特徵碼
特徵碼
特徵碼(attribute code)用來判斷某段數據屬於哪個計算機欄位。共計40個字元。
特徵碼的獲取不可能再是簡單的取出一段代碼來,而是分段的,中間可以包含任意的內容(也就是增加了一些不參加比較的“掩碼位元組”,在出現“掩碼位元組”的地方,出現什麼內容都不參加比較)。這就是曾經提出的廣譜特徵碼的概念。
隨著網路技術和信息技術的飛速發展,網路已經成為人們獲取信息的一個重要途徑。現有的搜索引擎面臨的最大一個問題就是返回的結果集中包含大量重複的信息。如何更有效地幫助用戶獲取所需要的信息,能夠快速、準確地為用戶提供信息,是網路信息服務面臨的新課題。優化搜索結果可以採用多種手段,如通過提取網頁的特徵進行基於內容的信息檢索,利用用戶反饋的信息進一步精確檢索結果,將結果集中的重複信息儘可能地消除等。
由於網路信息分佈的特點,網站上的信息存在相互轉載及鏡像站點等情況。出現相同網頁主要有以下幾種情形:網頁的URL完全相同;網頁的URL形式不同,但網站域名所對應的IP是相同的;URL雖然不同,但網頁內容完全相同;URL不同,為不同的網頁形式,但網頁上主要內容是相同的。本文主要討論對於網頁內容重複性的消除。
網頁為半結構化的信息形式,它與單純的文本文檔並不完全相同。網頁 中的有效信息主要包括以下幾方面的內容:網頁標題、網頁正文、導航信息、超鏈接信息、圖片聲音等多媒體信息等。從以上信息中可以提取出有關網頁內容的一些特徵。首先對檢索結果集中的網頁進行預處理,將其餘信息屏蔽,獲得網頁的正文信息,然後用後面介紹的演演算法對網頁正文進行去重處理。即判斷是否已經有相同內容的網頁在結果集中,若有,則進行刪除或合併處理,若沒有,則將該網頁保留在檢索結果集中。網頁去重系統主要結構如圖1所示。
對網頁進行去重處理,實質上是從一批網頁中將內容相同或相近的網頁分為一類,進行聚類處理。用傳統演演算法進行聚類處理,只能將同一大類的網頁聚合為一類,與傳統意義上的聚類處理不同,網頁去重需要對網頁進行較為精確的歸類。如果嚴格按照網頁內容進行分類,則分類結果中類別會很大,導致在確定一個網頁屬於哪一類時計算所花費的時間過大。如果直接將網頁正文逐字進行匹配處理來實現歸類,也同樣會出現計算量過大,而在響應時間上無法承受的問題。較好的方法是從網頁正文中抽取出少量信息構成特徵碼,在歸類時,以特徵碼取代網頁,通過判斷特徵碼是否相同或相近來判斷相應的網頁內容是否是重複的。
(1)網頁特徵碼
圖2 特徵碼結構
(2)網頁重複性判斷演演算法
提取出網頁的特徵碼之後,下一步工作是依據特徵碼判斷網頁正文是否重複。假設網頁a對應的特徵碼為Ta,網頁b所對應的特徵碼為Tb,判斷a與b是否為重複網頁的主要步驟為:
1)比較Ta與Tb的主碼部分,若兩者主碼完全相同,則認為網頁a與網頁b是內容相同的網頁,轉4),否則轉2);
2)若Ta與Tb的主碼比較結果為以下情形之一:①其中一個的主碼為另一個主碼的真子集;②兩者不互為真子集,但兩者主碼取交集的結果較大,則轉3)作進一步判斷;若兩者主碼取交集為空或交集結果較小,則認為網頁a與網頁b是內容不同的網頁,轉4);
3)對Ta、Tb主碼的交集,即兩者相同的主碼部分進行處理,判斷對應的輔碼是否相同,若完全相同或大部分相同,則認為網頁a與網頁b是內容相同的網頁,若相同的輔碼很少,則認為網頁a與網頁b是不同的網頁,轉4);
4)演演算法結束。
在判斷演演算法中,對於以下情況認為兩個網頁是相同的:一個網頁內容是另一個網頁的部分內容,或兩個網頁雖然不完全相同,但其中大部分內容是相同的。可以通過設定一定的閾值對演演算法中的不確定因素進行判定。如兩者交集結果超過其中任何一個的80%,則表示兩者交集結果較大,反之當小於20%時,認為兩者交集結果較小;在對輔碼進行比較時,當相同的輔碼佔80%以上時,認為輔碼大部分相同。可以根據實際檢索的結果,將閾值調整至一個比較合適的取值範圍,獲取較為滿意的檢索結果。
(3)演演算法有效性分析
網頁重複性判斷演演算法是否有效,關鍵是特徵碼與網頁正文內容之間的對應關係,若不同內容的網頁對應的特徵碼是不同的,則保證了演演算法的有效性。若出現多個不同內容的網頁有相同的特徵碼,則會將不同內容的網頁歸併到一類進行處理。若單純從文字上看,以中文網頁為例,常用的漢字大約為6700個,特徵碼主碼的長度為n,則對於不同網頁出現相同特徵碼主碼的概率為1/(6700)n。雖然對於一些熱門新聞,段首文字多以“據報道”、“新華社”等文字開頭,若有m段文字以這樣的固定詞開頭,(m小於n),出現重複特徵碼的概率為1/(6700)n-m,當n-m或n的取值稍大,如大於5時,這樣的概率值是很小的。同時在演演算法中,還考慮了輔碼的作用,當出現主碼部分相同時,進一步判斷輔碼的分佈以確定特徵碼是否相同。
(1)數據結構的選擇
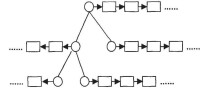
圖3 擴展二叉排序樹結構
為描述方便,以下所說相等是指兩個特徵碼對應的網頁內容相同或相近,不等是指兩個特徵碼對應的網頁內容不同。當出現特徵碼相等的情況時,需要進行合併處理。演演算法採用擴展二叉排序樹為主要的數據結構,在傳統的二叉排序樹的每個結點中增加一個指針,該指針指向由特徵碼構成的鏈表,稱為“輔指針”。輔指針指向與該結點對應網頁內容相近的網頁特徵碼,這樣就可以較方便地處理網頁合併的情形。最終保留在檢索結果集中的是擴展二叉排序樹中各結點表示的特徵碼對應的網頁。擴展二叉排序樹結構如圖3所示。
(2)特徵碼歸類過程
二叉排序樹的構建過程也就是對特徵碼進行歸類處理的過程。對於一個新處理的特徵碼,在二叉排序樹中沒有找到可以合併的結點時,直接對該特徵碼進行插入操作即可。在二叉排序樹中找到相等的特徵碼時,該特徵碼要進行合併操作,而不同於普通意義上二叉排序樹的查找操作。當二叉排序樹為空時,將新處理的特徵碼作為新結點插入樹中,插入新結點時,該結點的輔指針為空。當二叉排序樹非空時,首先將新處理的特徵碼與根結點表示的特徵碼比較,若相等,則進行合併處理,若不等,則根據新處理的特徵碼與根結點表示的特徵碼之間的大小關係,分別在左子樹或右子樹上繼續進行比較,在比較過程中,若出現相等的情形,則將新處理的特徵碼與相應的結點進行合併,若在整個比較過程中,始終出現的是不等的情況,則說明新處理的特徵碼所對應的網頁內容還沒有在二叉排序樹中,將其作為一個新接點插入。
假設網頁x對應的特徵碼為Tx,網頁y所對應的特徵碼為Ty,Tx為新處理的特徵碼,Ty為二叉排序樹中出現的與Tx相等的特徵碼,採取以下策略進行合併:1)若Tx與Ty的主碼完全相同,則二叉排序樹不需要做任何改動,直接將檢索結果集中網頁x刪除;2)若Tx主碼為Ty主碼的真子集,則將Tx與Ty輔指針所指向鏈表中各結點的特徵碼進行比較,若無相等的特徵碼,則將Tx作為一個新結點插入Ty輔指針所指向鏈表中;3)若Ty主碼為Tx主碼的真子集,將Tx取代二叉排序樹中結點Ty,同時將Ty依據2)中的原則插入Tx輔指針所指向鏈表中;4)Tx與Ty不互為真子集,但兩者主碼取交集的結果較大,處理方法同2)。
(3)演演算法效率分析
不管新處理特徵碼是進行合併或插入,均要先進行查找比較,已確定插入的位置或合併的結點。對二叉排序樹進行比較,在結點出現概率為隨機概率分佈的情況下,平均查找長度小於等於2(1+1/m)lnm,m為二叉排序樹中結點的個數,平均查找長度與logm成數量級,即比較過程的時間複雜度為O(logm)。插入結點過程只是一些指針的移動,時間可以忽略不計。由於特徵碼主要由各段段首字及每段中前n個標點符號前的文字構成,因此對特徵碼的提取不需要對整個網頁正文都掃描一次,特徵碼的提取時間與處理的網頁正文長度有關,可以看成是一線性關係,特徵碼提取的時間複雜度為O(n)。
當前單純意義上的病毒已逐步被木馬、蠕蟲所代替。操作系統的升級為後門病毒大規模的破壞提供了便利,並且從自啟動發展為註冊系統服務,從單進程發展為守護進程和遠程線程注入,甚至採用驅動技術來隱藏後門程序,讓用戶手動查找愈加困難。在這種局勢下,各種新技術和殺軟被不斷開發出來,和病毒進行著沒有硝煙的較量。
所謂特徵碼,就是防毒軟體從病毒樣本中提取的不超過64位元組且能代表病毒特徵的十六進位代碼。主要有單一特徵碼、多重特徵碼和複合特徵碼這三種類型。特徵碼提取的思路是:首先獲取一個病毒程序的長度,根據樣本長度可將文件分為若干份(分段的方法在很大程度上避免了採用單一特徵碼誤報病毒現象的發生,也可以避免特徵碼過於集中造成的誤報),每份選取16B或32B的特徵串,若該信息是通用信息或者全零位元組則捨棄,認為或隨機調整偏移最後重新選取。最後,將選取出來的幾段特徵碼及它們的偏移量存入病毒庫,標示出病毒的名稱即可。根據這個思路可編寫出特徵碼提取程序實現自動提取,並保存病毒記錄。在掃描病毒時,防毒軟體將目標文件通過模式匹配演演算法與病毒庫中的特徵碼進行比對,以確定是否染毒。
(1)特徵碼的定位
單一特徵碼掃描,就是從病毒樣本中提取連續的能標示此病毒的若干個位元組。其好處在於開銷小,便於升級和維護病毒庫。但這種技術容易導致誤查誤殺,已較少使用。對於多重特徵碼,可在單一特徵碼掃描的基礎上進一步提取不連續的若干段特徵碼,僅當待檢測文件完全符合這多段特徵碼時才報苦。這樣可以減少誤殺率,提高查殺的準確度,因此成為多數防毒軟體的首選技術。用“逐位元組替換法”可手動定位多重特徵碼。把目標木馬服務端或病毒逐位元組地替換為OOh或fh(其他亦可),每替換一次存為一個文件,然後對生成的幾份文件殺毒,未被刪除的就是被修改了特徵碼的文件。匯總被修改的位元組就得到了殺軟對該木馬或病毒所定義的“特徵碼”。然而,手工操作和佔用空間都過於龐大,可用分段法加以改進,即逐步縮小特徵碼所在範圍。實驗中選取某防毒軟體對黑客工具進行特徵碼定位。首先以128 B為替換單位,從查殺后的文件可知特徵碼的偏移和範圍,之後還原代碼,再以32 B為單位對該範圍進行替換並查殺,最後使用逐位元組替換定位出連續的特徵碼位元組。這樣每次僅需幾兆的空間,且速度很快。整個由粗略到精細的定位。至此,多重特徵碼定位成功,只需任選一段特徵碼來定位,修改後就可以逃過查殺。
(2)特徵碼的修改
對定位后的特徵碼進行修改便能逃過查殺。對可執行文件,要根據彙編代碼來修改特徵碼,首先進行反彙編,使用調試器(如ollydbg)調試程序,並根據特徵碼的文件偏移地址轉換成的虛擬地址找到彙編指令。修改方法主要有:修改字元串大小寫法、等價替換法、指令順序調換法、通用跳轉法。許多病毒採用自動變形技術來逃避特徵碼檢測,即所謂的多動態病毒,它在外觀形態上沒有固定的特徵碼川。病毒的多態致使對其代碼段的加密能完全改變原有特徵碼,因此搖在零區域加入解密代碼來解密,然後使用JMP指令跳回原指令代碼執行,由於對某一位元組執行XOR兩次后可還原代碼,因此可以手動加密代碼,下次病毒執行時,可以解密代碼並執行。致使特徵碼完全變樣,達到免殺。
特徵碼技術具有低誤報率、高準確性、高可靠等不可比擬的優勢,其技術機理和執行流程也非常成熟。為了彌補特徵碼技術的被動性,建議輔以如下幾種防病毒新技術:
(1)輸入表關聯特徵碼
病毒運行時需要調用存在於輸入表中的API函數,如果將特徵碼鎖定在可執行文件的“敏感”區域—輸入表中,由於輸入表位置固定,因此不能用通用跳轉法來修改特徵碼,這樣能有效地保護特徵碼。
(2)偽特徵碼
防病毒軟體可以檢測某一段自己的特徵碼,如果發現它被填充為O,那麼就激活原先設置的隨機效用的偽特徵碼並報替,就算能找到這些特徵碼,對於查殺沒有影響。
(3)廣譜特徵串過濾技術
為應對不斷變化和未知的病毒,啟髮式掃描方式出現了。啟髮式掃描是通過分析指令出現的順序,或特定組合情況等常見病毒的標準特徵來決定文件是否感染未知病毒。因為病毒要達到感染和破壞的目的,通常的行為都會有一定的特徵,例如非常規讀寫文件,終結自身,複製自身到系統目錄,修改註冊表某一鍵值,調用特定的AIP函數等等。所以可以根據掃描特定的行為或多種行為的組合來判斷一個程序是否為病毒。這種啟髮式掃描比起靜態的特徵碼掃描要先進的多,可以達到一定的未知病毒處理能力,但仍會有不準確的時候。特別是因為無法確定一定是病毒,而不可能做未知病毒殺毒。