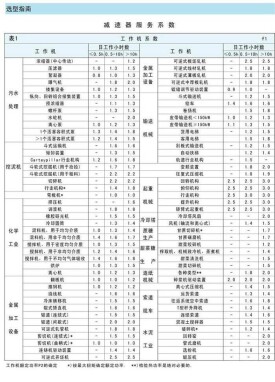
使用係數
使用係數
使用係數是設備的使用時間與允許使用時間的比值。通常以一年累積的時間為計算範圍。使用係數x年使用小時基數=年使用小時數。
例如,一台電機每天工作八小時,一年50周,那麼一年電機工作的時候是2000小時。如果電機是連續工作制,一年有約8760小時,這台電機的使用係數是2000/8760=22.83%。如果這台電機一年的允許工作時間是每年2000小時,它的使用係數就是100%。可見,是否合理的選擇基數,對使用係數是有影響的。
為縮短布爾函數系統混合極性Reed-Muller(mixed-polarity Reed-Muller,MPRM)電路面積優化過程的時間,提出了能在任意極性值的MPRM間進行極性轉換的係數矩陣變換方法。使用係數矩陣表示布爾函數系統,通過對係數矩陣進行分隔,使用置換和摺疊操作完成MPRM極性轉換以加快極性轉換速度;在此基礎上,給出了適用於較大規模MPRM電路的面積優化演演算法,其中使用遺傳演演算法進行極性空間搜索,並採用基於最短個體距離的適應度計算方法進一步縮短優化過程中的極性轉換時間。實驗結果表明,與其他MPRM極性轉換方法相比,此方法能夠提高 MPRM電路面積優化的速度。
1、單變數極性轉換:
通過分析當僅對變數 x的分解形式發生改變,即僅有變數 x的極性發生變化時(稱之為單變數極性轉換),為完成極性轉換係數向量所需的運算,推導出單變數極性轉換所需的係數矩陣變換。
下面以變數 x的極性由2變為1時,即 x 的極性發生變化前的 MPRM的極性值為 g、 p =2,變數 x的極性發生變化后得到的 MPRM的極性值為:
h、 p =p ( j≠ l), p =1為例進行分析。
2、MPRM極性轉換演演算法:
輸入:極性值g以及相應 MPRM的 係數矩陣 A ,極性值 h,變數個數 n。
輸出:極性值為h的 MPRM的係數矩陣 A
由於MPRM極性空間巨大,採用窮舉策略搜索極性空間將導致優化時間過長,儘管可以採用極性值的Gray碼順序對極性空間進行搜索來降低優化時間,但對於規模較大電路優化過程依然不能在合理的時間內完成。遺傳演演算法是基於自然選擇和遺傳原理的搜索演演算法,常用於解決各種優化問題,採用遺傳演演算法可以加快極性空間的 搜索,能夠在較短的時間內得到比較好的結果,並且優於爬山演演算法和模擬退火演演算法。
為進行MPRM電路面積優化,需要對MPRM電路進行面積評估。採用面積估算模型,即用MPRM中的pi-term數作為電路的估算面積,通過最小化MPRM中的pi-term數來實現面積優化。由於使用係數矩陣表示MPRM,MPRM中的pi-term數等於相應係數矩陣中on-set係數向量的個數,因此面積優化的目的是最小化係數矩陣中on-set係數向量的個數。
1、遺傳基因型和適應度函數:
為了簡化編碼問題,方便實現交叉、變異等遺傳操作,採用極性向量來表現個體的遺傳基因型。解碼工作,即遺傳基因型(極性向量)向表現型(MPRM)的映射使用給出的基於係數矩陣變換的MPRM極性轉換演演算法完成。
遺傳演演算法在演化過程中僅以適應度函數為依據,利用種群中每個個體的適應度值來進行搜索,因此適應度函數應該能夠反映個體的優劣程度。將MPRM中的pi-term數(即係數矩陣中on-set係數向量的個數)作為適應度函數,適應度值越小,則表示個體越優。在計算個體適應度時,先完成解碼工作,即極性轉換工作,然後再統計 MPRM中 pi-term的個數。
2、遺傳基本操作:
為了使種群能夠進化,需要進行選擇、交叉、變異和替換等操作.採用錦標賽選擇方法,隨機地從種群中挑選一定數量的體,並從中選取具有最小適應度的個體作為進行後續操作的父個體,錦標賽選擇的參數為錦標賽規 模。為了在演演算法收斂效果和時間之間進行折中,還設置了控制種群進化時生成新個體數量的選擇次數參數。
交叉操作採用單點交叉,對2所選擇的父個體,隨機生成交叉位置完成個體的交叉生成子個體。變異操作採用均勻變異,隨機地改變一個基因位。
3、MPRM電路面積優化演演算法描述:
將所給出的基於係數矩陣變換的MPRM極性轉換演演算法與遺傳演演算法相結合,給出了能夠適用於較大規模 MPRM電路的面積優化演演算法,演演算法描述如下:
Step1、讀取網表文件。
Step2、設定參數:種群規模,錦標賽規模,最大迭代次數,選擇次數。
Step3、隨機生成初始種群,使用基於最短個體距離的適應度計算方法計算初始種群中個體的適應度。
Step4、演化代數賦0值。
Step5、根據選擇次數參數使用錦標賽選擇方法選擇父個體。
Step6、完成父個體對的交叉操作生成子個體。
Step7、對新生成的子個體進行變異。
Step8、使用基於最短個體距離的適應度計算方法計算變異后的子個體的適應度。
Step9、使用沒有重複的穩態替換策略進行替換生成新種群。
Step10、演化代數 +1,如果演化代數大於最大迭代次數,則轉Step11;否則轉Step5。
Step11、輸出面積最優MPRM結果;演演算法結束。
該演演算法的時間複雜度與演演算法參數、所使用的遺傳基本操作及適應度的計算有關,主要由適應度計算的時間複雜度決定,而適應度計算的時間複雜度則由極性轉換的時間複雜度決定。因此,演演算法的時間複雜度主要由MPRM極性轉換的時間複雜度決定。
抽油桿的疲勞破壞是抽油桿柱的主共失效形式之一。因此,抽油桿使用係數不僅影響抽油桿的安全程度,而且影響機抽米氣系統的可靠性和經濟性,故確定其值的大小是個非常重要的問題。一改過去傳統的經驗取值法,利用模糊理論,對影響抽油桿強度的係數— 抽油桿使用係數 (k )—進行了計算機模糊綜合評判。通過實例驗證,得到了切合實際的參數值,有效地提高了機抽系統的可靠性和經濟性,具有較好的實用價值和推廣價值。
所謂模糊,是指邊界不清楚,即在質上沒有確切的含義,又在量上沒有明確的界限。二級模糊綜合評判基本原理是,先把影響設計參數取值的每個模糊因素。按性質和程度細分為若干等級,並把每一因素及各個等級,均視為等級論域上的模糊子集,然後按各等級模糊子集進行一級模糊綜合評判,並將結果作為單因素評判集,在按所有因素進行二級模糊綜合評判。從而獲得確定設計變數的評判指標,最後得到合理的參數值。
影響抽油桿使用係數 ( k ) 的因素,對於不同的油田、不同的區域、不同的井、同一井在不同的開採時期,其因素級隸屬度 ( μ) 是不同的,必須具體問題具體分析。具體確定抽油桿使用係數 ( ks) 的大小。
( l) 確定各因素等級隸屬度 ( μ):
各因素等級隸屬度 ( μ) 通常是根據實際情況、概率統計和專家評判得出的。如對腐蝕程度這一因素,該機抽 井井液含有一定量的鹽水,但HS含量較低,所以由經驗得出,該井屬腐蝕不嚴重的概率為0,不太嚴重、一般、較嚴重和嚴重的概率分別為0.3、0.8、0.5、0.2,將各因素等級隸屬度 ( μ) 寫成矩陣形式。
(2 )確定備擇集:
k 的取值區間「 v , v ]= [ 0.5 , 0.9 〕,按等步長在區間內取一系列離散值,得備擇集 ( v ):
v= 「0.5,0.55 ,0.6 , … ,0.9 〕
(3 ) 一次模糊綜合評判:
①各因素等級評判集(R),
② 各因素等級權重集,將第i個因素的各等級隸屬度進行規一 化處理后,得到第i個因素的等級權重集 ( w) 。
③ 一級模糊綜合評判矩陣 ( A ),
(4 ) 二級模糊綜合評判:
① 各因素權重集( w ) w= [ 0.07、 0.06、 0.07、0.055、0.05、0.055、0.12、 0.11、 0.08、0.09、0.08 0.07 ]
② 二級模糊綜合評判集B = w· A
( 5 ) k 值的確定
通過計算,得出二級模糊綜合評判集,那麼根據實際情況不同,採用最大隸屬度法或加權平均法即可得到抽油桿使用係數( k)。
① 最大隸屬度法 k= v = 0.535
② 加權平均法 k=v=0.708
用模糊綜合決策評判抽油桿使用係數 ( k ),綜合考慮了影響實際機抽系統的諸多模糊因素。如井下環境、抽 油桿質量等,並對其進行了定量化處理,與過去單憑經驗直接在某個範圍內確定參數值大小相比,獲得的抽油桿使用係數 ( k ) 更為準確、可靠,提高了機抽系統的可靠性和經濟性。
根據不同的實際情況,確立相應的模糊因素、因素隸屬度和因素權重等,可得到不同的參數值。
整個評判過程通過編程在計算機上實現,快速、簡單、方便,適用於各類有桿抽油系統。
基本信息
- 中文名
- 使用係數
- 外文名
- Use (or utilization) factor
- 一年電機工作
- 2000小時
- 使用係數
- 2000/2000=100%