的實用性,還結合SDL遊戲開發庫開發了一款圖形界面和命令行界面的21點撲克小遊戲。
zengl編程語言目前適用平台為windows和linux (最開始在Linux下使用gcc開發,後來移植到windows平台)
可從許多不同的角度來觀察編譯器的結構,還有其他一些可能的觀點:編譯器的物理結構、操作的順序等等。由於編譯器的結構對其可靠性、有效性、可用性以及可維護性都有很大的影響,所以編譯器的編寫者應熟悉儘可能多的有關編譯器結構的觀點。
在這個觀點中,已將分析源程序以計算其特性的編譯器操作歸為編譯器的分析(analysis)部分,而將生成翻譯代碼時所涉及到的操作稱作編譯器的綜合(synthesis )部分。當然,詞法分析、語法分析和語義分析均屬於分析部分,而代碼生成卻是綜合部分。在優化步驟中,分析和綜合都有。分析正趨向於易懂和更具有數學性,而綜合則要求更深的專業技術。因此,將分析步驟和綜合步驟兩者區分開來以便發生變化時互不影響是很有用的。
本觀點認為,將編譯器分成了只依賴於源語言(前端(front end ))的操作和只依賴於目標語言(後端(back end ))的操作兩部分。這與將其分成分析和綜合兩部分是類似的:掃描程序、分析程序和語義分析程序是前端,代碼生成器是後端。但是一些優化分析可以依賴於目標語言,這樣就是屬於後端了,然而中間代碼的綜合卻經常與目標語言無關,因此也就屬於前端了。在理想情況下,編譯器被嚴格地分成這兩部分,而中間表示則作為其間的交流媒介。這一結構對於編譯器的可移植性(portability)十分重要,此時設計的編譯器既能改變源代碼(它涉及到重寫前端),又能改變目標代碼(它還涉及到重寫後端)。在實際中,這是很難 做到的,而且稱作可移植的編譯器仍舊依賴於源語言和目標語言。其部分原因是程序設計語言和機器構造的快速發展以及根本性的變化,但是有效地保持移植一個新的目標語言所需的信息 或使數據結構普遍地適合改變為一個新的源語言所需的信息卻十分困難。然而人們不斷分離前端和後端的努力會帶來更方便的可移植性。
編譯器發現,在生成代碼之前多次處理整個源程序很方便。這些重複就是遍( pass)。首遍是從源中構造一個語法樹或中間代碼,在它之後的遍是由處理中間表示、向它增加信息、更換結構或生成不同的表示組成。遍可以和階段相應,也可無關-遍中通常含有若干個階段。實際上,根據語言的不同,編譯器可以是一遍(one pass )-所有的階段由一遍完成,其結果是編譯得很好,但(通常)代碼卻不太有效。Pascal語言和C 語言均允許單遍編譯。(Modula - 2語言的結構則要求編譯器至少有兩遍)。大多數帶有優化的編譯器都需要超過一遍:典型的安排是將一遍用於掃描和分析,將另一遍用於語義分析和源代碼層優化,第3遍用於代 碼生成和目標層的優化。更深層的優化則可能需要更多的遍:5遍、6遍、甚至8遍都是可能的。
程序設計語言的詞法和語法結構通常用形式的術語指定,並使用正則表達式和上下文無關文法。但是,程序設計語言的語義通常仍然是由英語(或其他的自然語言)描述的。這些描述(與形式的詞法及語法結構一起)一般是集中在一個語言參考手冊(language reference manual )或語言定義(language definition)之中。因為編譯器的編寫者掌握的技術對於語言的定義有很大的影響,所以在使用了一種新的語言之後,語言的定義和編譯器同時也能夠得到開發。類似地,一種語言的定義對於構造編譯器所需的技術也有很 大的關係。編譯器的編寫者更經常遇到的情況是:正在實現的語言是眾所周知的並已有了語言定義。有時這個語言定義已達到了某個語言標準(language standard )的層次,語言標準是指得到諸如美國國家標準協會(American National Standards Institute ,ANSI )或國際標準化組織(International Organization for Standardization,ISO )的官方標準組織批准的標準。FORTRAN、 Pascal和C語言就具有ANSI標準,Ada有一個通過了美國政府批准的標準。在這種情況下,編譯器的編寫者必須解釋語言的定義並執行符合語言定義的編譯器。通常做到這一點並不容易,但是有時由於有了標準測試程序集(測試組(test suite )),就能夠測試編譯器(Ada有這樣一個測試組),這又變得簡單起來了。有時候,一種語言可從數學術語的形式定義(formal definition )中得到它的語義。現在人們已經使用了許多方法,儘管一個稱作表示語義(denotational semantics )的方法已經成為較為常用的方法,在函數編程共同體中尤為如此,但現在仍然沒有一種可成為標準的方法。當語言有一個形式定義時,那麼在理論上就有可能給出編譯器與該定義一致的數學證明,但是由於這太難了,而幾乎從未有人做過。無論怎樣,運行時環境的結構和行為是尤其受到語言定義影響的編譯器構造的一個方面。
編輯器(editor):編譯器通常接受由任何生成標準文件(例如ASCII文件)的編輯器編寫的源程序。現在,編譯器已與另一個編輯器和其他程序捆綁進一個交互的開發環境-IDE中。此時,儘管編輯器仍然生成標準文件,但會轉向正被討論的程序設計語言的格式或結構。這樣的編輯器稱為基於結構的(structure based ),且它早已包括了編譯器的某些操作;因此,程序員就會在程序的編寫時而不是在編譯時就得知錯誤了。從編輯器中也可調用編譯器以及與它共用的程序,這樣程序員無需離開編輯器就可執行程序。
這門課程關注的是編譯器方面的產生原理和技術問題,似乎和計算機的基礎領域不沾邊,可是編譯原理卻一直作為大學本科的 必修課程,同時也成為了研究生入學考試的必考內容。編譯原理及技術從本質上來講就是一個演演算法問題而已,當然由於這個問題十分複雜,其解決演演算法也相對複雜。我們學的數據結構與演演算法分析也是講演演算法的,不過講的基礎演演算法,換句話說講的是演演算法導論,而編譯原理這門課程講的就是比較專註解決一種的演演算法了。在20世紀 50年代,編譯器的編寫一直被認為是十分困難的事情,第一Fortran的編譯器據說花了18年的時間才完成。在人們嘗試編寫編譯器的同時,誕生了許多跟 編譯相關的理論和技術,而這些理論和技術比一個實際的編譯器本身價值更大。就猶如數學家們在解決著名的哥德巴赫猜想一樣,雖然沒有最終解決問題,但是其間 誕生不少名著的相關數論。
C語言的源程序和對應的可執行程序執行時在內存中的運行結構,實現這一轉換的最主要的過程就是編譯。
源程序是給人看的,本質上就是文本文件,可以用Linux中的vi或Windows中的記事本之類的文本編輯程序打開、編寫,但計算機無法直接執行源程序,需要通過一個專門的程序將源程序編譯為計算機可執行程序,這個專門的程序就是編譯器。編譯過程主要分為詞法分析、語法分析、中間代碼生成、目標代碼生成(忽略預處理、語義分析、優化等)。下面我們依次簡要講解編譯的主要過程。
詞法分析
人眼中看到的源代碼是這樣的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 
intfun(inta,intb);
intm=10;
intmain() 
{ 
inti=4;
intj=5;
m=fun(i,j);
return0; 
} 
intfun(inta,intb)
{
intc=0;
c=a+b;
returnc; 
} |
這裡看不出關鍵字、運算符、標識符,甚至看不出哪幾個字元屬於同一個符號。編譯的第一階段是詞法分析,目的就是在連續的字元中識別出一個一個的符號,並儘可能地識別出符號的屬性。
人們在看C語言源程序時,藉助空格、括弧等一眼就可以看出標識符、關鍵字。與人相比,現在計算機的智能還是相當低的,無法像人那樣同時看多個字元,只能依據一個非常機械的“電子版”詞法,一個字元一個字元地識別。“電子版”詞法是將狀態轉換圖的思路融匯在詞法分析器的代碼中得以體現的。詞法分析器從源程序的字元串中識別出一個個符號(token),並按序保存。
在詞法分析階段能夠識別出一些符號的含義,它們包括關鍵字、數字、字元串、分隔符,這些符號的含義不需要其他符號的輔助就能確定本身的含義。比如,“int”一定代表整數類型,它不可能是一個變數名稱,也不可能是一個運算符。
而另外一些符號需要通過前後的其他符號才能確定出準確含義。比如“m”,在詞法階段僅能判斷這是一個標識符,但是如果不對所在的句做分析,就無法得知這個標識符代表一個變數還是一個函數。更多詳細的信息需要對符號所在的句型做分析才能獲得。這部分工作由語法分析來完成。
語法分析
如果說詞法分析的作用是從連續的字元中識別出標識符、關鍵字、數字、運算符並存儲為符號(token)流,語法分析的作用就是從詞法分析識別出的符號流中識別出符合C語言語法的語句。
因為計算機無法像人那樣同時看多個標識符、關鍵字、數字、運算符,無法像人那樣一眼看出這是一個函數聲明,那是一個if語句,只能非常笨拙地一個符號一個符號去識別。與詞法分析器有些類似,語法分析器也是依據用計算機表示的語法,一個符號一個符號地識別出符合C語言語法的語句。語法的計算機表示就是產生式。在語法分析器中把通過產生式產生的C語言語法映射成一套模板,並把這套模板融匯在語法分析器的程序中。語法分析器的作用就是將詞法分析器識別出的符號(token)一個一個地與這套模板進行匹配,匹配上這套模板中的某個語法,就可以識別出一句完整的語句,並確定這條語句的語法。
我們以案例中“int fun(int a,int b);”這條函數聲明語句為例描述這個過程,它與語句模板的匹配情景如圖1-38所示。
這段token流最終與函數聲明模板相匹配,在匹配成功后,計算機就認為此語句為函數聲明語句,並以語法樹的形式在內存中記錄下來。
以樹型結構來記錄分析出的語句是一個非常巧妙、深謀遠慮、通盤考慮的選擇。一方面,樹型結構能夠“記住”源程序全部的“意思”,另一方面,樹型結構更容易對應到運行時結構。
從語法樹到中間代碼再到目標代碼
至此,語法樹已經承載了源程序的全部信息,後續的轉換工作就和源程序沒關係了。
如果希望一步到位,從語法樹轉換為目標代碼,理論上和實際上都是可行的。但計算機存在多種CPU硬體平台,考慮到程序在不同CPU之間的可移植性,先轉換成一個通用的、抽象的“CPU指令”,這就是中間代碼最初的設計思想。然後根據具體選定的CPU,將中間代碼落實到具體CPU的目標代碼。
語法樹是個二維結構,中間代碼是准一維結構,語法樹到中間代碼的轉換過程,本質上是將二維結構轉換為準一維結構的過程。中間代碼特別是RTL已經可以和運行時結構一一對應了。
運行時結構也是一維的,圖1-40左側部分的轉換結果將更貼近運行時結構。
選定具體的CPU、操作系統后,中間代碼就可以轉換為目標代碼——彙編代碼(我們配置的是AT&T彙編),這時操作系統的影響還比較小。然後由彙編器依照選定操作系統的目標文件格式,將.s文件轉換為具體的目標文件,對於Linux而言是.o文件,對於Windows而言是.obj文件。目標文件中已經是選定的CPU的機器指令了。
最後鏈接器把一個或多個目標文件(庫文件本質上也是目標文件)鏈接成符合選定操作系統指定格式的可執行文件。
通過操作系統,可執行程序就可以被載入內存執行,形成前兩節我們所看到的運行時結構。
本書後續內容將詳細講解編譯的主要過程:詞法分析、語法分析、中間代碼到目標代碼,然後是彙編與鏈接,最後講解預處理。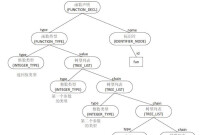
編譯原理

基本信息
- 中文名
- 編譯原理
- 外文名
- principle of compiling
- 學科門類
- 計算機專業的一門重要專業課
- 研究範圍
- 編譯程序構造的一般原理和基本方法
- 應用
- 計算機