詞性標註
詞性標註
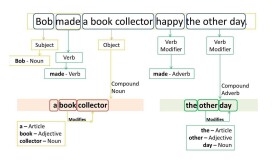
詞性標註(Part-Of-Speech tagging, POS tagging)也被稱為語法標註(grammatical tagging)或詞類消疑(word-category disambiguation),是語料庫語言學(corpus linguistics)中將語料庫內單詞的詞性按其含義和上下文內容進行標記的文本數據處理技術。
詞性標註可以由人工或特定演演算法完成,使用機器學習(machine learning)方法實現詞性標註是自然語言處理(Natural Language Processing, NLP)的研究內容。常見的詞性標註演演算法包括隱馬爾可夫模型(Hidden Markov Model, HMM)、條件隨機場(Conditional random fields, CRFs)等。
詞性標註主要被應用於文本挖掘(text mining)和NLP領域,是各類基於文本的機器學習任務,例如語義分析(semantic analysis)和指代消解(coreference resolution)的預處理步驟。
詞性標註是隨著語料庫的建立而提出的,在其發展初期是語料庫中語法分析器(parser)的組件之一,詞性標註的早期工作包括賓夕法尼亞大學(University of Pennsylvania)TDAP(Transformations and Discourse Analysis Project)項目中的語法結構模型,以及Sheldon Klein和Robert F. Simmons通過人工指定的上下文規則建立的自動化詞性標註系統CGC(Computational Grammar Coder)。1971年,Barbara B. Greene和Gerald M. Rubin以Klein and Simmons (1963)為基礎開發了詞性標註系統TAGGIT,並首次對大規模詞庫Brown Corpus進行了詞性標註。
1985年,Andrew D. Beale使用統計學習方法為Lancaster-Oslo-Bergen Corpus開發了詞性標註系統CLAWS (Constituent-Likelihood Automatic Word tagging System),1987年,Steven DeRose使用動態規劃方法對Brown Corpus進行了詞性標註。統計學習方法的成功和更大規模的語料庫,例如British National Corpus的出現,為詞性標註研究中機器學習方法的引入奠定了基礎。二十世紀80-90年代,學界開始嘗試使用隱馬爾可夫模型(Hidden Markov Model, HMM)進行詞性標註並取得了成功,以HMM為代表的詞性標註方法也由此被廣泛應用於各類大規模語料庫的NLP和文本挖掘。
詞性標註在本質上是分類問題,將語料庫中的單詞按詞性分類。一個詞的詞性由其在所屬語言的含義、形態和語法功能決定。以漢語為例,漢語的詞類系統有18個子類,包括7類體詞,4類謂詞、5類虛詞、代詞和感嘆詞。詞類不是閉合集,而是有兼詞現象,例如“制服”在作為“服裝”和作為“動作”時會被歸入不同的詞類,因此詞性標註與上下文有關。對詞類的理論研究可以得到基於人工規則的詞性標註方法,這類方法對句子的形態進行分析並按預先給定的規則賦予詞類。
詞性標註的機器學習演演算法主要為序列模型,包括HMM、最大熵馬爾可夫模型(Maximum Entropy Markov Model, MEMM)、條件隨機場(Conditional random fields,CRFs)等廣義上的馬爾可夫模型成員,以及以循環神經網路(Recurrent Neural Network, RNN)為代表的深度學習演演算法。此外,一些機器學習的常規分類器,例如支持向量機(Support Vector Machine, SVM)在改進后也可用於詞性標註。
詞性標註是文本數據的預處理環節之一,原始文本在NLP或文本挖掘應用中,首先通過字元分割(word segmentation)和字元嵌入(word embedding)被向量化,隨後通過詞性標註得到高階層特徵,並輸入語法分析器執行語義分析(sentiment analysis)、指代消解(coreference resolution)等任務。
基本信息
- 外文名
- Part-Of-Speech tagging, POS tagging
- 應用
- 文本挖掘,自然語言處理
- 學科
- 語言學,人工智慧