kd-tree
kd-tree
SIFT演演算法中做特徵點匹配的時候就會利用到k-d樹。而特徵點匹配實際上就是一個通過距離函數在高維矢量之間進行相似性檢索的問題。針對如何快速而準確地找到查詢點的近鄰,現在提出了很多高維空間索引結構和近似查詢的演演算法,k-d樹就是其中一種。
索引結構中相似性查詢有兩種基本的方式:一種是範圍查詢(range searches),另一種是K近鄰查詢(K-neighbor searches)。範圍查詢就是給定查詢點和查詢距離的閾值,從數據集中找出所有與查詢點距離小於閾值的數據;K近鄰查詢是給定查詢點及正整數K,從數據集中找到距離查詢點最近的K個數據,當K=1時,就是最近鄰查詢(nearest neighbor searches)。
特徵匹配運算元大致可以分為兩類。一類是線性掃描法,即將數據集中的點與查詢點逐一進行距離比較,也就是窮舉,缺點很明顯,就是沒有利用數據集本身蘊含的任何結構信息,搜索效率較低,第二類是建立數據索引,然後再進行快速匹配。因為實際數據一般都會呈現出簇狀的聚類形態,通過設計有效的索引結構可以大大加快檢索的速度。索引樹屬於第二類,其基本思想就是對搜索空間進行層次劃分。根據劃分的空間是否有混疊可以分為Clipping和Overlapping兩種。前者劃分空間沒有重疊,其代表就是k-d樹;後者劃分空間相互有交疊,其代表為R樹。(這裡只介紹k-d樹)
先以一個簡單直觀的實例來介紹k-d樹演演算法。假設有6個二維數據點{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},數據點位於二維空間內(如圖1中黑點所示)。k-d樹演演算法就是要確定圖1中這些分割空間的分割線(多維空間即為分割平面,一般為超平面)。下面就要通過一步步展示k-d樹是如何確定這些分割線的。
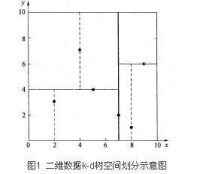
kd-tree
k-d樹是一個二叉樹,每個節點表示一個空間範圍。表1給出的是k-d樹每個節點中主要包含的數據結構。
表1 k-d樹中每個節點的數據類型
| 域名 | 數據類型 | 描述 |
| Node-data | 數據矢量 | 數據集中某個數據點,是n維矢量(這裡也就是k維) |
| Range | 空間矢量 | 該節點所代表的空間範圍 |
| split | 整數 | 垂直於分割超平面的方向軸序號 |
| Left | k-d樹 | 由位於該節點分割超平面左子空間內所有數據點所構成的k-d樹 |
| Right | k-d樹 | 由位於該節點分割超平面右子空間內所有數據點所構成的k-d樹 |
| parent | k-d樹 | 父節點 |
從上面對k-d樹節點的數據類型的描述可以看出構建k-d樹是一個逐級展開的遞歸過程。表2給出的是構建k-d樹的偽碼。
表2 構建k-d樹的偽碼
| 演演算法:構建k-d樹(createKDTree) |
| 輸入:數據點集Data-set和其所在的空間Range |
| 輸出:Kd,類型為k-d tree |
| 1.If Data-set為空,則返回空的k-d tree |
2.調用節點生成程序: (1)確定split域:對於所有描述子數據(特徵矢量),統計它們在每個維上的數據方差。以SURF特徵為例,描述子為64維,可計算64個方差。挑選出最大值,對應的維就是split域的值。數據方差大表明沿該坐標軸方向上的數據分散得比較開,在這個方向上進行數據分割有較好的解析度; (2)確定Node-data域:數據點集Data-set按其第split域的值排序。位於正中間的那個數據點被選為Node-data。此時新的Data-set' = Data-set\Node-data(除去其中Node-data這一點)。 |
3.dataleft = {d屬於Data-set' && d[split] ≤ Node-data[split]} Left_Range = {Range && dataleft} dataright = {d屬於Data-set' && d[split] > Node-data[split]} Right_Range = {Range && dataright} |
4.left = 由(dataleft,Left_Range)建立的k-d tree,即遞歸調用createKDTree(dataleft,Left_ Range)。並設置left的parent域為Kd; right = 由(dataright,Right_Range)建立的k-d tree,即調用createKDTree(dataright,Right_ Range)。並設置right的parent域為Kd。 |
以上述舉的實例來看,過程如下:
由於此例簡單,數據維度只有2維,所以可以簡單地給x,y兩個方向軸編號為0,1,也即split={0,1}。
(1)確定split域的首先該取的值。分別計算x,y方向上數據的方差得知x方向上的方差最大,所以split域值首先取0,也就是x軸方向;
(2)確定Node-data的域值。根據x軸方向的值2,5,9,4,8,7排序選出中值為7,所以Node-data = (7,2)。這樣,該節點的分割超平面就是通過(7,2)並垂直於split = 0(x軸)的直線x = 7;
(3)確定左子空間和右子空間。分割超平面x = 7將整個空間分為兩部分,如圖2所示。x < = 7的部分為左子空間,包含3個節點{(2,3),(5,4),(4,7)};另一部分為右子空間,包含2個節點{(9,6),(8,1)}。
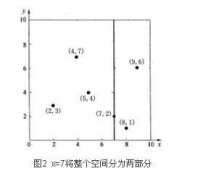
kd-tree
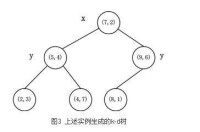
kd-tree
在k-d樹中進行數據的查找也是特徵匹配的重要環節,其目的是檢索在k-d樹中與查詢點距離最近的數據點。這裡先以一個簡單的實例來描述最鄰近查找的基本思路。
星號表示要查詢的點(2.1,3.1)。通過二叉搜索,順著搜索路徑很快就能找到最鄰近的近似點,也就是葉子節點(2,3)。而找到的葉子節點並不一定就是最鄰近的,最鄰近肯定距離查詢點更近,應該位於以查詢點為圓心且通過葉子節點的圓域內。為了找到真正的最近鄰,還需要進行'回溯'操作:演演算法沿搜索路徑反向查找是否有距離查詢點更近的數據點。此例中先從(7,2)點開始進行二叉查找,然後到達(5,4),最後到達(2,3),此時搜索路徑中的節點為<(7,2),(5,4),(2,3)>,首先以(2,3)作為當前最近鄰點,計算其到查詢點(2.1,3.1)的距離為0.1414,然後回溯到其父節點(5,4),並判斷在該父節點的其他子節點空間中是否有距離查詢點更近的數據點。以(2.1,3.1)為圓心,以0.1414為半徑畫圓,如圖4所示。發現該圓並不和超平面y = 4交割,因此不用進入(5,4)節點右子空間中去搜索。

kd-tree
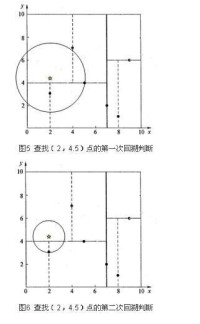
一個複雜點了例子如查找點為(2,4.5)。同樣先進行二叉查找,先從(7,2)查找到(5,4)節點,在進行查找時是由y = 4為分割超平面的,由於查找點為y值為4.5,因此進入右子空間查找到(4,7),形成搜索路徑<(7,2),(5,4),(4,7)>,取(4,7)為當前最近鄰點,計算其與目標查找點的距離為3.202。然後回溯到(5,4),計算其與查找點之間的距離為3.041。以(2,4.5)為圓心,以3.041為半徑作圓,如圖5所示。可見該圓和y = 4超平面交割,所以需要進入(5,4)左子空間進行查找。此時需將(2,3)節點加入搜索路徑中得<(7,2),(2,3)>。回溯至(2,3)葉子節點,(2,3)距離(2,4.5)比(5,4)要近,所以最近鄰點更新為(2,3),最近距離更新為1.5。回溯至(7,2),以(2,4.5)為圓心1.5為半徑作圓,並不和x = 7分割超平面交割,如圖6所示。至此,搜索路徑回溯完。返回最近鄰點(2,3),最近距離1.5。k-d樹查詢演演算法的偽代碼如下所示。
如果搜索到葉子節點,當前的葉子節點被設為最近鄰節點。
然後通過stack回溯:
如果當前點的距離比最近鄰點距離近,更新最近鄰節點.
然後檢查以最近距離為半徑的圓是否和父節點的超平面相交.
如果相交,則必須到父節點的另外一側,用同樣的DFS搜索法,開始檢查最近鄰節點。
如果不相交,則繼續往上回溯,而父節點的另一側子節點都被淘汰,不再考慮的範圍中.
當搜索回到root節點時,搜索完成,得到最近鄰節點。
kd-tree

基本信息
- 外文名
- k-dimensional樹