共找到2條詞條名為高性能計算的結果 展開
- 高性能計算
- 事物
高性能計算
高性能計算
高性能計算(HPC)是一個計算機集群系統,它通過各種互聯技術將多個計算機系統連接在一起,利用所有被連接系統的綜合計算能力來處理大型計算問題,所以又通常被稱為高性能計算集群。
高性能計算(HPC) 指通常使用很多處理器(作為單個機器的一部分)或者某一集群中組織的幾台計算機(作為單個計圖1.HPC 匯流排網路拓撲算資源操作)的計算系統和環境。有許多類型的HPC 系統,其範圍從標準計算機的大型集群,到高度專用的硬體。
大多數基於集群的HPC系統使用高性能網路互連,比如那些來自 InfiniBand 或 Myrinet 的網路互連。基本的網路拓撲和組織可以使用一個簡單的匯流排拓撲,在性能很高的環境中,網狀網路系統在主機之間提供較短的潛伏期,所以可改善總體網路性能和傳輸速率。
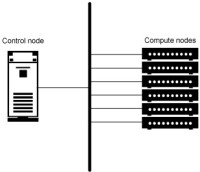
圖1.HPC 匯流排網路拓撲
圖2顯示了一網狀 HPC 系統。在網狀網路拓撲中,該結構支持通過縮短網路節點之間的物理和邏輯距離來加快跨主機的通信。圖2.HPC 網狀網路拓撲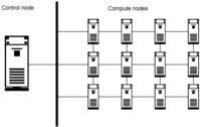
圖1.HPC 網狀網路拓撲
儘管網路拓撲、硬體和處理硬體在 HPC 系統中很重要,但是使系統如此有效的核心功能是由操作系統和應用軟體提供的。
HPC 系統使用的是專門的操作系統,這些操作系統被設計為看起來像是單個計算資源。正如從圖1和圖2中可以看到的,其中有一個控制節點,該節點形成了 HPC 系統和客戶機之間的介面。該控制節點還管理著計算節點的工作分配。
對於典型 HPC 環境中的任務執行,有兩個模型:單指令/多數據 (SIMD) 和多指令/多數據 (MIMD)。SIMD在跨多個處理器的同時執 行相同的計算指令和操作,但對於不同數據範圍,它允許系統同時使用許多變數計算相同的表達式。MIMD允許HPC 系統在同一時間 使用不同的變數執行不同的計算,使整個系統看起來並不只是一個沒有任何特點的計算資源(儘管它功能強大),可以同時執行許多計算。
不管是使用 SIMD 還是 MIMD,典型 HPC 的基本原理仍然是相同的:整個HPC 單元的操作和行為像是單個計算資源,它將實際請求的載入展開到各個節點。HPC 解決方案也是專用的單元,被專門設計和部署為能夠充當(並且只充當)大型計算資源。
網格對於高性能計算系統而言是相對較新的新增內容,它有自己的歷史,並在不同的環境中有它自己的應用。網格計算系統的關鍵
元素是網格中的各個節點,它們不是專門的專用組件。在網格中,各種系統常常基於標準機器或操作系統,而不是基於大多數并行
計算解決方案中使用的嚴格受控制的環境。位於這種標準環境頂部的是應用軟體,它們支持網格功能。
網格可能由一系列同樣的專用硬體、多種具有相同基礎架構的機器或者由多個平台和環境組成的完全異構的環境組成。專用計算資
源在網格中並不是必需的。許多網格是通過重用現有基礎設施組件產生新的統一計算資源來創建的。
不需要任何特別的要求就可以擴展網格,使進一步地使用節點變得比在典型HPC環境中還要輕鬆。有了HPC解決方案,就可以設計和
部署基於固定節點數的系統。擴展該結構需要小心規劃。而擴展網格則不用考慮那麼多,節點數會根據您的需要或根據可用資源動
態地增加和減少。圖3.網格網路架構
儘管有了拓撲和硬體,網格就可以以圖1和圖2中所示結構的相同結構為基礎,但使用標準網路連接組件支持網格也是有可能的。甚
至可以交叉常規網路邊界,在WAN或網際網路上合併計算資源,如圖3所示。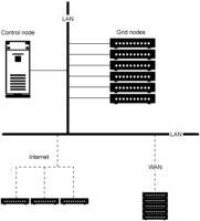
網格網路架構
作為執行模型和環境,網格還被設計成在操作和執行方面更具靈活性。儘管可以使用網格解決諸如HPC解決方案之類的計算任務,但網格可能更靈活,可以使用各種節點執行不同的計算、表達式和操作。網格並不只是一種沒有任何特點的計算資源,可將它分佈到各種節點中使用,並且一直運行到作業和操作都已完成。這使得網格在不同計算和組件的執行順序對於剩餘任務的連續執行不那麼重要的地方變得更加實用。
利用這種可變長度靈活性和較孤立任務的網格解決方案的一個好例子是計算機合成電影和特技效果中的表演。在這裡,生成的順序並不重要。單幀或更大的多秒的片段可以彼此單獨呈現。儘管最終目標是讓電影以正確的順序播放,但最後五分鐘是否在最初的五分鐘之前完成是無關緊要的;稍後可以用正確的順序將它們銜接在一起。
網格與傳統HPC解決方案之間的其他主要不同是:HPC解決方案設計用於提供特定資源解決方案,比如強大的計算能力以及在內存中保存大量數據以便處理它們的能力。另一方面,網格是一種分散式計算資源,這意味著網格可以根據需要共享任何組件,包括內存、CPU電源,甚至是磁碟空間。
因為這兩個系統之間存在這些不同,因此開發出了簡化該過程的不同編程模型和開發模型。
HPC解決方案的專用特性在開發應用程序以使用這種能力時提供了一些好處。大多數HPC系統將自己表現為單個計算資源,因此它成為一種編程責任,需要通過專用庫來構建一個能夠分佈到整個資源中的應用程序。
HPC環境中的應用程序開發通常是通過專用庫來處理,這極大簡化了創建應用程序的過程以及將該應用程序的任務分配到整個HPC系統中的過程。
最流行的解決方案之一是消息傳遞介面(MPI)。MPI提供了一個創建工作的簡化方法,使用消息傳遞在各個節點之間交換工作請求。作為開發過程的一部分,可能知道想要使用的處理器(在這裡指單獨節點,而非單獨CPU)的數量。HPC環境中的勞動分工取決於應用程序,並且很顯然還取決於HPC環境的規模。如果將進行的工作分配依賴於多個步驟和計算,那麼HPC環境的并行和順序特性將在網格的速度和靈活性方面起到重要作用。
圖4.HPC功能圖一旦分配好工作,就可以給每個節點發送一條消息,讓它們執行自己的那部分工作。工作被放入HPC單元中同時發給每個節點,通常會期望每個節點同時給出結果作為響應。來自每個節點的結果通過MPI提供的另一條消息返回給主機應用程序,然後由該應用程序接收所有消息,這樣工作就完成了。圖4中顯示了這種結構的一個示例。
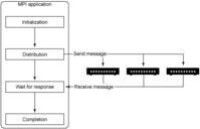
圖4.HPC功能圖
其他HPC庫和介面的工作方式類似,具體的方式取決於開發用於HPC環境中的應用程序。無論什麼時候,都可以將工作分配和執行看作一個單獨的過程。儘管應用程序的執行可能要排隊等候,但一旦應用程序開始運行,將立即在HPC系統的所有節點上執行該工作的各個組件。
為了處理多個同時發生的應用程序,多數HPC系統使用了一個不同應用程序在其中可以使用不同處理器/節點設置的系統。例如256個節點的HPC系統可以同時執行兩個應用程序,如果每個應用程序都使用整個計算資源的一個子集的話。
網格的分散式(常常是非專用的)結構需要為工作的執行準備一個不同的模型。因為網格的這種特性,無法期望同時執行各種工作單元。有許多因素影響了工作的執行時間,其中包括工作分配時間以及每個網格節點的資源的有效功率。
因為各個節點中存在的不同之處和工作被處理的方式,網格使用了一個將網格節點的監視與工作單元的排隊系統相結合的系統。該監視支持網格管理器確定各個節點上的當前負載。然後在分配工作時使用該信息,把要分配的工作單元分配給沒有(或有少量)當前資源負載的節點。
圖5.網格功能圖所以,整個網格系統基於一系列的隊列和分佈,通過在節點之間共享負載,在節點變得可用時將工作分配給隊列中的每個節點,使網格作為一個整體得到更有效的使用。
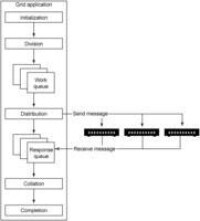
圖5.網格功能圖
網格模型允許使用各種級別的資源、工作單元規模和分配級別,而不只是HPC解決方案使用的執行模型提供的那些。大多數網格支持使用每個將被排隊和分配的應用程序的各種工作單元同時執行多個工作請求。例如,可以在一些節點仍然在完成Job1上的工作時開始Job2上的工作,為了完成工作,兩項作業以某種動態的方式使用相同數量的可用節點。
此過程的靈活特性不但允許以更動態更適應的方式執行工作,還允許網格與各種硬體和平台一起使用。即使網格中的某些節點比其他一些節點更快或更慢一些,也不再有任何關係;它們可以在自己(比較)空閑的時間完成工作,並且結果將被排隊。其間,更快的系統可能被分配更多的工作並完成更多的工作單元。
出現這種不利現象是因為需要更繁重的管理費用來觀察和監視各個節點,以便能夠在節點間有效分配工作。在異構環境中,還必須
考慮不同的平台,並開發跨支持環境兼容的應用程序。但在網格空間中,Web服務已簡化了該過程,使分配工作變得更容易,不必擔心這些不同。
在查看Web服務的效果之前,查看HPC和網格之間的會合區域,並了解這將如何影響不同的執行模型。
HPC 和網格環境之間存在一些類似之處,在許多方面,這二者都出現了一些會合和分歧,不同的團體利用了這兩個系統的各自優點。許多網格環境已從HPC解決方案的擴展中產生,基於HPC環境中的工作,網格中使用的許多技術得到了優化和採用。
一些顯而易見的類似之處是工作被分配到更小的單元和組件中的方式,以及各個工作節點之間的工作分配方式。在HPC環境中,這種 勞動分配通常受到嚴格控制,並且是根據您的可用資源進行的。網格使用了一種更靈活的模型,該模型允許將工作分配給大小不標準的單元,因此可以在截然不同的網格節點數組之間分配工作。
儘管工作的分配方式上存在不同,但分配的基本原則仍然是相同的:先確定工作及其分配方式,然後相應地創建工作單元。例如,如果遇到計算問題,可以通過創建不同的參數集,利用將應用於每個節點的每個集合的變數來分配工作。
HPC 系統中使用的消息傳遞結構和系統也已開發並適用於網格系統。許多 HPC 消息傳遞庫使用共享內存結構來支持節點之間的工作單元分配。
在網格中,共享的內存環境是不存在的。此外,工作是利用標準網路連接(通常使用TCP/IP)上發送的不同消息來分配的。系統的核心沒有什麼不同:交換包含工作參數的消息。只有交換信息的物理方法是不同的。
儘管平台獨立 HPC 系統非常常見(比如 MPI,它支持多個平台和架構),但 HPC 解決方案並不能直接使用,並且許多使用仍然依賴於架構的統一。
典型網格的不同特性導致工作分配方式發生了變化。因為網格節點可能基於不同平台和架構,所以在不同公用和私用網路上,需要某種以平台為核心的交換工作和請求的方法,該方法使分配工作變得更容易,不必擔心目標環境。
Web 服務基於開放標準,使用XML來分配和交換信息。該效果實質上將消除在平台和架構間共享信息的複雜性。可以編寫一系列支持不同操作的Web服務,而不是編寫跨網格執行的二進位應用程序,這些 Web 服務是為各種節點和平台量身訂做的。部署Web服務的費用也比較低,這使得它們對於不使用專用計算節點的網格中的操作比較理想。
通過消除兼容性問題並簡化信息分配方法,Web服務使網格的擴展變得更輕鬆。使用HPC解決方案,通常必須使用基於相同硬體的節點來擴展HPC環境的功能。而使用網格,特別是在使用Web服務時,系統幾乎可以在任何平台上擴展。
網格和Web服務的其他問題是由於不再應用關閉的HPC系統和內部HPC系統而導致的常見分配和安全考慮事項。在WAN或公用網路上使用網路節點時尤為如此。對於HPC 解決方案,系統的安全可通過硬體的統一特性得到控制;對於某一位置上的所有機器,安全性更容易控制。
為了提高Web服務的互操作性,特別是在網格環境中,OASIS 團隊開發了許多Web服務標準。這些標準都是通過其WS前綴來標識的。通用規範包含一些頂級 Web服務支持和全面保護規範,用於發現Web服務和選項以及信息交換(通過WS-Security)。
更深一層的標準提供了用來共享資源和信息的標準化方法(WS-Resource 和 WS-Resource Framework)、用來可靠地交換消息的標準化方法(WS-Reliable Messaging)、用於事件通知的標準化方法(WS-Notification),甚至是用於 Web 服務管理的標準化方法(WS-Distributed Management)。
出於安全考慮,可以 WS-Reliable Messaging 交換與WS-Security 標準包裝在一起,這定義了用於身份驗證、授權和消息交換加密的方法和過程。
通過將Web服務標準支持、安全規範和您自己的定製Web 服務組件結合在一起,可以構建一個使用多個平台和環境的高效網格。然後可以在LAN環境中使用應用程序,或者安全地通過公用網路提供與典型HPC解決方案同樣強大的計算資源,但具有擴展的靈活性和對網格技術的標準支持。
網格計算從技術上說是一種高性能計算機,但它在許多方面不同於傳統的HPC 環境。大多數傳統HPC技術都是基於固定的和專用的硬體,並結合了一些專門的操作系統和環境來產生高性能的環境。相比較而言,網格可以使用日用硬體、不同平台,甚至被配置成可以使用現有基礎設施中的多餘容量。
儘管存在一些不同,但兩個系統也有許多相似之處,特別是查看跨節點的工作分工和分配時。在兩種情況下,都可以使用Web服務來幫助支持系統操作。通過使用開放標準並允許支持更廣範圍的操作系統和環境,Web 服務和網格技術可能在高性能計算解決方案的功效和靈活性方面帶來很大的不同。
高性能計算(HighPerformanceComputing)是計算機科學的一個分支,主要是指從體系結構、并行演演算法和軟體開發等方面研究開發高性能計算機的技術。
隨著計算機技術的飛速發展,高性能計算機的計算速度不斷提高,其標準也處在不斷變化之中。
曙光CAE高性能計算平台高性能計算簡單來說就是在16台甚至更多的伺服器上完成某些類型的技術工作負載。到底這個數量是需要8 台,12台還是16台伺服器這並不重要。在定義下假設每一台伺服器都在運行自己獨立的操作系統,與其關聯的輸入/輸出基礎構造都是建立在COTS系統之上。
Linux高性能計算集群模型
一個擁有20000台伺服器的信息中心要進行分子動力學模擬無疑是毫無問題的,就好比一個小型工程公司在它的機房裡運行計算流體動力學(CFD)模擬。解決工作負載的唯一限制來自於技術層面。接下來我們要討論的問題是什麼能直接加以應用。
性能(Performance),每瓦特性能(Performance/Watt),每平方英尺性能(Performance/Squarefoot)和性能價格比
(Performance/dollar)等,對於提及的20000台伺服器的動力分子簇來說,原因是顯而易見的。運行這樣的系統經常被伺服器的能量 消耗(瓦特)和體積(平方英尺)所局限。這兩個要素都被計入總體擁有成本(TCO)之列。在總體擁有成本(TCO)方面取得更大的經濟效益是大家非常關注的。
議題的範圍限定在性能方面來幫助大家理解性能能耗,性能密度和總體擁有成本(TCO)在實踐中的重要性。
在這裡把性能定義為一種計算率。例如每天完成的工作負載,每秒鐘浮點運算的速度(FLOPs)等等。接下來要思考的是既定工作量的完成時間。這兩者是直接關聯的,速度=1/(時間/工作量)。因此性能是根據運行的工作量來進行測算的,通過計算其完成時間來轉化成所需要的速度。
從定性的層面上來說這個問題很容易回答,就是更快的處理器,更多容量的內存,表現更佳的網路和磁碟輸入/輸齣子系統。但當要
在決定是否購買Linu集群時這樣的回答就不夠準確了。
對Linux高性能計算集群的性能進行量化分析。
為此介紹部分量化模型和方法技巧,它們能非常精確的對大家的業務決策進行指導,同時又非常簡單實用。舉例來說,這些業務決策涉及的方面包括:
購買---系統元件選購指南來獲取最佳性能或者最經濟的性能Linux高性能計算集群模型
配置---鑒別系統及應用軟體中的瓶頸
計劃---突出性能的關聯性和局限性來制定中期商業計劃
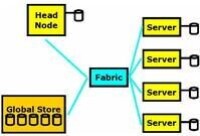
Linux高性能計算集群模型
(1)執行技術工作負載的計算節點或者伺服器;
(2)一個用於集群管理,工作控制等方面的主節點;
(3)互相連接的電纜和現在高度普及的千兆乙太網(GBE);
(4)一些全球存儲系統,像由主節點輸出的NFS文件一樣簡單易用。
高性能計算機的衡量標準主要以計算速度(尤其是浮點運算速度)作為標準。高性能計算機是信息領域的前沿高技術,在保障國家安全、推動國防科技進步、促進尖端武器發展方面具有直接推動作用,是衡量一個國家綜合實力的重要標誌之一。
隨著信息化社會的飛速發展,人類對信息處理能力的要求越來越高,不僅石油勘探、氣象預報、航天國防、科學研究等需求高性能計算機,而金融、政府信息化、教育、企業、網路遊戲等更廣泛的領域對高性能計算的需求迅猛增長。
這樣一個量化的運用模型非常直觀。在一個集群上對既定的工作完成的時間大約等同於在獨立的子系統上花費的時間:
e
1、時間(Time)=節點時間(Tnode)+電纜時間(Tfabric)+存儲時間(Tstorage)
Time = Tnode + Tfabric + Tstorag
這裡所說的時間(Time)指的是執行工作量的完成時間,節點時間(Tnode)是指在計算節點上花費的完成時間,電纜時間(Tfabric)是指在網際網路上各個節點進行互聯的完成時間,而存儲時間(Tstorage)則是指訪問區域網或全球存儲系統的完成時間。
計算節點的完成時間大約等同於在獨立的子系統上花費的時間:
2、節點時間(Tnode)=內核時間(Tcore) +內存時間(Tmemory)
這裡所說的內核時間(Tcore)指的是在微處理器計算節點上的完成時間。而內存時間(Tmemory)就是指訪問主存儲器的完成時間。這個模型對於單個的CPU計算節點來說是非常實用的,而且能很容易的擴展到通用雙插槽(SMP對稱多處理)計算節點。為了使第二套模型更加實用,子系統的完成時間也必須和計算節點的物理配置參數相關聯,例如處理器的速度,內存的速度等等。
圖示中的計算節點原型來認識相關的配置參數。圖示上端的是2個處理器插槽,通過前端匯流排(FSB-front side bus)與內存控制中心(MCH)相連。這個內存控制中心(MCH)有四個存儲通道。同時還有一個Infiniband HCA通過通道點對點串列(PCIe)連接在一起。性能參數像千兆乙太網和串列介面(SATA)硬碟之類的低速的輸入輸出系統都是通過晶元組中的南橋通道(South Bridge)相連接的。在圖示中,大家可以看到每個主要部件旁邊都用紅色標註了一個性能相關參數。這些參數詳細的說明了影響性能(並非全部)的硬體的特性。它們通常也和硬體的成本直接相關。舉例來說,處理器時鐘頻率(fcore)在多數工作負荷狀態下對性能影響巨大。根據供求交叉半導體產額曲線原理,處理器速度越快,相應成本也會更高。
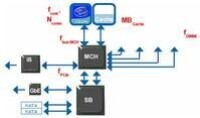
性能參數
而其他一些因素,比如雙列直插內存模塊內存延遲(DIMM CAS Latency),存儲通道的數量等都做為次要因素暫時忽略不計。
在圖示中標明的6個性能參數中,保留四個和模型相關的參數。
首先忽略通道點對點串列的頻率(fPCIe),因為它主要影響的是電纜相互連接(interconnect fabric)速度的性能,這不在範圍之列。
接下來注意一下雙列直插內存模塊頻率(fDIMM)和匯流排頻率(fBus)會由於內存控制中心(MCH)而限於固定比率。
使用的雙核系統中,這些比率最具代表性的是4:5, 1:1, 5:4。一般情況下只會用到其中的一個。高速緩存存儲器的體積非常重要。
在這個模型中保留這個參數。內核的數量(Ncores)和內核頻率(fcore)也非常重要,保留這兩個參數。
這第二個模型的基本形式在計算機體系研究領域已經存在了很多年。
A普通模式是:
(3) CPI = CPI0 + MPI * PPM
這裡的CPI指的是處理器在工作負荷狀態下每執行一個指令的周期。CPI0是指內核CPI,MPI I則是指在工作負荷狀態下高速緩存存儲器每個指令失誤的次數(註釋:在高性能計算領域,MPI主要用於信息傳遞界面,在此處主要是指處理器構造慣例),PPM是指以處理器時鐘滴答聲為單位對高速緩存存儲器每個指令失誤的次數的記錄。第二和第三個方程式相互吻合。這第一個術語代表的是處理器,第二個術語代表的是內存。
可以直觀的看到,假設每項工作下執行的P指令的工作負荷與代表處理器的頻率的內核頻率(每秒鐘處理器運行周期的單位)再與方程式(3)相乘,就得到了方程式(4):
Tnode = (CPIo * P) * (1 / fcore) + (MPI * P) * PPM * (1 / fcore)
在這裡要注意(CPIo * P)是以每項工作分配下處理器的運行周期為單位,對微處理器架構上運行的既定工作負荷通常是個恆量。因 此把它命名為α。(處理器周期本身無法對時間進行測算,如果乘以內核的頻率就可以得到時間的測算標準。因此Tnode在方程式(4) 的右邊)。
(MPI * P)也是同理。對於既定工作負荷和體系結構來說它也是個恆量,但它主要依賴於高速緩存存儲器的體積。我們把它命名為M (MBcache)。而PPM是指訪問主存的成本。對於既定的工作負荷來說,通常是個固定的數字C。PPM乘以內存頻率和匯流排頻率的比值(fcore / fBus)就從匯流排周期(bus cycles)轉化成了處理器周期。因此PM = C * fcore / fBus。套入M(MBcache)就可以得到:
(5) Tnode = α * (1 / fcore) + M(MBcache) * (1 / fbus)
這個例子說明匯流排頻率(bus frequency)也是個恆量,方程式(5)可以簡化為方程式(6):
(6) Tnode = α * (1 / fcore) + β
在這裡Tcore = α * (1 / fcore),而Tmemory = β(也就是公式2里的術語。我們把這些關鍵點關聯在一起)。
首先在模型2里,公式5和公式6都有堅實的理論基礎,因為經分析過它是如何從公式3推理而來(它主要應用於計算機體系理論)。其次,這個模型4個硬體性能參數的3個已經包括其中。還差一個參數就是內核數量(Ncores)。
用直觀的方式來說明內核的數量,就是假設把N個內核看做是一個網路頻率上運行的一個內核,稱之為N*fcore。那麼根據公式(6)我們大致可以推算出:
(7) Tcore ~ α / (N*fcore)
Tcore~ ( α / N) * (1 / fcore )
也可以把它寫成:
(8) αN = ( α / N)
多核處理器的第一個字母Alpha可能是單核處理器的1/N次。
通過數學推算這幾乎是完全可能的。
通常情況下我們是根據系統內核和匯流排頻率(bus frequencies)來衡量計算機系統性能,如公式(5)所闡述的。但是公式(5)的左邊是 時間單位--這個時間單位指的是一項工作量的完成時間。這樣就能更清楚的以時間為單位說明右側的主系統參數。同時請注意內核的時鐘周期τcore(是指每次內核運行周期所需的時間)也等同於(1 / fcore)。匯流排時鐘(bus clock)周期也是同理。
(9) Tnode = αN * τcore + M(MBcache) * τBus
這個公式的轉化也給了一個完成時間的模型,那就是2個基本的自變數τcore和τBus呈現出直線性變化。這對使用一個簡單的棋盤
式對照表對真實系統數據進行分析是有幫助的。
大家已逐漸認同這一觀點,高性能計算機是價格在10萬元以上的伺服器。之所以稱為高性能計算機,主要是它跟微機與低檔PC伺服器相比而言具有性能、功能方面的優勢。高性能計算機也有高、中、低檔之分,中檔系統市場發展最快。從應用與市場角度來劃分,中高檔系統可分為兩種,曙光2000一種叫超級計算機,主要是用於科學工程計算及專門的設計,如Cray T3E;另一種叫超級伺服器,可以用來支持計算、事務處理、資料庫應用、網路應用與服務,如IBM的SP和國產的曙光2000。

曙光2000
高性能計算機的發展趨勢主要表現在網路化、體系結構主流化、開放和標準化、應用的多樣化等方面。網路化的趨勢將是高性能計算機最重要的趨勢,高性能計算機的主要用途是網路計算環境中的主機。以後越來越多的應用是在網路環境下的應用,會出現數以十億計的客戶端設備,所有重要的數據及應用都會放在高性能伺服器上,Client/Server模式會進入到第二代,即伺服器聚集的模式,這是一個發展趨勢。
網格(Gird)已經成為高性能計算的一個新的研究熱點,是非常重要的新興技術。網路計算環境的應用模式將仍然是Internet/Web ,但5~10年後,信息網格模式將逐漸成為主流。在計算網格方面美國大大領先於其他國家。有一種觀點認為,美國當前對於網格研究的支持可與其70年代對Internet研究的支持相比,10年後可望普及到國民經濟和社會發展的各個領域。網格與Internet/Web的主要不同是一體化,它將分佈於全國的計算機、數據、貴重設備、用戶、軟體和信息組織成一個邏輯整體。各行業可以在此基礎上運行各自的應用網格。最近美國開始了STAR-TAP計劃,試圖將網格擴展到全世界。
在體系結構上,一個重要的趨勢是超級伺服器正取代超級計算機而成為高性能計算的主流體系結構技術。高性能計算機市場的低檔產品將主要是SMP(Symmetric MultiProcessor,對稱多處理機),中檔產品是SMP、CC-NUMA(Cache Coherent-Non Uniform Memory Access,支持緩存一致性的非均勻內存訪問)和機群,高檔產品則將採用SMP或CC-NUMA節點的機群。在2001年左右,將會出現結合了NUMA(COMA和CC-NUMA)和機群體系結構優點的混合式結構,稱之為Cluster-NUMA(C-NUMA)系統。可重構、可分區、可配置特性將變得越來越重要。此外還有一種新興的稱為多線程(Multithreading)體系結構將用於超級計算機中,它的代表是Tera公司的MTA系統,一台8 CPU的MTA已經成功地運行在聖地亞哥超級計算機中心。值得注意的是,所有廠家規劃的高檔系統都是機群,已經有廠家開始研究C-NUMA結構。
美國一直是世界上最重視高性能計算機、投入最多和受益最大的國家,其研究也領先於世界。美國能源部的加速戰略計算ASCI計劃,目標是構造100萬億次的超級計算機系統、軟體和演演算法,在2004年真實地模擬核爆炸;白宮直屬的HECC(High-End Computing and Computations)計劃,對高性能計算的關鍵技術進行研發,並構建高性能基礎設施;PetaFLOPS計劃開發構造千萬億次級系統的技術;最新的Ultrascale計劃目標在2010年研製萬萬億次級系統。日本計劃將於2002年研製成40萬億次的并行向量機。歐洲的強項則主要體現在高性能計算機的應用方面。
總的來說,國外的高性能計算機應用已經具有相當的規模,在各個領域都有比較成熟的應用實例。在政府部門大量使用高性能計算機,能有效地提高政府對國民經濟和社會發展的宏觀監控和引導能力,包括打擊走私、增強稅收、進行金融監控和風險預警、環境和資源的監控和分析等等。
在發明創新領域,殼牌石油公司通過全球內部網和高性能伺服器收集員工的創新建議,加以集中處理。其中產生了一種激光探測地下油床的新技術,為該公司發現了3億桶原油。在設計領域,好利威爾公司和通用電氣公司用網路將全球各地設計中心的伺服器和貴重設備連於一體,以便於工程師和客戶共同設計產品,設計時間可縮短100倍。對很多大型企業來說,採購成本是總成本的重要組成部分。
福特用高性能計算機構造了一個網上集市,通過網路連到它的3萬多個供貨商。這種網上採購不僅能降低價格,減少採購費用,還能縮短採購時間。福特估計這樣做大約能節省80億美元的採購成本。此外,製造、後勤運輸、市場調查等領域也都是高性能計算機大顯身手的領域。
高性能計算機能為企業創造的價值是非凡的,國外的企業和用戶已經充分地認識到這一點。一個證明是,20世紀90年代中期以來,國外80%以上企業的信息主管在選購機器時考慮高性能計算機,而在20世紀90年代初,這個數字只有15%。
在國內這方面的宣傳教育工作還很不夠,沒有讓企業、政府和社會充分認識到高性能計算機的益處,從而導致了一些觀念上的誤解。以往一提起高性能計算機,人們馬上就會聯想到用於尖端科學計算的超級計算機。實際上,高性能計算機90%的用途是非科學計算的數據處理、事務處理和信息服務,它早已不是象牙塔里的陽春白雪。隨著“網路計算”和“后PC時代”的到來,全世界將有數十億的客戶端設備,它們需要連到數百萬台高性能伺服器上。高性能計算機將越來越得到產業界的認同,成為重要的生產工具。
此外,人們一直以來還有這樣一個認識誤區,認為高性能計算機是面向高新產業和服務業的,而傳統產業(尤其是製造業)並不需要使用。事實上,高性能計算機能夠廣泛應用於生物、信息、電子商務、金融、保險等產業,它同時也是傳統產業(包括製造業)實現技術改造、提高生產率——“電子生產率”(e-productivity)和競爭力的重要工具。高性能計算已從技術計算(即科學計算和工程計算)擴展到商業應用和網路信息服務領域。的曙光2000-Ⅱ就瞄準了技術計算、商業應用和網路服務這3個領域的應用。
應該說,高性能計算機在國內的研究與應用已取得了一些成功,包括曙光2000超級伺服器的推出和正在推廣的一些應用領域,如航 空航天工業中的數字風洞,可以減少實驗次數,縮短研製周期,節約研製費用;利用高性能計算機做氣象預報和氣候模擬,對厄爾尼諾現象及災害性天氣進行預警,國慶50周年前,國家氣象局利用國產高性能計算機,對北京地區進行了集合預報、中尺度預報和短期天氣預報,取得了良好的預報結果;此外,在生物工程、生物信息學、船舶設計、汽車設計和碰撞模擬以及三峽工程施工管理和質量控制等領域都有高性能計算機成功應用的實例。
但是總的說來,高性能計算機在國內的應用還比較落後,主要原因在於裝備不足、聯合和配套措施不力及宣傳教育力度不夠。首先,國內高性能計算機的裝量明顯不足。1997年世界高性能計算機的銷售額美國約為220億美元,中國約為7億美元。美國的微機銷售額約佔世界市場的38%,高性能計算機佔世界的34%,均高於其GDP所佔世界份額(25%左右)。中國的微機銷售額約佔世界市場的3%,高於中國GDP的份額(2.6%);但中國高性能計算機銷售額所佔世界份額僅為1%左右,低於GDP的份額。從另一個角度看,中國的微機市場接近美國的1/10,但中國的高性能計算機市場不到美國的1/30。
裝備不足嚴重影響了高性能計算機應用的開發和人才的培養,這些反過來又影響了高性能計算機的使用和裝備。值得慶幸的是,隨著網路化和信息化工作的深入,國內社會已開始意識到高性能計算機的重要性。1999年,中國高性能計算機的市場銷售額猛增了50% 以上。
除了裝備不足之外,我認為社會各行業、各層次的合作和配合不力也是阻礙高性能計算機應用發展的重要原因。應用市場的擴展關鍵要靠聯合,在中國高性能計算機領域,系統廠商、應用軟體廠商與最終用戶和服務商之間並沒有結成有效的戰略聯盟,形成優勢互補的局面。我希望看到的是,曙光、聯想、浪潮的伺服器,運行著東大阿爾派、用友、同創等廠家的軟體,在新浪網、8848網上為各行業的用戶提供各種服務。國家正在實施一個“國家高性能計算環境”的計劃,正朝著這方面努力。
國家863計劃主題正在實施一個“國家高性能計算環境”的項目,計劃到2000年年底在全國建設10個左右的高性能計算中心,這些中心將通過千兆位網路互連。目標就是盡量讓全國用戶免費共享全國的計算資源、信息資源和人才資源。這只是一個初期的項目,估計在2000年下半年會規劃更大的項目。值得注意的是,已經規劃的應用包括生物信息學、數字圖書館、科學資料庫、科普資料庫、汽車碰撞、船舶設計、石油油藏模擬、數字風洞、氣象預報、自然資源考察和遠程教育等領域。
2000年5月14~17日,國內將在北京組織一個“亞太地區高性能計算國際會議及展覽”,屆時全球二十幾個國家和地區的代表以及國內外主流的伺服器廠商將參加會議,會議計劃圍繞一些課題做特邀報告:美國工程院院士、Microsoft資深科學家Gordon Bell將討論“后PC時代:當計算、存儲和帶寬都免費時,我們面臨什麼樣的挑戰?”,自由軟體創始人Richard Stallman 將討論“自由軟體運動及GNU/Linux”,俄羅斯科學院院士Boris Babayan將介紹俄羅斯花了6年功夫新近發明的一種電腦晶元,據稱它比Intel的Pentium Ⅲ和Itanium快幾倍,而且具有安全、防病毒功能。
IBM深度計算研究所所長Pulley Blank將介紹“深藍、基因藍以及IBM的深度計算戰略”。從會議的內容上我們能夠看出,高性能計算的範圍已超出了高端科學計算的領域。相信這次會議對國內高性能產業的發展將起到一定的推動作用。
此外,國家還有一個重大基礎研究計劃(也叫973項目)。高性能計算已經成為科技創新的主要工具,能夠促成理論或實驗方法不能取得的科學發現和技術創新。973項目中的很多項目(尤其是其中的“高性能軟體”和“大規模科學計算”項目)都與高性能計算機有著密切的關係。
想象一下,你是科研機構里的實驗狂人,要進行一個複雜的X射線轉化運算或者為下一個實體實驗進行電腦模擬模擬。如果使用普通PC,基本無法進行;如果使用一個普通的工作站,至少需要數周的時間;如果使用單位里的伺服器集群,得出結果的運算時間並長,但你需要很長的排隊時間,因為它是公用的。但是,如果你擁有一台基於GPU運算的超級計算機,足不出戶,只要在自己的桌面上,就可以輕鬆完成這項複雜工作,而所用的時間,甚至比實驗室里的大塊頭伺服器集群還要短。
現在,對於國內用戶來說,個人桌面超級運算不再是夢想。近日,在其工作站業務迎來10周年之際,方正科技宣布將在中國市場推出具有超級計算能力的高性能工作站。其最新推出的旗艦機型美崙3400 2800,提供強大圖形處理與高性能計算解決方案,採用全新英特爾“至強”處理器,搭載新一代NVIDIA Tesla GPU,能實現高性能的GPU超級運算,從而將工作站變身為桌面型超級計算機,滿足專業用戶的高性能計算需求。
對於國內用戶來說,GPU(圖形處理器)並不陌生,但對於GPU計算這一新興運算方式,可能還不熟悉。簡單來說,GPU計算即使用GPU(圖形處理器)來執行通用科學與工程計算。目前的CPU最多只集成了4個內核,而GPU已經擁有數以百計的內核,在高密度并行計算方面擁有得天獨厚的優勢。方正科技推出的高性能計算工作站,使用CPU+GPU的異構計算模型,應用程序的順序部分在CPU上運行,而計算密集型部分則由GPU來分擔。這樣,系統計算力得到淋漓盡致的釋放,應用程序的運行速度能夠提升1-2個數量級。
GPU計算的概念一經提出,就在高性能計算領域掀起了一場前所未有的風暴。在過去4年裡,已經有累計1億顆以上的GPU被三星、摩托羅拉等公司和哈佛、斯坦福等上百所高校研究機構應用於癌症的治療和科研教學等多種領域。日本最快的超級電腦也採用了GPU計算這項技術。目前,微軟的WIN7已經融入GPU運算功能。而下游廠商如惠普、方正、聯想等也一直積極緊跟技術潮流,積極研發GPU計算應用產品。NVIDIA的首席執行官黃仁勛曾大膽預言:“2009年是GPU引爆年,CPU+GPU的個人運算時代已經來臨。”
方正科技將GPU計算應用帶入中國,為國內教育科研院校和機構、各大企業打造了一款桌面型高性能計算工作站。該產品可廣泛應用於生物信息及生命科學、流體動力學、大氣和海洋建模、空間科學、電子設計自動化、圖形成像等眾多領域。相對於傳統的伺服器集群,方正科技推出的GPU超級計算機在性價比、佔地空間、功耗等方面的優勢是壓倒性的。做一個簡單的算術:某大學原來用的伺服器集群擁有256顆AMD皓龍雙核處理器核,構建成本是500萬美元,由全校共同來使用;但如果換成4台方正美崙3400 2800高性能計算工作站,性能更優,成本只有1萬美元,耗電能減少10倍以上,即使每個研究人員桌面配備一台仍然划算。
作為國內較早涉足工作站業務的民族廠商,方正科技在工作站領域的研發與開拓上已經走過了10個春秋,取得了不俗的成績。其工作站負責人表示,在10周年這個具有強烈紀念意義的時間點上,推出基於全新計算方式的GPU超級計算機,表明方正科技工作站根植 客戶應用需求,緊跟技術潮流,不斷推陳出新的決心。
中國在高端計算機的研製方面已經取得了較好的成績,掌握了研製高端計算機的一些關鍵技術,參與高端計算機研製的單位已經從科研院所發展到企業界,有力地推動了高端計算的發展。隨著中國信息化建設的發展,高性能計算的應用需求在深度和廣度上都面臨蓬勃發展。
高性能計算作為第三大科學方法和第一生產力的地位與作用被廣泛認識,並開始走出原來的科研計算向更為廣闊的商業計算和信息化服務領域擴展。更多的典型應用在電子政務、石油物探、分子材料研究、金融服務、教育信息化和企業信息化中得以展現。經過十年的發展,中國在高性能計算水平上已躋身世界先進水平。
國內做高性能計算的企業中有三家主力廠商,他們是曙光、聯想和浪潮。863計劃十幾年來,曙光始終在研發過程中起著帶頭作用。高性能市場中,曙光高性能計算機銷量已超過1000套,在國內應用是最廣泛的。聯想進入高性能市場比較晚,但是從其公司運作能力和市場化的能力看,雖然其遇到了一些困難,但是未來的發展潛力巨大。而浪潮以伺服器起家,但在高性能方面,原來技術較弱,但是比較專一於高端商用市場,通過與大專院校的合作,發展比較快。
賽迪顧問分析師劉新在接受《中國電子報》記者採訪時稱,看國內高性能計算的前三名,曙光的整合計算、細分應用是其特點。由於具有長期的技術積澱,深厚的行業背景,鮮明的品牌形象,是國內三大品牌中商業化最成功的企業,但面臨國內、國外的雙向夾擊,發展道路坎坷不平。而聯想長期“貿工技”的戰略使其可能會缺乏技術的積澱,做慣了PC設備供應和服務,在高性能計算領域顯得底氣不足,其主要市場策略依然延續PC模式,依靠低價等吸引用戶是一大特色。而浪潮給人的感覺是在高性能方面有點缺乏技術實力和遠見。
也許有人認為,高性能計算離我們的實際生活還很遙遠,但是金融、電信、稅務、能源、製造等行業中的很多企事業都已經開始應用高性能計算,而作為普通百姓的衣食住行,我們在刷卡購物、打電話、聽天氣預報、出門坐車時也已經在享受高性能計算所帶來的準確與方便。
通過記者的採訪,相關廠商一致認為,高性能計算走向普及已是大勢所趨。這主要是由於商品化趨勢使得大量生產的商品部件接近了高性能計算機專有部件,標準化趨勢使得這些部件之間能夠集成在一個系統中。
高性能計算機的主流體系結構收縮成了三種,即SM、CC-NUMA、Cluster。在產品上,只有兩類產品具有競爭力:一是高性能共享存儲系統;二是工業標準機群,包括以IA架構標準伺服器為節點的PC機群和以RISC SMP標準伺服器為節點的RISC機群。當前,對高性能計算機產業影響最大的就是“工業標準機群”了,這也反映了標準化在信息產業中的巨大殺傷力。工業標準機群採用量產的標準化部件構成高性能計算機系統,極大地提高了性能價格比,從科學計算開始逐漸應用到各個領域。
浪潮北京公司伺服器產品經理丁昱對《中國電子報》記者說,事實上,中國機群發展進入了一個瓶頸期,多數稍具技術實力的廠商都可以設計出計算速度上萬億次的高性能計算機。可以說,在充足的資金前提下,設計一套進入全球前十名的高性能機群系統,並非難事。在科學計算方面,唯一的問題因素是資金。浪潮基於彈性部署理念的計算能力、數據通信、輸入輸出非單極優化的MABS體系結構,為高性能商用伺服器系統實現技術突破奠定了理論基礎。
曙光公司天潮系列產品經理曹振南告訴《中國電子報》記者,機群的優勢主要體現在更高的性能價格比,機群系統已經成為高性能計算機的發展方向,世界上TOP500排行榜的高性能計算機系統絕大多數是機群系統;更高的可擴展性,機群系統可以通過原有預留的擴展介面進行無縫的擴展;更高的可管理性,通常管理一個機群系統要比管理一個小型機系統要簡單得多;更高的系統魯棒性(健壯或強壯),機群系統都是採用了標準的硬體設備,容易採購,同時也較容易維護,有更多國內廠商支持;對應用系統的更多的支持,機群系統可以支持大量的操作系統並且可以支持多種操作系統,也支持32位和64位的軟體系統,在機群系統上運行的軟體是小型機系統的成百上千倍。
20世紀90年代以來,中國在高性能計算機的研製方面已經取得了較好的成績,掌握了研製高性能計算機的一些關鍵技術,參與高性能計算機研製的單位已經從科研院所發展到企業界,有力地推動了高端計算的發展。中國的高性能計算環境已得到重大改善,總計算能力與發達國家的差距正逐步縮小。
隨著曙光、神威、銀河、聯想、浪潮、同方等一批知名產品的出現,中國成為繼美、日之後第三個具備高端計算機系統研製能力的國家,被譽為世界未來高性能計算市場的“第三股力量”。在國家相關部門的不斷支持下,一批國產超級計算機相繼面世,大量的高性能計算系統進入教育、科研、石油、金融等領域,尤其值得一提的是曙光4000A在全球TOP500中排名進入前十,並成功應用於國家網格主節點之一——上海超級計算中心。
但是,從總體上講,中國高性能計算應用的研究與開發明顯滯後於高性能計算機的發展,應用的并行度普遍在百十量級,應用到更大規模的很少(並非沒有需求)。
浪潮丁昱告訴《中國電子報》記者,中國的高性能計算髮展最大的障礙是品牌的障礙和應用的障礙。這和中國高性能發展起步較慢有關係。年限比較短,應用的經驗比較少。但隨著國內高性能計算的快速發展,這方面的缺陷會得到很大改善。但隨著越來越多的用戶開始採用高性能計算機,應用軟體的發展后滯明顯嚴重。另外,一些用戶對傳統RISC小型機存在使用習慣和品牌偏好,接受Linux機群需要廠商做大量的工作。
曙光曹振南在接受《中國電子報》記者採訪時稱,中國高端計算應用的研究與開發明顯滯後於高端計算機的發展,應用到大規模的很少。高端應用軟體的開發和高效并行演演算法的研究尚不能與高端計算機發展同步,在一定程度上存在為計算機“配”軟體的思想。對應用的投入遠遠不夠,應用研發的力量薄弱且分散,缺乏跨學科的綜合型人才,從事高端應用軟體研發的單位很少,沒有良好的、相互交流的組織渠道等。還有就是政府在採購中依然選擇國際品牌,缺乏對國產品牌的支持。
聯想高性能伺服器事業部總經理祝明發則認為,中國高性能計算生存的關鍵在應用。他談到IBM、惠普、Sun等公司的高性能計算業務在商業市場的比例為90%,而中國的高性能計算在商業計算市場開拓方面仍存在很大差距。從來看,中國的聯想、曙光、浪潮等廠家完全有能力做出運算速度達到40萬億次的超級計算機,但關鍵就是有沒有找到應用需求。比如,在科學計算中獨樹一幟的向量計算,因為成本高、商用計算能力不強而僅停留在科學計算的狹窄領域。
提及摩爾定律,作為計算機發展的第一定律一直在引領IT產業的前行。不過隨著多核技術的發展和應用,目前摩爾定律在面臨挑戰的同時,在某些領域已經被超越。例如在日益普及的高性能計算(HPC)中。那為何摩爾定律會首先在高性能計算領域被超越?這之中又隱含著怎樣的產業趨勢?
首先從代表全球高性能計算水平和趨勢的全球高性能計算TOP500近幾年性能發展的趨勢看,無論是最大性能(全球排名第一的系統)、還是最小性能(全球排名最後)和平均性能,其發展曲線的速度是基本一致的。但與摩爾定律的發展曲線相比,則明顯處於陡勢的增長態勢。這說明這兩年來,高性能計算性能和應用的發展速度已經超越了摩爾定律。熟悉摩爾定律的人都知道,摩爾定律有三種解釋。一種是集成電路晶元上所集成的電路的數目,每隔18個月就翻一番;第二種是微處理器的性能每隔18個月提高一倍,而價格下降一半;第三種解釋是用一個美元所能買到的電腦性能,每隔18個月翻兩番。這三種解釋中業內引用最多的是第一種。但具體到高性能計算,筆者更願意用第二或者第三種來解釋。
按理說,隨著高性能計算性能的不斷提升和系統的日益龐大,高性能計算用戶無論在初期的採購搭建系統,還是後期的使用中的成本都會大幅的增加,在經濟危機的特殊時期,高性能計算如此大的TCO會導致用戶的減少和整體性能的下降才對。但前不久發布的全球高性能計算TOP500證明,增長的勢頭未減,這除了市場和用戶的需求外,更在於處理器廠商採用新的技術,在性能提升的同時,讓用戶以更低的成本享受到更高、更多的計算性能。從這個意義上看,摩爾定律在被延續的同時也正在被超越,即在高性能計算領域,用戶性能/投入比遠遠大於摩爾定律。當然這主要得益於處理器製程、架構技術、多核技術、節能技術、軟體優化和快速部署等。
例如從製程和核數上看,最新的全球高性能計算TOP500排名顯示,45納米已經佔據了絕對的主流。而多核也達到了全球TOP500的2/3。從部署的速度看,AMD剛剛發布不久的6核就已經有兩套進入TOP500中。而英特爾今年3月才正式發布的新的Nehalem多核架構的高性能計算系統更有33套(基於這個處理器的系統)進入TOP500,其中有兩套在TOP20里。快速的部署給用戶帶來的是最新技術和性能的獲得。
當然對於用戶而言,多核並非是關鍵,重要的是如何充分發揮多核的效能。這就需要相關的平台技術和軟體優化。例如在高性能計算領域,業內都聽說過“半寬板”這個標準。這個“半寬板”標準其實是英特爾在幾年前提出的,半寬的小板在加高計算密度的同時,節約了很多復用的部件,在加強高性能計算的密度同時,配合散熱的技術設計,可以提供更多的計算能力同時降低能耗。這就引出了一個新的發展方向,即高性能計算未來發展就是能耗更多被用於計算性能的提高,而不是散熱。此外,就是SSD(固態硬碟),它可以在大幅提高高性能計算系統可靠性和I/O性能的同時,還可以降低功耗。而軟體優化更是高性能計算中重中之重的部分,編譯器、函數庫以及MPI庫,所有這些可以幫助ISV能夠把多核處理器的計算性能充分發揮出來。
由此來看,在高性能計算領域,單純的處理器已經不能滿足市場和用戶的需求,它們需要的是高性能計算平台級的解決技術及方案。這也是為什麼在去年全球高性能計算TOP500開始引入能效的主要原因。
說到能效,筆者早就聽說在業內有個與摩爾定律同樣重要的“基辛格規則”。它是以處理器業界聞名的英特爾首席技術官帕特·基辛格名字命名的。該規則的主旨是今後處理器的發展方向將是研究如何提高處理器能效,並使得計算機用戶能夠充分利用多任務處理、安全性、可靠性、可管理性和無線計算方面的優勢。如果說“摩爾定律”是以追求處理性能為目標,而“基辛格規則”則是追求處理器的能效,這規則目前至少在高性能計算領域已經得到了驗證,而它由此帶來的是摩爾定律的被超越,即用戶將會在更短的周期,以更低的價格獲得更高的能效。
人類從人力推算到高性能計算機,傾注了無數人大量的心血和努力。對於現代天氣預報和氣象研究工作,高性能計算機則佔據了極其重要的位置。
隨著社會經濟的發展,政府、社會和公眾對氣象預報和服務提出了更高的要求,特別是一些特殊氣象保障任務需要預報員提供定點、定時、定量的精細氣象預報和服務。而對於現代天氣預報而言,為確保其實施的實效性和運行的穩定性,必然要求建立在數值預報基礎之上,但數值模式普遍具有計算規模巨大、高精度等特點,於是高性能計算機便成為了現代氣象研究的中流砥柱。
數值天氣預報水平的高低已成為衡量世界各國氣象事業現代化程度的重要標誌。美國國家大氣研究中心與科羅拉多大學合作,採用了IBM藍色基因超級計算機來模擬海洋、天氣和氣候現象,並研究這些現象對農業生產、石油價格變動和全球變暖等問題的影響。日本科學家研製成功了代號為“地球模擬器”的超級計算機,其主要目的就是要提供準確的全球性天氣預報,使各個國家和地區更好地防禦暴風雪、寒流和酷暑期的到來。
我國是一個幅員遼闊的國家,在氣候上呈現多層次、多樣性、多變性等特點,尤其是近幾年洪澇、乾旱等自然災害比較嚴重,及時、準確的天氣預報逐步受到重視,因此隨著地區氣象市場的逐步成熟,更高效率的高性能計算機成為了人們關注的對象。作為國產伺服器第一品牌的曙光公司,一直以來就非常關注氣象領域對高性能計算機的需求。
由於採用了軟硬體一體化設計,曙光氣象專用機在硬體平台上直接移植了目前在中尺度數值天氣預報領域處於領先地位的NCA MM5系統,這套系統每天自動定時定點進行業務系統預報,從數據導入到氣象繪圖的整個流程自動完成,不需要人工干預;用戶可以隨時監控整個系統的運行,大大節約了操作的時間。甚至不需要任何計算機系統知識的培訓,用戶就可以快速掌握整個預報系統。而且該系統既可以作為業務預報系統,又可以作為氣象研究和測試的平台,一機多用,用戶可以根據自己的需要進行參數設定和演演算法調試。系統還提供了數據保存功能,使得用戶可以對以往一個月內不滿意的預報進行重新計算和分析,最大限度地滿足了氣象部門準確及時預報的需求。
氣象工作離不開高性能計算機,而且每隔三四年就有一次主機的更新,速度還要提高一個數量級。在前10年,我們還只能選擇國外品牌高性能計算機,而近幾年以曙光為代表的高性能計算機已經明顯提升了氣象服務的綜合實力。曙光機在我國氣象領域取得了非常廣泛的應用,大大促進了中國氣象科技水平的提升,為老百姓的日常出行和眾多國家重大工程提供了強有力的保障。從日常天氣預報到大型氣候研究、從陸地到海洋、從地面水文氣象到太空天氣等領域,都活躍著曙光高性能計算機的身影。
