集成學習
集成學習
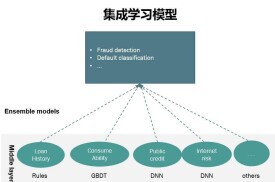
集成學習是使用一系列學習器進行學習,並使用某種規則把各個學習結果進行整合從而獲得比單個學習器更好的學習效果的一種機器學習方法。一般情況下,集成學習中的多個學習器都是同質的"弱學習器"。
集成學習的主要思路是先通過一定的規則生成多個學習器,再採用某種集成策略進行組合,最後綜合判斷輸出最終結果。一般而言,通常所說的集成學習中的多個學習器都是同質的"弱學習器"。基於該弱學習器,通過樣本集擾動、輸入特徵擾動、輸出表示擾動、演演算法參數擾動等方式生成多個學習器,進行集成后獲得一個精度較好的"強學習器"。
隨著集成學習研究的深入,其廣義的定義逐漸被學者們所接受,它是指對多個學習器集合採用學習的方式,而不對學習器性質加以區分。根據這一定義,多學習器系統 (multi-classifier system) 、多專家混合 (mixture of experts) 以及基於委員會的學習 (committee-based learning)等多個領域都可以納入到集成學習中。但當前仍然以同質分類器的集成學習研究居多。
集成學習的主要發展過程見圖1。
圖1 集成學習發展脈絡
以三分類問題為例,假如有個分類器相互獨立,錯誤率都為,使用簡單的投票法組合分類器,其分類器的錯誤率為:
從上式可看出, 時,錯誤率隨增大而減少。如果每個分類器的錯誤率都小於,且相互獨立,那麼集成學習器個數越多,錯誤率越小,無窮大時,錯誤率為0。
另外以表為例,代表分類正確,代表分類錯誤,集成方法為簡單投票。從表1中可看出,只有當個體分類器"好而不同"時,集成才能發揮作用。因此,集成學習的關鍵在於多個學習器的兩個指標,即"精確性"和"多樣性"。
表1 簡單投票法示例
各種不同的Boosting演演算法有很多,但最具代表性的當屬AdaBoost演演算法,而且各種不同Boosting演演算法都是在AdaBoost演演算法的基礎上發展起來的。因此下面以AdaBoost演演算法為例,對Boosting演演算法進行簡單的介紹。
首先給出任意一個弱學習演演算法和訓練集,其中,,表示某個域或實例空間,在分類問題中是一個帶類別標誌的集合。
初始化時,Adaboost為訓練集指定分佈為,即每個訓練例的權重都相同為。接著,調用弱學習演演算法進行T次迭代,每次迭代后,按照訓練結果更新訓練集上的分佈,對於訓練失敗的訓練例賦予較大的權重,使得下一次迭代更加關注這些訓練例,從而得到一個預測函數序列,對每個預測函數也賦予一個權重,預測效果好的,相應的權重越大。T次迭代之後,在分類問題中最終的預測函數採用帶權重的投票法產生。單個弱學習器的學習準確率不高,經過運用Boosting演演算法之後,最終結果準確率將得到提高。
Bagging(bootstrap aggregating)是通過結合幾個模型降低泛化誤差的技術,主要思想是分別訓練幾個不同的模型,然後讓所有模型表決出測試樣例的輸出。這是機器學習常規策略的一個例子,被稱為 模型平均。模型平均奏效的原因是不同的模型通常不會在測試集上產生完全相同的誤差。
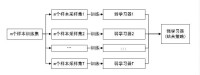
圖2 Bagging流程
隨機森林是2001年由Leo Breiman將Bagging集成學習理論與隨機子空間方法相結合,提出的一種機器學習演演算法。隨機森林是以決策樹為基分類器的一個集成學習模型,它包含多個由Bagging集成學習技術訓練得到的決策樹,當輸入待分類的樣本時,最終的分類結果由單個決策樹的輸出結果投票決定。隨機森林解決了決策樹性能瓶頸的問題,對雜訊和異常值有較好的容忍性,對高維數據分類問題具有良好的可擴展性和并行性。此外,隨機森林是由數據驅動的一種非參數分類方法,只需通過對給定樣本的學習訓練分類規則,並不需要先驗知識。
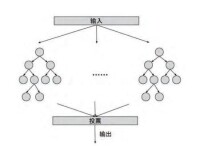
圖3 隨機森林