漢字識別
把漢字輸入計算機的主要方式之一
漢字識別(Chinese character recognition) 應用計算機自動識別漢字,是把漢字輸入計算機的主要方式之一。
按書寫方式區分,漢字識別可分為手寫漢字識別和印刷體漢字識別兩大類。按工作方式區分,則可分為聯機漢字識別和離線漢字識別兩種方式。前者為實時識別,書寫者在專用書寫書寫的漢字即時送入計算機進行識別;後者為非實時識別,列印或已寫好的書面文字經光電轉換裝置(如掃描儀等)變為電信號後送入計算機進行識別,通常把這種設備叫做光電閱讀機(optical character reader),記為 OCR。
漢字識別是模式識別的一個分支。漢字是一種特殊的模式,其特點是字數多,字形複雜,有的字形十分相似,印刷體漢字又有多種字體(仿宋、宋、黑、楷書與列印體等)和多種大小不同的字型大小。因而漢字識別是一個相當困難的問題。
和一般的模式識別相同,漢字識別的基本方法主要有統計法和結構法兩種。漢字由筆劃組成,具有較嚴格的拓撲結構,包含豐富的結構信息,因而結構法較適用於漢字識別。中國和日本學者先後提出若干以結構信息為主的統計與結構法相結合的新演演算法,選用了-些分類能力強、抗畸變和干擾性能好的特徵,較好地解決了多子體多字型大小混合排印的印刷體漢字離線識別和限制性手寫漢字聯機識別問題。研製成功幾種識別系統,並已付諸應用。
漢字識別系統大體上可分為預處理、特徵提取與識別和后處理三部分,見圖。在離線識別系統中,掃描儀將列印或書寫在紙上的漢字文稿,轉換為電信號輸入計算機,經版面分析、逐字分割和歸一化等漢字識別預處理后,獲得版面上各個漢字的二維點陣圖形。特徵提取和識別部分的任務是提取識別特徵,並將它和存儲在識別字典內的每個特徵模板逐一進行比較、判別,得出識別結果。漢字識別後處理部分利用片語或上下文關係糾正識別結果中的一些錯誤,以提高整個系統的正確識別率。
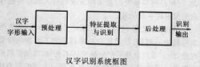
圖1 漢字識別系統框圖
利用計算機自動識別字元的技術,是模式識別應用的一個重要領域。人們在生產和生活中,要處理大量的文字、報表和文本。為了減輕人們的勞動,提高處理效率,50年代開始探討一般文字識別方法,並研製出光學字元識別器。60年代出現了採用磁性墨水和特殊字體的實用機器。60年代後期,出現了多種字體和手寫體文字識別機,其識別精度和機器性能都基本上能滿足要求。如用於信函分揀的手寫體數字識別機和印刷體英文數字識別機。70年代主要研究文字識別的基本理論和研製高性能的文字識別機,並著重於漢字識別的研究。
識別系統:
文字識別一般包括文字信息的採集、信息的分析與處理、信息的分類判別等幾個部分。
信息採集 將紙面上的文字灰度變換成電信號,輸入到計算機中去。信息採集由文字識別機中的送紙機構和光電變換裝置來實現,有飛點掃描、攝像機、光敏元件和激光掃描等光電變換裝置。
信息分析和處理 對變換后的電信號消除各種由於印刷質量、紙質(均勻性、污點等)或書寫工具等因素所造成的噪音和干擾,進行大小、偏轉、濃淡、粗細等各種正規化處理。
信息的分類判別 對去掉雜訊並正規化后的文字信息進行分類判別,以輸出識別結果。
識別方法:
文字識別方法 文字識別方法基本上分為統計、邏輯判斷和句法三大類。常用的方法有模板匹配法和幾何特徵抽取法。
① 模板匹配法 將輸入的文字與給定的各類別標準文字(模板)進行相關匹配,計算輸入文字與各模板之間的相似性程度,取相似度最大的類別作為識別結果。這種方法的缺點是當被識別類別數增加時,標準文字模板的數量也隨之增加。這一方面會增加機器的存儲容量,另一方面也會降低識別的正確率,所以這種方式適用於識別固定字型的印刷體文字。這種方法的優點是用整個文字進行相似度計算,所以對文字的缺損、邊緣雜訊等具有較強的適應能力。
② 幾何特徵抽取法 抽取文字的一些幾何特徵,如文字的端點、分叉點、凹凸部分以及水平、垂直、傾斜等各方向的線段、閉合環路等,根據這些特徵的位置和相互關係進行邏輯組合判斷,獲得識別結果。這種識別方式由於利用結構信息,也適用於手寫體文字那樣變型較大的文字。
隨著我國信息化建設的全面開展,OCR文字識別技術誕生20餘年來,經歷從實驗室技術到產品的轉變,目前已經進步行業應用開發的成熟階段。相比發達國家的廣泛應用情況,OCR文字識別技術在國內各行各業的應用還有著廣闊的空間。隨著國家信息化建設進入內容建設階段,為OCR文字識別技術開創了一個全新的行業應用局面。文通,雲脈技術、漢王等中國文字識別的領軍企業將會更加深入到信息化建設的各個領域。