字元編碼
字元編碼
字元編碼(英語:Character encoding)也稱字集碼,是把字符集中的字元編碼為指定集合中某一對象(例如:比特模式、自然數序列、8位組或者電脈衝),以便文本在計算機中存儲和通過通信網路的傳遞。常見的例子包括將拉丁字母表編碼成摩斯電碼和ASCII。其中,ASCII將字母、數字和其它符號編號,並用7比特的二進位來表示這個整數。通常會額外使用一個擴充的比特,以便於以1個位元組的方式存儲。
在計算機技術發展的早期,如ASCII(1963年)和EBCDIC(1964年)這樣的字符集逐漸成為標準。但這些字符集的局限很快就變得明顯,於是人們開發了許多方法來擴展它們。對於支持包括東亞CJK字元家族在內的寫作系統的要求能支持更大量的字元,並且需要一種系統而不是臨時的方法實現這些字元的編碼。
美國(國家)信息交換標準(代)碼,一種使用7個或8個二進位位進行編碼的方案,最多可以給256個字元 (包括字母、數字、標點符號、控制字元及其他符號)分配(或指定)數值。
ASCII碼於1961年提出,用於在不同計算機硬體和軟體系統中實現數據傳輸標準化,在大多數的小型機和全部的個人計算機都使用此碼。ASCII碼劃分為兩個集合:128個字元的標準ASCII碼和附加的128個字元的擴充和ASCII碼。比較EBCDIC。其中95個字元可以顯示。另外33個不可以顯示。標準ASCII碼為7位,擴充為8位。
目前使用最廣泛的西文字符集及其編碼是 ASCII 字符集和 ASCII 碼( ASCII 是 American Standard Code for Information Interchange 的縮寫),它同時也被國際標準化組織( International Organization for Standardization, ISO )批准為國際標準。
基本的 ASCII 字符集共有 128 個字元,其中有 96 個可列印字元,包括常用的字母、數字、標點符號等,另外還有 32 個控制字元。標準 ASCII 碼使用 7 個二進位對字元進行編碼,對應的 ISO 標準為 ISO646 標準。下表展示了基本 ASCII 字符集及其編碼:
字母和數字的 ASCII 碼的記憶是非常簡單的。我們只要記住了一個字母或數字的 ASCII 碼(例如記住 A 為 65 , 0 的 ASCII 碼為 48 ),知道相應的大小寫字母之間差 32 ,就可以推算出其餘字母、數字的 ASCII 碼。
雖然標準 ASCII 碼是 7 位編碼,但由於計算機基本處理單位為位元組( 1byte = 8bit ),所以一般仍以一個位元組來存放一個 ASCII 字元。每一個位元組中多餘出來的一位(最高位)在計算機內部通常保持為 0 (在數據傳輸時可用作奇偶校驗位)。
由於標準 ASCII 字符集字元數目有限,在實際應用中往往無法滿足要求。為此,國際標準化組織又制定了 ISO2022 標準,它規定了在保持與 ISO646 兼容的前提下將 ASCII 字符集擴充為 8 位代碼的統一方法。 ISO 陸續制定了一批適用於不同地區的擴充 ASCII 字符集,每種擴充 ASCII 字符集分別可以擴充 128 個字元,這些擴充字元的編碼均為高位為 1 的 8 位代碼(即十進位數 128~255 ),稱為擴展 ASCII 碼。
通過了解字元的存儲編碼,可以解決很多由編碼不匹配引起的問題,比如網頁亂碼、郵件亂碼,本文簡單扼要地闡明了ASCII編碼、EBCDIC編碼、GB2312編碼、UTF-8編碼、以及Base64編碼。
在顯示器上看見的文字、圖片等信息在電腦裡面 其實並不是我們看見的樣子,即使你知道所有信息都存儲在硬碟里,把它拆開也看不見裡面有任何東西,只有些碟片。假設,你用顯微鏡把碟片放大,會看見碟片表面凹凸不平,凸起的地方被磁化,凹的地方是沒有被磁化;凸起的地方代表數字1,凹的地方代表數字0。硬碟只能用0和1來表示所有文字、圖片等信息。那麼字母”A”在硬碟上是如何存儲的呢?可能小張計算機存儲字母”A”是1100001,而小王存儲字母”A”是11000010,這樣雙方交換信息時就會誤解。比如小張把1100001發送給小王,小王並不認為1100001是字母”A”,可能認為這是字母”X”,於是小王在用記事本訪問存儲在硬碟上的1100001時,在屏幕上顯示的就是字母”X”。也就是說,小張和小王使用了不同的編碼表。小張用的編碼表是ASCII,ASCII編碼表把26個字母都一一的對應到2進位1和0上;小王用的編碼表可能是EBCDIC,只不過EBCDIC編碼與ASCII編碼中的字母和01的對應關係不同。一般地說,開放的操作系統(LINUX 、WINDOWS等)採用ASCII 編碼,而大型主機系統(MVS 、OS/390等)採用EBCDIC 編碼。在發送數據給對方前,需要事先告知對方自己所使用的編碼,或者通過轉碼,使不同編碼方案的兩個系統可溝通自如。
ASCII碼使用7位2進位數表示一個字元,7位2進位數可以表示出2的7次方個字元,共128個字元。EBCDIC碼使用8位,可以表示出2的8次方個字元,256個字元。
無論是ASCII碼還是EBCDIC碼,都無法對擁有幾萬個的漢字進行編碼。因為上面已經提過,7位2進位數最多對應上128個字元,8位最多對應上256個字元。
0~31及127(共33個)是控制字元或通信專用字元(其餘為可顯示字元),如控制符:LF(換行)、CR(回車)、FF(換頁)、DEL(刪除)、BS(退格)、BEL(振鈴)等;通信專用字元:SOH(文頭)、EOT(文尾)、ACK(確認)等;ASCII值為8、9、10和13分別轉換為退格、製表、換行和回車字元。它們並沒有特定的圖形顯示,但會依不同的應用程序而對文本顯示有不同的影響。
32~126(共95個)是字元(32sp是空格),其中48~57為0到9十個阿拉伯數字,65~90為26個大寫英文字母,97~122為26個小寫字母,其餘為一些標點符號、運算符號等。
為了擴充ASCII編碼,以用於顯示本國的語言,不同的國家和地區制定了不同的標準,由此產生了 GB2312, BIG5, JIS 等各自的編碼標準。這些使用 2 個位元組來代表一個字元的各種漢字延伸編碼方式,稱為 ANSI 編碼,又稱為"MBCS(Muilti-Bytes Charecter Set,多位元組字符集)"。在簡體中文系統下,ANSI 編碼代表 GB2312 編碼,在日文操作系統下,ANSI 編碼代表 JIS 編碼,所以在中文 windows下要轉碼成gb2312,gbk只需要把文本保存為ANSI 編碼即可。不同 ANSI 編碼之間互不兼容,當信息在國際間交流時,無法將屬於兩種語言的文字,存儲在同一段 ANSI 編碼的文本中。一個很大的缺點是,同一個編碼值,在不同的編碼體系裡代表著不同的字。這樣就容易造成混亂。導致了unicode碼的誕生。
其中每個語言下的ANSI編碼,都有一套一對一的編碼轉換器,Unicode變成所有編碼轉換的中間介質。所有的編碼都有一個轉換器可以轉換到Unicode,而Unicode也可以轉換到其他所有的編碼。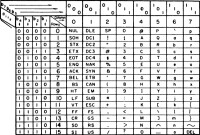
字元編碼
GB2312 也是ANSI編碼里的一種,對ANSI編碼最初始的ASCII編碼進行擴充,為了滿足國內在計算機中使用漢字的需要,中國國家標準總局發布了一系列的漢字字符集國家標準編碼,統稱為GB碼,或國標碼。其中最有影響的是於1980年發布的《信息交換用漢字編碼字符集 基本集》,標準號為GB 2312-1980,因其使用非常普遍,也常被通稱為國標碼。GB2312編碼通行於我國內地;新加坡等地也採用此編碼。幾乎所有的中文系統和國際化的軟體都支持GB 2312。
GB 2312是一個簡體中文字符集,由6763個常用漢字和682個全形的非漢字字元組成。其中漢字根據使用的頻率分為兩級。一級漢字3755個,二級漢字3008個。由於字元數量比較大,GB2312採用了二維矩陣編碼法對所有字元進行編碼。首先構造一個94行94列的方陣,對每一行稱為一個“區”,每一列稱為一個“位”,然後將所有字元依照下表的規律填寫到方陣中。這樣所有的字元在方陣中都有一個唯一的位置,這個位置可以用區號、位號合成表示,稱為字元的區位碼。如第一個漢字“啊”出現在第16區的第1位上,其區位碼為1601。因為區位碼同字元的位置是完全對應的,因此區位碼同字元之間也是一一對應的。這樣所有的字元都可通過其區位碼轉換為數字編碼信息。GB2312字元的排列分佈情況見表1-4。
表1-4 GB2312 字元編碼分佈表
| 分區範圍 | 符號類型 |
| 第01區 | 中文標點、數學符號以及一些特殊字元 |
| 第02區 | 各種各樣的數學序號 |
| 第03區 | 全形西文字元 |
| 第04區 | 日文平假名 |
| 第05區 | 日文片假名 |
| 第06區 | 希臘字母表 |
| 第07區 | 俄文字母表 |
| 第08區 | 中文拼音字母表 |
| 第09區 | 製表符號 |
| 第10-15區 | 無字元 |
| 第16-55區 | 一級漢字(以拼音字母排序) |
| 第56-87區 | 二級漢字(以部首筆畫排序) |
| 第88-94區 | 無字元 |
GB2312字元在計算機中存儲是以其區位碼為基礎的,其中漢字的區碼和位碼分別佔一個存儲單元,每個漢字佔兩個存儲單元。由於區碼和位碼的取值範圍都是在1-94之間,這樣的範圍同西文的存儲表示衝突。例如漢字‘珀’在GB2312中的區位碼為7174,其兩位元組表示形式為71,74;而兩個西文字元‘GJ’的存儲碼也是71,74。這種衝突將導致在解釋編碼時到底表示的是一個漢字還是兩個西文字元將無法判斷。
為避免同西文的存儲發生衝突,GB2312字元在進行存儲時,通過將原來的每個位元組第8bit設置為1同西文加以區別,如果第8bit為0,則表示西文字元,否則表示GB2312中的字元。實際存儲時,採用了將區位碼的每個位元組分別加上A0H(160)的方法轉換為存儲碼,計算機存儲規則是此編碼的補碼,而且是位碼在前,區碼在後。例如漢字‘啊’的區位碼為1601,其存儲碼為B0A1H,其轉換過程為:
| 區位碼 | 區碼轉換 | 位碼轉換 | 存儲碼 |
| 1001H | 10H+A0H=B0H | 01H+A0H=A1H | B0A1H |
GB2312編碼用兩個位元組(8位2進位)表示一個漢字,所以理論上最多可以表示256×256=65536個漢字。但這種編碼方式也僅僅在中國行得通,如果您的網頁使用的GB2312編碼,那麼很多外國人在瀏覽你的網頁時就可能無法正常顯示,因為其瀏覽器不支持GB2312編碼。當然,中國人在瀏覽外國網頁(比如日文)時,也會出現亂碼或無法打開的情況,因為我們的瀏覽器沒有安裝日文的編碼表。
GBK即漢字內碼擴展規範,K為擴展的漢語拼音中“擴”字的聲母。英文全稱Chinese Internal Code Specification。GBK編碼標準兼容GB2312,共收錄漢字21003個、符號883個,並提供1894個造字碼位,簡、繁體字融於一庫。GB2312碼是中華人民共和國國家漢字信息交換用編碼,全稱《信息交換用漢字編碼字符集——基本集》,1980年由國家標準總局發布。基本集共收入漢字6763個和非漢字圖形字元682個,通行於中國大陸。新加坡等地也使用此編碼。GBK是對GB2312-80的擴展,也就是CP936字碼表 (Code Page 936)的擴展(之前CP936和GB 2312-80一模一樣)。
GB 2312的出現,基本滿足了漢字的計算機處理需要,但對於人名、古漢語等方面出現的罕用字,GB 2312不能處理,這導致了後來GBK及GB 18030漢字字符集的出現。
GBK採用雙位元組表示,總體編碼範圍為8140-FEFE,首位元組在81-FE 之間,尾位元組在40-FE 之間,剔除 xx7F一條線。總計23940 個碼位,共收入21886個漢字和圖形符號,其中漢字(包括部首和構件)21003 個,圖形符號883 個。P-Windows3.2和蘋果OS以GB2312為基本漢字編碼, Windows 95/98則以GBK為基本漢字編碼。
GBK碼對字型檔中偏移量的計算公式為:
[(GBKH-0x81)*0xBE+(GBKL-0x41)]*(漢字離散后每個漢字點陣所佔用的位元組)
字元有一位元組和雙位元組編碼,00–7F範圍內是一位,和ASCII保持一致,此範圍內嚴格上說有96個字元和32個控制符號。
之後的雙位元組中,前一位元組是雙位元組的第一位。總體上說第一位元組的範圍是81–FE(也就是不含80和FF),第二位元組的一部分領域在40–7E,其他領域在80–FE。
在台灣、香港與澳門地區,使用的是繁體中文字符集。而1980年發布的GB2312面向簡體中文字符集,並不支持繁體漢字。在這些使用繁體中文字符集的地區,一度出現過很多不同廠商提出的字符集編碼,這些編碼彼此互不兼容,造成了信息交流的困難。為統一繁體字符集編碼,1984年,台灣五大廠商宏碁、神通、佳佳、零壹以及大眾一同制定了一種繁體中文編碼方案,因其來源被稱為五大碼,英文寫作Big5,後來按英文翻譯回漢字后,普遍被稱為大五碼。
大五碼是一種繁體中文漢字字符集,其中繁體漢字13053個,808個標點符號、希臘字母及特殊符號。大五碼的編碼碼錶直接針對存儲而設計,每個字元統一使用兩個位元組存儲表示。第1位元組範圍81H-FEH,避開了同ASCII碼的衝突,第2位元組範圍是40H-7EH和A1H-FEH。因為Big5的字元編碼範圍同GB2312字元的存儲碼範圍存在衝突,所以在同一正文不能對兩種字符集的字元同時支持。
Big5編碼的分佈如表1-5所示,Big5字元主要部分集中在三個段內:標點符號、希臘字母及特殊符號;常用漢字;非常用漢字。其餘部分保留給其他廠商支持。
表1-5 Big5字元編碼分佈表
| 編碼範圍 | 符號類別 |
| 8140H-A0FEH | 保留(用作造字區) |
| A140H-A3BFH | 標點符號、希臘字母及特殊符號 |
| A3C0H-A3FEH | 保留(未開放用於造字區) |
| A440H-C67EH | 常用漢字(先按筆劃,再按部首排序) |
| C6A1H-C8FEH | 保留(用作造字區) |
| C940H-F9D5H | 非常用漢字(先按筆劃,再按部首排序) |
| F9D6H-FEFEH | 保留(用作造字區) |
Big5編碼推出后,得到了繁體中文軟體廠商的廣泛支持,在使用繁體漢字的地區迅速普及使用。目前,Big5編碼在台灣、香港、澳門及其他海外華人中普遍使用,成為了繁體中文編碼的事實標準。在網際網路中檢索繁體中文網站,所打開的網頁中,大多都是通過Big5編碼產生的文檔。
如上ANSI編碼條例中所述,世界上存在著多種編碼 方式,在ANSi編碼下,同一個編碼值,在不同的編碼體系裡代表著不同的字。可能最終顯示的是中文,也可能顯示的是日文。在ANSI編碼體系下,要想打開一個文本文件,不但要知道它的編碼方式,還要安裝有對應編碼表,否則就可能無法讀取或出現亂碼。為什麼電子郵件和網頁都經常會出現亂碼,就是因為信息的提供者可能是日文的ANSI編碼體系和信息的讀取者可能是中文的編碼體系,他們對同一個二進位編碼值進行顯示,採用了不同的編碼,導致亂碼。這個問題促使了unicode碼的誕生。
如果有一種編碼,將世界上所有的符號都納入其中,無論是英文、日文、還是中文等,大家都使用這個編碼表,就不會出現編碼不匹配現象。每個符號對應一個唯一的編碼,亂碼問題就不存在了。這就是Unicode編碼。
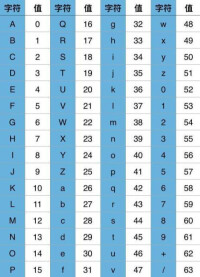
Unicode當然是一個很大的集合,現在的規模可以容納100多萬個符號。每個符號的編碼都不一樣,比如,U+0639表示阿拉伯字母Ain,U+0041表示英語的大寫字母A,“漢”這個字的Unicode編碼是U+6C49。
Unicode固然統一了編碼方式,但是它的效率不高,比如UCS-4(Unicode的標準之一)規定用4個位元組存儲一個符號,那麼每個英文字母前都必然有三個位元組是0,這對存儲和傳輸來說都很耗資源。
為了提高Unicode的編碼效率,於是就出現了UTF-8編碼。UTF-8可以根據不同的符號自動選擇編碼的長短。比如英文字母可以只用1個位元組就夠了。
UTF-8的編碼是這樣得出來的,以”漢”這個字為例:
“漢”字的Unicode編碼是U+00006C49,然後把U+00006C49通過UTF-8編碼器進行編碼,最後輸出的UTF-8編碼是E6B189。
字元編碼
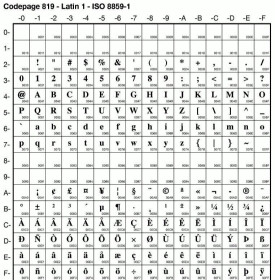
Base64編碼
為了能讓郵件系統正常的收發信件,就需要把由其他編碼存儲的符號轉換成ASCII碼來傳輸。比如,在一端發送GB2312編碼->根據Base64規則->轉換成ASCII碼,接收端收到ASCII碼->根據Base64規則->還原到GB2312編碼。。
基本信息
- 中文名
- 字元編碼
- 外文名
- Character encoding
- 別名
- 字集碼
- 計算公式
- [(GBKH-0x81)*0xBE+(GBKL-0x41)]*
- 標準
- ASCII、EBCDIC