LogP模型
LogP模型
作為大規模并行機上的并行計算模型,LogP模型演演算法為我們提供了獨立於具體系統的演演算法設計依據。它可以精確地調度通信與計算。
隨著大規模并行系統 M PP的發展 ,其體系結構逐步趨向一致。這種發展趨勢使得用一種獨立於具體機器的并行計算模型作為并行演演算法的設計依據成為可能。又因為依此得到的演演算法具有較好的可操作性和可移植性 , 使得并行計算模型具有很強的吸引力和生命力。
在已提出的各種模型中,最有影響的是LogP模型。
LogP是由大衛·卡勒等人提出的,它使用了L,O,G,P四個參數來描述這個模型。LogP模型是一種面向分散式存儲器、點對點通信的多計算機系統的并行計算模型。
L (Latency) :
表示信息從源到目的地所需的時間;
O (Overhead) :
表示處理器接受或發送一條消息所需額外開銷,並且在此期間處理器不能做作任何操作;
G (Gap):
表示處理器連續進行兩次發送或接收消息之間必須有的時間間隔;
P (Processor) :
表示處理器的數目。
由上可以看出,LogP模型一方面充分討論了網路的通信特性,另一方面卻放棄了對網路拓撲的討論。在LogP中沒有出現超級步的概念,這是因為LogP中是消息同步的,也就是說,一旦消息到達了處理器我們就可以使用,而不必要等到下一個超級步。
LogP模型下 , 網路的容量是有限度的 , 在任何時刻的網上 , 從任何處理器發出或向任何處理器發去的消息個數不得超過 [L /g ]個 , 否則便會發生阻塞。 LogP是個非同步模型 ,通信與計算可以重疊 , 並完全採用消息傳遞的方式進行通信和同步。Log P模型以相當簡明的參數刻劃目前的 M PP, 更準確的說 , 刻劃的是 M PP通信網路的性能。在 LogP模型下 , 只要做到網路輕載且只有小消息 , 便可以充分發揮四個參數所賦予的精確性 , 進行周密的演演算法設計 , 以充分利用處理機和網路帶寬。
乙太網是共享介質的匯流排傳輸機制,所有處理機在網路中的位置等價,且輕載時任意兩台處理機間傳遞相同長度消息的時間是相同的,所以可用點對點的通信來確定L和o。
對點對點通信,採用“乒乓法”進行測試,即進程0發送長度為 N 位元組的消息到進程1,然後等待從進程1返回的消息;此時,進程1執行一個阻塞式接收語句,一旦收到進程0發送來的消息,立即返回一個同樣的消息。將該過程重複進行多次,排除起始兩次通信,取平均值再除以2,就得到點對點通信所需的時間。變換消息長度,得到通信時間,然後採用一階線性擬合的方法,就得到點對點通信所需時間的近似經驗公式。測試環境是由四台配置完全相同的微機(均為K6/266,32M RAM)組成的10 M區域網,軟體平台為SCOUNIX OpenServer System 5.0.2和PVM 3.3.11。記一個數據包的軟體開銷和網路傳輸延遲分別為 oˆ 和 Lˆ,而該數據包平均每位元組的軟體開銷和網路延遲分別為 o 和 L。
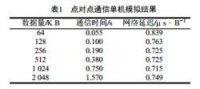
LogP模型
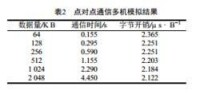
LogP模型
LogP值指某物質在正辛醇/水兩相體系中的分配係數的對數值,反映了物質在油水兩相中的分配情況。LogP值越大,說明該物質越親油;反之,LogP值越小,則說明該物質越親水。有時候也被稱作疏水常數,包括化合物疏水常數ClogP和分子疏水常數MlogP。