ZFS
128bit文件系統
ZFS文件系統的英文名稱為Zettabyte File System,也叫動態文件系統(Dynamic File System),是第一個128位文件系統。最初是由Sun公司為Solaris 10操作系統開發的文件系統。作為OpenSolaris開源計劃的一部分,ZFS於2005年11月發布,被Sun稱為是終極文件系統,經歷了 10 年的活躍開發。而最新的開發將全面開放,並重新命名為 OpenZFS
ZFS是一款128bit文件系統,總容量是現有64bit文件系統的1.84x10^19倍,其支持的單個存儲卷容量達到16EiB(2^64byte,即 16x1024x1024TB);一個zpool存儲池可以擁有2^64個卷,總容量最大256ZiB(2^78byte);整個系統又可以擁有2^64個存儲 池。可以說在相當長的未來時間內,ZFS幾乎不太可能出現存儲空間不足的問題。另外,它還擁有自優化,自動校驗數據完整性,存儲池/卷系統易管理等諸多優點。較ext3系統有較大運行速率,提高大約30%-40%。
ZFS是基於存儲池的,與典型的映射物理存儲設備的傳統文件系ZFS統不同,ZFS所有在存儲池中的文件系統都可以使用存儲池的資源。
什麼是ZFS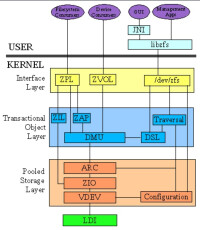
ZFS
ZFS 文件系統是一個革命性的全新的文件系統,它從根本上改變了文件系統的管理方式,這個文件系統的特色和其帶來的好處至今沒有其他文件系統可以與之媲美,ZFS 被設計成強大的、可升級並易於管理的。
ZFS 用“存儲池”的概念來管理物理存儲空間。過去,文件系統都是構建在物理設備之上的。為了管理這些物理設備,並為數據提供冗餘,“卷管理”的概念提供了一個單設備的映像。但是這種設計增加了複雜性,同時根本沒法使文件系統向更高層次發展,因為文件系統不能跨越數據的物理位置。
ZFS 完全拋棄了“卷管理”,不再創建虛擬的卷,而是把所有設備集中到一個存儲池中來進行管理!“存儲池”描述了存儲的物理特徵(設備的布局,數據的冗餘等等),並扮演一個能夠創建文件系統的專門存儲空間。從此,文件系統不再局限於單獨的物理設備,而且文件系統還允許物理設備把他們自帶的那些文件系統共享到這個“池”中。你也不再需要預先規劃好文件系統的大小,因為文件系統可以在“池”的空間內自動的增大。當增加新的存貯介質時,所有“池”中的所有文件系統能立即使用新增的空間,而不需要額外的操作。在很多情況下,存儲池扮演了一個虛擬內存。
創建一個池的例子
| 1 | #zpoolcreatetankmirrorc1t0d0c1t1d0 |
這是一個被鏡像了的池,名叫“tank”。如果命令中的設備包含有其他的文件系統或者以別的形式被使用,那麼命令不能執行。
要查看池是否成功創建,用 zpool list 命令,例如:
1 2 3 | #zpoollist NAMESIZEUSEDAVAILCAPHEALTHALTROOT tank80G137K80G0%ONLINE- |
不同於傳統文件系統需要駐留於單獨設備或者需要一個卷管理系統去使用一個以上的設備,ZFS創建在虛擬的,被稱為“zpools”的存儲池之上(存儲池最早在AdvFS實現,並且加到後來的Btrfs)。每個存儲池由若干虛擬設備(virtual devices,vdevs)組成。這些虛擬設備可以是原始磁碟,也可能是一個RAID1鏡像設備,或是非標準RAID等級的多磁碟組。於是zpool上的文件系統可以使用這些虛擬設備的總存儲容量。
可以使用磁碟限額以及設置磁碟預留空間來限制存儲池中單個文件系統所佔用的空間。
ZFS是一個128位的文件系統,這意味著它能存儲1800億億(18.4 × 10)倍於當前64位文件系統的數據。ZFS的設計如此超前以至於這個極限就當前現實實際可能永遠無法遇到。項目領導Bonwick曾說:“要填滿一個128位的文件系統,將耗盡地球上所有存儲設備。除非你擁有煮沸整個海洋的能量,不然你不可能將其填滿。(Populating 128-bit file systems would exceed the quantum limits of earth-based storage. You couldn't fill a 128-bit storage pool without boiling the oceans.)”
以下是ZFS的一些理論極限:
· 2—任意文件系統的快照數量(2 × 10)
· 2—任何單獨文件系統的文件數(2 × 10)
· 16exabytes (2byte)—文件系統最大尺寸
· 16exabytes (2byte)—最大單個文件尺寸
· 16exabytes (2byte)—最大屬性大小
· 128Zettabytes (2byte)—最大zpool大小
· 2—單個文件的屬性數量(受ZFS文件數量的約束,實際為2)
· 2—單個目錄的文件數(受ZFS文件數量的約束,實際為2)
· 2—單一zpool的設備數
· 2—系統的zpools數量
· 2—單一zpool的文件系統數量
作為對這些數字的感性認識,假設每秒鐘創建1,000個新文件,達到ZFS文件數極限需要大約9,000年。
在辯解填滿ZFS與煮沸海洋的關係時,Bonwick寫到:
儘管我們都希望摩爾定律永遠延續,但是量子力學給定了任何物理設備上計算速率(computation rate)與信息量的理論極限。舉例而言,一個質量為1公斤,體積為1升的物體,每秒至多在10位信息上進行10次運算。一個完全的128位存儲池將包含2個塊= 2位元組= 2位;應此,保存這些數據位至少需要(2位) / (10位/公斤) = 1360億公斤的物質。
ZFS使用一種寫時拷貝事務模型技術。所有文件系統中的塊指針都包括256位的能在讀時被重新校驗的關於目標塊的校驗和。含有活動數據的塊從來不被覆蓋;而是分配一個新塊,並把修改過的數據寫在新塊上。所有與該塊相關的元數據塊都被重新讀、分配和重寫。為了減少該過程的開銷,多次讀寫更新被歸納為一個事件組,並且在必要的時候使用日誌來同步寫操作。
利用寫時拷貝使ZFS的快照和事物功能的實現變得更簡單和自然,快照功能更靈活。缺點是,COW使碎片化問題更加嚴重,對於順序寫生成的大文件,如果以後隨機的對其中的一部分進行了更改,那麼這個文件在硬碟上的物理地址就變得不再連續,未來的順序讀會變得性能比較差。
ZFS使用寫時拷貝技術的一個優勢在於,寫新數據時,包含舊數據的塊被保留著,提供了一個可以被保留的文件系統的快照版本。由於ZFS在讀寫操作中已經存儲了所有構建快照的數據,所以快照的創建非常快。而且由於任何文件的修改都是在文件系統和它的快照之間共享的,所以ZFS的快照也是空間優化的。
可寫快照("克隆")也可以被創建。結果就是兩個獨立的文件系統共享一些列的塊。當任何一個克隆版本的文件系統被改變時,新的數據塊為了反映這些改變而創建,但是不管有多少克隆版本的存在,未改變的塊仍然在其他的克隆版本中共享
ZFS能動態條帶化所有設備以最大化吞吐量。當額外的設備被加入到zpool中的時候,條帶寬度會自動擴展以包含這些設備。這使得存儲池中的所有磁碟都被用到,同時負載被平攤到所有的磁碟上。
ZFS使用可變大小的塊,最大可至128KB。現有的代碼允許管理員調整最大塊大小,這在大塊效果不好的時候有用。未來也許能做到自動調整適合工作量的塊大小。
ZFS的可變大小的塊與BtrFS和Ext4的extent不同。在ZFS中,在一個文件中所有數據塊的邏輯長度必須是相同的,不同文件之間的塊大小可以不同,因此ZFS可以用直接映射(direct map)的方式(同ufs/ffs/ext2/ext3)來來搜索間接塊的數據指針數組(blkptr)。BtrFS和Ext4的extent方式在同一個文件中每個數據快的大小都可以不相同,因此需要用B+ Tree或者類B Tree的方式來組織間接塊的數據。
雖然直接映射方式比B+ Tree的查找速度快,但是這種方式的缺點也非常明顯,如:元數據開銷過大、順序IO的大文件性能不好、刪除比較慢等等,因此在現代文件系統中映射方式逐漸被extent變長塊取代。
如果數據壓縮(LZJB)被啟用,可變塊大小需要被用到。如果一個數據塊可被壓縮至一個更小的數據塊,則小的數據塊將使用更少的存儲和提高吞吐量(代價是增加CPU壓縮和解壓縮的負擔)。
· Sun Solaris
· OpenSolaris
· Illumos發行版
· OpenIndiana
· FreeBSD
· Mac OS X Server 10.5
· NetBSD
· Linux(通過用戶空間文件系統或原生第三方內核可載入核心模組支持)
不管層次如何,根總是池的名字。
⒈為每個用戶及項目創建一個文件系統是個不錯的辦法!
⒉ZFS可以為文件系統分組,屬於同一組的文件系統具有相似的性質,這有點像用戶組的概念!相似的文件系統能夠使用一個共同的名字。
⒊大多數文件系統的特性都被用簡單的方式進行控制,這些特徵控制了各種行為,包括文件系統被mount在哪裡,怎麼被共享,是否被壓縮,是否有限額
創建一個文件系統
| 1 | #zfscreatetank/home |
下一步,就可以創建各個文件系統,把它們都歸組到 home 這個文件系統中。
同時可以設置home的特性,讓組內的其他文件系統繼承的它的這些特性。
當一個文件系統層次創建之後,可以為這個文件系統設置一些特性,這些特性將被所有的用戶共享:
1 2 3 4 5 6 | #zfssetmountpoint=/export/zfstank/home #zfssetsharenfs=ontank/home #zfssetcompression=ontank/home #zfsgetcompressiontank/home NAMEPROPERTYVALUESOURCE tank/homecompressiononlocal |
⒋創建單個的文件系統
注意:這些文件系統如果被創建好,他們的特性的改變將被限制在home級別,所有的特性能夠在文件系統的使用過程中動態的改變。
1 2 | #zfscreatetank/home/bonwick #zfscreatetank/home/billm |
bonwick、billm文件系統從父文件系統home中繼承了特性,因此他們被自動的mount到/export/zfs/user 同時作為被共享的NFS。管理員根本不需要再手工去編輯 /etc/vfstab 或 /etc/dfs/dfstab 文件。
每個文件系統除了繼承特性外,還可以有自己的特性,如果用戶bonwick的磁碟空間要限制在10G。
| 1 | #zfssetquota=10Gtank/home/bonwick |
⒌用 zfs list 命令查看可獲得的文件系統的信息,類似於過去的 df -k 命令了,呵呵 .
1 2 3 4 5 6 | #zfslist NAMEUSEDAVAILREFERMOUNTPOINT tank92.0K67.0G9.5K/tank tank/home24.0K67.0G8K/export/zfs tank/home/billm8K67.0G8K/export/zfs/billm tank/home/bonwick8K10.0G8K/export/zfs/bonwick |
● ● 傳統的文件系統被限制在單個磁碟設備之內,它們的尺寸是不能超越單個磁碟設備。
● ● 傳統文件系統需要駐留於單獨設備或者需要一個卷管理系統去使用一個以上的設備,而ZFS建立在虛擬的,被稱為“zpools”的存儲池之上 (存儲池最早在AdvFS實現,並且加到後來的Btrfs)。
● ● 過去的文件系統是被影射到一個物理存儲單元,如:分區;所有的ZFS文件系統共享池內的可獲得的存儲空間。
● ● ZFS 文件系統不需要通過編輯/etc/vfstab 文件來維護。
ZFS已經拋棄了卷管理,邏輯卷可以不再使用。因為ZFS在使用和管理raw設備能夠有更好的表現。
Components of a ZFS Storage Pool
組成ZFS存儲池的元件有:磁碟、文件、虛擬設備,其中磁碟可以是整個硬碟(c1t0d0),也可以是單個slice(c0t0d0s7)。推薦使用整個硬碟,這樣可以省去分區操作(format)。
傳統的raid-5都存在著“寫漏洞”,就是說如果raid-5的stripe在正寫數據時,如果這時候電源中斷,那麼奇偶校驗數據將跟該部分數據不同步,因此前邊的寫無效;RAID-Z用了“variable-width RAID stripes”技術,因此所有的寫都是full-stripe writes。之所以能實現這種技術,就是因為ZFS集成了文件系統和設備管理,使得文件系統的元數據有足夠的信息來控制“variable-width RAID stripes”
理論上說,創建RAID-Z需要至少三塊磁碟,這跟raid-5差不多。例如:
raidz c1t0d0 c2t0d0 c3t0d0
還可以更加複雜一點,例如:
raidz c1t0d0 c2t0d0 c3t0d0 c4t0d0 c5t0d0 c6t0d0 c7t0d0 raidz c8t0d0 c9t0d0 c10t0d0 c11t0d0 c12t0d0 c13t0d0 c14t0d0
上邊這個例子創建了14個磁碟的RAID-Z , 這14個盤被分成了兩組,但下邊這句話有點不大明白:
RAID-Z configurations with single-digit groupings of disks should perform better.
(我的理解是:相對於大於10個硬碟組成的RAID-Z,少於10個(single-digit 即1位數)硬碟組成的RAID-Z的性能會更好) 奇數個硬碟(>3)組成的RAID-Z在理論上來說會表現的更好(實際測試中也是,同RAID-5)
(我認為原文說的意思是,RAID-Z的設置屬性是這些磁碟劃在一個組裡性能更好。//loong)
RAID-Z具有自動修複數據的功能
當有損壞的數據塊被檢測到,ZFS不但能從備份中找到相同的正確的數據,而且還能自動的用正確數據修復損壞的數據。
⒈創建一個基本的存儲池,方法很簡單:
| 1 | #zpoolcreatetankc1t0d0c1t1d0 |
這時可以在 /dev/dsk 目錄下看到一個大的slice,數據動態的stripe跨過所有磁碟!
⒉創建一個鏡像的存儲池
也是很簡單,只要在上邊命令基礎上增加“mirror”關鍵字就可以了,下邊是創建一個兩路(two-way)鏡像的例子:
| 1 | #zpoolcreatetankmirrorc1d0c2d0mirrorc3d0c4d0 |
⒊創建RAID-Z存儲池
使用“raidz”關鍵字就可以了,例如:
| 1 | #zpoolcreatetankraidzc1t0d0c2t0d0c3t0d0c4t0d0/dev/dsk/c5t0d0 |
這裡/dev/dsk/c5t0d0其實跟用c5t0d0是一樣的,由此可以看出,在創建ZFS的時候,磁碟完全可以用物理設備名就可以,不需要指出全路徑。
⒋檢測正在使用的設備
在格式化設備之前,ZFS首先決定磁碟是否已經在用或者是否裝有操作系統,如果磁碟在用了,那麼將會出現下邊的錯誤提示:
1 2 3 4 5 6 7 | #zpoolcreatetankc1t0d0c1t1d0 invalidvdevspecification use’-f’tooverridethefollowingerrors: /dev/dsk/c1t0d0s0iscurrentlymountedon dev/dsk/c1t0d0s1iscurrentlymountedonswap /dev/dsk/c1t1d0s0ispartofactiveZFSpool’zeepool’ Pleaseseezpool(1M) |
有些錯誤可以用 -f 選項來強制覆蓋,但是大多錯誤是不能的。下邊給出不能用-f覆蓋的錯誤情況,這時只能手工糾正錯誤:
1 2 3 4 | MountedfilesystemThediskoroneofitsslicescontainsafilesystemthatiscurrentlymounted.Tocorrectthiserror,usetheumountcommand. Filesystemin/etc/vfstabThediskcontainsafilesystemthatislistedinthe/etc/vfstabfile,butthefilesystemisnotcurrentlymounted.Tocorrectthiserror,removeorcommentoutthelineinthe/etc/vfstabfile. DedicateddumpdeviceThediskisinuseasthededicateddumpdeviceforthesystem.Tocorrectthiserror,usethedumpadmcommand. PartofaZFSpoolThediskorfileispartofanactiveZFSstoragepool.Tocorrectthiserror,usethezpoolcommandtodestroythepool. |
⒌創建存儲池時默認的mount點
To create a pool with a different default mount point,use the -m option of the zpool create command:
# zpool create home c1t0d0
default mountpoint ’/home’ exists and is not empty
use ’-m’ option to specifya different default
# zpool create -m /export/zfs home c1t0d0
This command creates a new pool home and the home dataset with a mount point of /export/zfs.
⒍刪除存儲池
Pools are destroyed by using the zpool destroy command. This command destroys the pool even if it contains mounted datasets.
# zpool destroy tank
⒈增加設備到存儲池
用戶可以通過增加一個新的頂級虛擬設備的方法動態給存儲池增加空間,這個空間立即對空間中的所有數據集(dataset)有效。要增加一個虛擬設備到池中,用“zpool add”命令,例如:
# zpool add zeepool mirror c2t1d0 c2t2d0
該命令也可以用 -n選項進行預覽,例如:
1 2 3 4 5 6 7 8 9 10 11 12 | #zpooladd-nzeepoolmirrorc3t1d0c3t2d0 wouldupdate’zeepool’tothefollowingconfiguration: zeepool mirror c1t0d0 c1t1d0 mirror c2t1d0 c2t2d0 mirror c3t1d0 c3t2d0 |
⒉增加和減少一路鏡像
用“zpool attach”命令增加一路鏡像,例如:
# zpool attach zeepool c1t1d0 c2t1d0
在這個例子中,假設 zeepool 是第一點裡的那個zeepool(已經是兩路鏡像),那麼這個命令將把zeepool升級成三路鏡像。
用“zpool detach”命令來分離一路鏡像
# zpool detach zeepool c2t1d0
如果池中不存在鏡像,這個才操作將被拒絕。錯誤提示如下邊這個例子:
# zpool detach newpool c1t2d0 cannot detach c1t2d0: onlyapplicable to mirror and replacing vdevs
⒊管理設備的“上線”和“下線”
ZFS允許個別的設備處於offline或者online狀態。當硬體不可靠或者還沒有完全不能用的時候,ZFS會繼續向設備讀寫數據,但不過是臨時這麼做,因為設備還能將就使用。一旦設備不能使用,就要指示ZFS忽略該設備,並讓這個壞掉的設備下線。ZFS不會向offline的設備發送任何請求。
注意:如 果只是為了更換設備(被換設備並沒有出問題),不 需要把他們offline。如果offline設備,然 后換了一個新設備上去,再 把新設備online,這 么做會出錯!
用“zpool offline”命令讓設備下線。例如:
# zpool offline tank c1t0d0
bringing device c1t0d0 offline
下邊這句話沒怎麼看懂:
You cannot take a pool offline to the point where it becomes faulted. For example,you cannot take offline two devices out of a RAID-Z configuration,nor can you take offline a top-level virtual device.
# zpool offline tank c1t0d0
cannot offline c1t0d0: no valid replicas
默認情況下,offline設備將永久保持offline狀態,直到系統重新啟動。
要臨時offline一個設備,用-t選項,例如:
# zpool offline -t tank c1t0d0
bringing device ’c1t0d0’ offline
用“zpool onine”命令使設備上線
# zpool online tank c1t0d0
bringing device c1t0d0 online
注意:如果只是為了更換設備(被換設備並沒有出問題),不需要把他們offline。如果offline設備,然後換了一個新設備上去,再把新設備online,這麼做會出錯!在這個問題上文檔是這麼說的:(但願我沒理解錯)
Note that you cannot use device onlining to replace a disk. If you offline a
device,replace the drive,and try to bring it online,it remains in the faulted state.
⒋清掃存儲池設備
如果設備因為出現錯誤,被offline了,可以用“zpool clear”命令清掃錯誤。
如果沒有特別指定,zpool clear命令清掃池裡所有設備。例如:
# zpool clear tank
如果要清掃指定設備,例如:
# zpool clear tank c1t0d0
⒌替換存儲池裡的設備
用“zpool replace”命令替換池中設備,例如:
# zpool replace tank c1t1d0 c1t2d0
c1t1d0 被 c1t2d0 替換
注意:如果是mirror或者RAID-Z,替換設備的容量必須大於或等於所有設備最小容量!
⒈ZFS存儲池的基本信息
用“zpool list”命令查看存儲池的基本信息,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 | #zpoollist NAMESIZEUSEDAVAILCAPHEALTHALTROOT tank80.0G22.3G47.7G28%ONLINE- dozer1.2T384G816G32%ONLINE- NAME:Thenameofthepool. SIZE:Thetotalsizeofthepool,equaltothesumofthesizeofalltop-levelvirtual devices. USED:Theamountofspaceallocatedbyalldatasetsandinternalmetadata.Notethat thisamountisdifferentfromtheamountofspaceasreportedatthefilesystemlevel. AVAILABLE:Theamountofunallocatedspaceinthepool. CAPACITY(CAP):Theamountofspaceused,expressedasapercentageoftotalspace. HEALTH:Thecurrenthealthstatusofthepool. ALTROOT:Thealternaterootofthepool,ifany. |
可以通過指定名字來查看某一個池的狀態,例如:
1 2 3 | #zpoollisttank NAMESIZEUSEDAVAILCAPHEALTHALTROOT tank80.0G22.3G47.7G28%ONLINE- |
如果要有選擇看狀態列表,可以用-o選項
1 2 3 4 5 | #zpoollist-oname,size NAMESIZE tank80.0G dozer1.2T ScriptingZFSStoragePoolOutput |
The default output for the zpool list command is designed for readability,and is not easy to use as art of a shell script. To aid programmatic uses of the command,the -H option can be used to uppress the column headings and separate fields by tabs,rather than by spaces. For example,to request a simple list of all pool names on the system:
1 2 3 4 5 6 7 | #zpoollist-Honame tank dozer Hereisanotherexample: #zpoollist-H-oname,size tank80.0G dozer1.2T |
⒉查看存儲池的I/O狀態
用“zpool iostat”命令查看存儲池的I/O狀態,例如:
1 2 3 4 5 6 | #zpooliostat capacityoperationsbandwidth poolusedavailreadwritereadwrite ---------------------------------------- tank100G20.0G1.2M102K1.2M3.45K dozer12.3G67.7G132K15.2K32.1K1.20K |
⒊ZFS存儲池的健康狀態
用“zpool status”查看健康狀態
ZFS是把存儲設備建立成為一個存儲池,在這個池中,還可以建立更小的池。每個同等級池之間的關係可以使各種raid關係;而子父級之間的關係,就和 存儲設備和存儲池之間 一樣。可以在下圖中清楚看到這種管理方式是如何存在的。
命令 zpool = zfs
1 $ fdisk -l
是無效的,要列出連接的硬碟,我選擇
1 $ format
命令,記錄下所有設備編號,如VMware下就是c5t0d0,c5t1d0,c5t2d0,….
查看zfs狀態的命令
1 $ zpool status
可以看到系統內所有存儲池狀態和硬碟健康度,可以在status後面加 -x 參數看所有存儲池是否健康 類似的可以查看存儲池總容量(包括冗餘)情況的命令
1 $ zpool list
用來搭配使用的
1 $ df -h poolname
檢查容量實際使用情況
zfs建立一個存儲池的命令是
1 $ zpool create poolname raidz1 c5t0d0 c5t1d0 c5t2d0
將會把c5t1~3d0 3個硬碟建立一個名字為poolname的raidz1模式(raid5)的存儲池。
刪除銷毀一個存儲池命令是
1 $ zpool destroy poolname
將zfs的存儲池掛載和卸載的命令,如同mount/unmount的是
1 $ zpool import/export poolname
這個一般是在恢復日誌歷史鏡像等應用時使用。也可以恢復被destroy的存儲池,使用
1 $ zpool import -D poolname
要看存儲池的實時讀寫狀態命令
1 $ zpool iostat 1
重中之重的replace命令,
1 $ zpool replace poolname c5t0d0 c6t0d0
就是將接入但沒使用的c6t0d0替換了正在使用的c5t0d0,這時使用zpool status應該會看到這兩個盤正在replacing,或者rebuild,這在替換報錯error/fault的硬碟,或者使用更大的容量替換老硬碟的時候都有用。 當一個raid內所有硬碟都替換為新的更大容量的硬碟后,可以使用
1 $ zpool set autoexpand=on poolname
開啟存儲池自動擴展的屬性(默認為禁止),或
1 $ zpool online -e poolname c6t0d0
對一個已經存在的設備使用online命令來達到擴容的目的,再次zpool list查看容量應該可以看到真箇raid容量已經擴大了。 其中online命令對應的是offline,zfs中常這樣使用
1 $ zpool offline poolname c6t0d0
當然zfs支持raid中的熱備份,可以在create的時候添加spare設備,例如
1 $ zpool create raidz1 poolname c5t0d0 c5t1d0 c5t2d0 spare c6t0d0
c6t0d0就成為了熱備份設備,要刪除這個熱備份設備(或日誌,高速緩存),就要使用命令
1 $ zpool remove c6t0d0
而對應的zpool add命令卻使用很有限,因為這個add只能在現有容量上擴充,也就是加入現有的存儲池形成raid0,這很有風險,比如poolname中有c5t1~3d0 3個硬碟形成的raidz1 容量為20G的存儲池,使用
1 $ zpool add -f poolname mirror c6t0d0 c6t1d0
這條命令的意義就是 先將c6t0d0 c6t1d0兩盤鏡像即raid1,例容量15G,再加入poolname中和已有的c5t1~3d0 raidz1的20G容量再raid0,銜接後面,之後存儲池poolname中的總容量就等於20G+15G =35G。如果一個盤壞了,c5t0d0壞了,就會對前面一個raidz1形成影響,變成degraded降級狀態,後面一個鏡像的c6t0d0 c6t1d0則沒有影響。如果後面的兩個不是鏡像,而是raid0模式,如果一個壞了offline,直接就導致這個raid0失敗不可訪問,間接的導致整個存儲池不可訪問,哪怕這個存儲池中有一部分的容量自身有備份。
所以add命令必須搭配 -f 參數,意思是強制添加容量到存儲池後面,加上zfs只能增加容量不能縮小的特性,為了保險起見,所有add加入的容量必須自身足夠安全(比如自身就是raid),否則一旦損壞會出現上面這樣的導致所有存儲不可訪問的問題。這個風險你應該在使用add命令的時候就非常清楚。zfs中不推薦使用raid0模式,除了萬不得已。
最好的最安全的擴容就是在raidz1或者raidz2(raid5/raid6)基礎上,用大容量設備replace舊的小容量設備,等重建替換完成後,挨個把存儲池內所有存儲設備升級替換,所有完成後使用前面的擴容命令自動擴容。
zfs文件系統除了方便擴容,方便管理,安全簡單以外,當然性能也同樣不能太低。而一些朋友常常爭論,究竟raid 0+1還是raidz1/raidz2更快,我覺得是沒有意義的,因為常常最終管理的存儲的容量和速度是成反比的,只要安全,訪問速度快慢就交給緩存來解決。zfs在更新數個版本后,緩存管理已經非常優秀了,基本上在只有內存做緩存的系統上,除去基本的4G RAM系統最低要求,每增加10G常用數據,就要增加1G RAM來保證命中和速度,比如後面是100G的常用數據,那麼就需要100/10+4G=14G內存來保證較高的讀取速度。內存價格偏高,且不容易擴展的時候,就出現了使用SSD固態硬碟來做緩存的技術,形成了CPU->RAM->SSD cache->HDD ZFS的三層結構。在FreeNAS中這點做得很好,設置很方便,有文章指出,4G系統內存下,網路訪問速度約為400Mbit/sec read + 300Mbit/sec write,而8G內存+64G SSD的緩存結構下,可以達到900Mbit/sec read + 600Mbit/sec write,跑滿千兆網路,同時iSCSI性能飛升,生產環境中也應該這樣搭建使用。命令也很簡單,只需要在create的時候增加cache SSD0,也可以單獨使用命令
1 $ zpool add poolname cache SSD0 SSD1
來增加一個或多個緩存,此緩存設備可以通過前面提到的remove命令輕鬆刪除。
到這裡已經差不多了,對於存儲池內數據的完整性,通過命令
1 $ zpool scrub poolname
達到校驗的目的,這一般會花費很長的時間,可以通過zpool status查看校驗進度,最好在硬體出現問題,解決后都校驗一次以保證一切正常。
觀察近兩年的發展,FreeBSD的活躍度已經漸漸趕上Linux的開發速度了,相互之間的借鑒也越來越多,而在此之上的solaris也被廣泛使用,作為數據伺服器的首選。
1)ZPOOL,一個動態可擴展的存儲池
其對外提供一個虛擬的設備,可以動態的添加磁碟,移除壞盤,做mirror, raid0, raidz 等。 基於這個動態調節的ZFS Pool之上的新的邏輯硬碟可以被文件系統使用,並且會自動的選擇最優化的參數。
這個有點像SAN ,SAN 對外提供的也是一個虛擬磁碟,該磁碟時可以跨網路的, ZFS是本地文件系統,只能實現本地磁碟。
2)Copy-on-write 技術。 這個技術並不複雜,也不難理解。但是這個技術是有嚴重的performance的問題的。
Copy-on-Write 技術是可以認為是另一個journal 的實現,和日誌不同的是,它不是re-do 日誌,而是直接修改文件的block的指針。它對於文件本身的數據的完整性是沒有問題的,當寫一個新的block 時,沒有performance的影響,當些一個舊的block時,需要先copy一份,性能可想要大跌。對於元數據,性能損失就更加明顯了。
總之,通過這個技術,和Transaction技術一起,確實可以對數據的一致性得到比較好的保護,但是性能的損失如何去彌補,這是一個問題。
3)智能預讀取(Intelligent Prefetch)
prefetch 技術是順序讀的一個性能優化的很好的技術。 ZFS實現了更智能的預定模式。
目 前預取技術就是對順序讀比較有效。對於其它類型的訪問模式,一是模式檢測比較難,其次即使檢測出來,由於性能的 bottleneck 可能在別的地方,性能優化並不理想。 ZFS的預取技術,增加了Strip模式的預取,這在ZFS模式下是有效的,其它的模式並沒有看到。其次目 前都是針對單流預取,針對多流很少。
4)Dynamic Striping
所謂的動態striping,就是可以再不同設備上分配 block,不同設備上當然是併發的寫入, 可以認為是一種strip操作。 和 static striping 不同,是需要事前設置。 這個是ZFS的動態存儲池本身的架構帶來的優勢。
5)增加了數據的Checksum校驗
這個技術是小技巧,沒啥可評價的,看下面的介紹。 由於ZFS所有的數據操作都是基於Transaction(事務),一組相應的操作會被ZFS解析為一個事務操作,事務的操作就代表著一組操作要麼一起失敗,要麼一起成功。而且如前所說,ZFS對 所有的操作是基於COW(Copy on Write), 從而保證設備上的數據始終都是有效的,再也不會因為系統崩潰或者意外掉電導致數據文件的inconsistent。 還有一種潛在威脅數據的可能是來自於硬體設備的問題,比如磁碟,RAID卡的硬體問題或者驅動bug。現有文件系統通常遇到這個問題,往往只是簡單的把錯誤數據直接交給上層應用,通常我們把這個問題稱作 Silent Data Corruption。而在ZFS中,對所有數據不管是用戶數據還是文件系統自身的metadata數據都進行256位的Checksum(校驗),當ZFS在提交數據時會進行校驗,徹底杜絕這種Silent Data Corruption情況。
值得注意的是,ZFS通過COW技術和Chumsum技術有效的保護了數據的完整性。
6)Extent的概念:支持多種 大小的數據塊(Multiple Block Size)
目前最新的思想,都是丟棄block的概念,引入Extent的概念,Extent就是連續的多個block,注意Extent的block是變長的。多種Block Size 對大文件和 小文件都可以有很好的優化。這個只是剩如何實現了。
7)自我修復功能 ZFS Mirror 和 RAID-Z 傳統的硬碟Mirror及RAID 4,RAID 5陣列方式都會遇到前面提到過的問題:Silent Data Corruption。如果發生了某塊硬碟物理問題導致數據錯誤,現有的Mirror,包括RAID 4,RAID 5陣列會默默地把這個錯誤數據提交給上層應用。如果這個錯誤發生在Metadata中,則會直接導致系統的Panic。而且還有一種更為嚴重的情況是:在 RAID 4和RAID 5陣列中,如果系統正在計算Parity數值,並再次寫入新數據和新Parity值的時候發生斷電,那麼整個陣列的所有存儲的數據都毫無意義了。 在ZFS中則提出了相對應的ZFS Mirror和RAID-Z方式,它在負責讀取數據的時候會自動和256位校驗碼進行校驗,會主動發現這種Silent Data Corruption,然後通過相應的Mirror硬碟或者通過RAID-Z陣列中其他硬碟得到正確的數據返回給上層應用,並且同時自動修復原硬碟的 Data Corruption 。
對於本地文件系統系統,支持Quota,Reservation,Compression 並不難,對於用COW技術,Snapshot,Clone幾乎是COW的附帶的產品,實現都很容易。
9)ZFS的容量無限制。
他是如何做到的呢?一個就是ZPOOL, 這使得容量可以動態擴展,其次,元數據也是動態分配的,也就是inode也是動態分配的。 對於本地文件系統,我們說的擴展性,這的是容量線性擴展, performance的線性擴展,包括IOPS 和 Bandwidth , 對於ZFS,聲稱可以實現線性擴展。
● OpenSolaris
● Illumos發行版
● OpenIndiana
● FreeBSD
● Mac OS X Server 10.5
● NetBSD
● Linux
ZFS的設計與開發由Sun公司的Jeff Bonwick所領導的一支團隊完成。最早宣佈於2004年9月14日,於2005年10月31日併入了Solaris開發的主幹源代碼。並在2005年11月16日作為OpenSolaris build 27的一部分發布。Sun在OpenSolaris社區開張1年後的2006年六月,將ZFS集成進了Solaris 10 6/06版本更新。
ZFS的命名來源發想於"ZettabyteFile System"的首字母縮寫。但 ZFS 本身並不具備任何的縮寫意涵,只是作者想闡述做為一個具備高擴充容量文件系統且還有支持許多延伸功能的一個產品。
⒈ZFS存儲池的基本信息
用“zpool list”命令查看存儲池的基本信息,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 | #zpoollist NAMESIZEUSEDAVAILCAPHEALTHALTROOT tank80.0G22.3G47.7G28%ONLINE- dozer1.2T384G816G32%ONLINE- NAME:Thenameofthepool. SIZE:Thetotalsizeofthepool,equaltothesumofthesizeofalltop-levelvirtual devices. USED:Theamountofspaceallocatedbyalldatasetsandinternalmetadata.Notethat thisamountisdifferentfromtheamountofspaceasreportedatthefilesystemlevel. AVAILABLE:Theamountofunallocatedspaceinthepool. CAPACITY(CAP):Theamountofspaceused,expressedasapercentageoftotalspace. HEALTH:Thecurrenthealthstatusofthepool. ALTROOT:Thealternaterootofthepool,ifany. |
可以通過指定名字來查看某一個池的狀態,例如:
1 2 3 | #zpoollisttank NAMESIZEUSEDAVAILCAPHEALTHALTROOT tank80.0G22.3G47.7G28%ONLINE- |
如果要有選擇看狀態列表,可以用-o選項
1 2 3 4 5 | #zpoollist-oname,size NAMESIZE tank80.0G dozer1.2T ScriptingZFSStoragePoolOutput |
The default output for the zpool list command is designed for readability,and is not easy to use as art of a shell script. To aid programmatic uses of the command,the -H option can be used to uppress the column headings and separate fields by tabs,rather than by spaces. For example,to request a simple list of all pool names on the system:
1 2 3 4 5 6 7 | #zpoollist-Honame tank dozer Hereisanotherexample: #zpoollist-H-oname,size tank80.0G dozer1.2T |
⒉查看存儲池的I/O狀態
用“zpool iostat”命令查看存儲池的I/O狀態,例如:
1 2 3 4 5 6 | #zpooliostat capacityoperationsbandwidth poolusedavailreadwritereadwrite ---------------------------------------- tank100G20.0G1.2M102K1.2M3.45K dozer12.3G67.7G132K15.2K32.1K1.20K |
⒊ZFS存儲池的健康狀態
用“zpool status”查看健康狀態

基本信息
- 別名
- 動態文件系統
- 發布時間
- 2005年11月
- 開放公司
- Sun