原子操作
不會被線程調度機制打斷的操作
"原子操作”(atomic operation)是不需要synchronized,這是多線程編程的老生常談了。所謂原子操作是指不會被線程調度機制打斷的操作。這種操作一旦開始,就一直運行到結束,中間不會有任何 context switch (切換到另一個線程)。
如果這個操作所處的層(layer)的更高層不能發現其內部實現與結構,那麼這個操作是一個原子(atomic)操作。
原子操作可以是一個步驟,也可以是多個操作步驟,但是其順序不可以被打亂,也不可以被切割而只執行其中的一部分。
將整個操作視作一個整體是原子性的核心特徵。
在多進程(線程)訪問共享資源時,能夠確保所有其他的進程(線程)都不在同一時間內訪問相同的資源。原子操作(atomic operation)是不需要synchronized,這是Java多線程編程的老生常談了。所謂原子操作是指不會被線程調度機制打斷的操作;這種操作一旦開始,就一直運行到結束,中間不會有任何 context switch (切換到另一個線程)。通常所說的原子操作包括對非long和double型的primitive進行賦值,以及返回這兩者之外的primitive。之所以要把它們排除在外是因為它們都比較大,而JVM的設計規範又沒有要求讀操作和賦值操作必須是原子操作(JVM可以試著去這麼作,但並不保證)。
首先處理器會自動保證基本的內存操作的原子性。處理器保證從系統內存當中讀取或者寫入一個位元組是原子的,意思是當一個處理器讀取一個位元組時,其他處理器不能訪問這個位元組的內存地址。奔騰6和最新的處理器能自動保證單處理器對同一個緩存行里進行16/32/64位的操作是原子的,但是複雜的內存操作處理器不能自動保證其原子性,比如跨匯流排寬度,跨多個緩存行,跨頁表的訪問。但是處理器提供匯流排鎖定和緩存鎖定兩個機制來保證複雜內存操作的原子性。
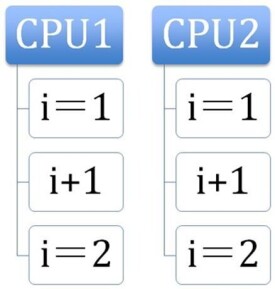
原子操作是不可分割的,在執行完畢之前不會被任何其它任務或事件中斷。在單處理器系統(UniProcessor)中,能夠在單條指令中完成的操作都可以認為是" 原子操作",因為中斷只能發生於指令之間。這也是某些CPU指令系統中引入了test_and_set、test_and_clear等指令用於臨界資源互斥的原因。但是,在對稱多處理器(Symmetric Multi-Processor)結構中就不同了,由於系統中有多個處理器在獨立地運行,即使能在單條指令中完成的操作也有可能受到干擾。我們以decl (遞減指令)為例,這是一個典型的"讀-改-寫"過程,涉及兩次內存訪問。設想在不同CPU運行的兩個進程都在遞減某個計數值,可能發生的情況是:
⒈ CPU A(CPU A上所運行的進程,以下同)從內存單元把當前計數值⑵裝載進它的寄存器中;
⒉ CPU B從內存單元把當前計數值⑵裝載進它的寄存器中。
⒊ CPU A在它的寄存器中將計數值遞減為1;
⒋ CPU B在它的寄存器中將計數值遞減為1;
⒌ CPU A把修改後的計數值⑴寫回內存單元。
⒍ CPU B把修改後的計數值⑴寫回內存單元。
我們看到,內存里的計數值應該是0,然而它卻是1。如果該計數值是一個共享資源的引用計數,每個進程都在遞減后把該值與0進行比較,從而確定是否需要釋放該共享資源。這時,兩個進程都去掉了對該共享資源的引用,但沒有一個進程能夠釋放它--兩個進程都推斷出:計數值是1,共享資源仍然在被使用。
原子操作
原子性不可能由軟體單獨保證--必須需要硬體的支持,因此是和架構相關的。在x86 平台上,CPU提供了在指令執行期間對匯流排加鎖的手段。CPU晶元上有一條引線#HLOCK pin,如果彙編語言的程序中在一條指令前面加上前綴"LOCK",經過彙編以後的機器代碼就使CPU在執行這條指令的時候把#HLOCK pin的電位拉低,持續到這條指令結束時放開,從而把匯流排鎖住,這樣同一匯流排上別的CPU就暫時不能通過匯流排訪問內存了,保證了這條指令在多處理器環境中的原子性。
原子操作大部分使用彙編語言實現,因為c語言並不能實現這樣的操作。
* 在x86的原子操作實現代碼中,定義了LOCK宏,這個宏可以放在隨後的內聯彙編指令之前。如果是SMP,LOCK宏被擴展為lock指令;否則被定義為空 -- 單CPU無需防止其它CPU的干擾,鎖內存匯流排完全是在浪費時間。
#ifdef CONFIG_SMP
#define LOCK "lock ; "
#else
#define LOCK ""
#endif
* typedef struct { volatile int counter; } atomic_t;
在所有支持的體系結構上原子類型atomic_t都保存一個int值。在x86的某些處理器上,由於工作方式的原因,原子類型能夠保證的可用範圍只有24位。volatile是一個類型描述符,要求編譯器不要對其描述的對象作優化處理,對它的讀寫都需要從內存中訪問。
* #define ATOMIC_INIT(i) { (i) }
用於在定義原子變數時,初始化為指定的值。如:
static atomic_t count = ATOMIC_INIT⑴;
* static __inline__ void atomic_add(int i,atomic_t *v)
將v指向的原子變數加上i。該函數不關心原子變數的新值,返回void類型。
在下面的實現中,使用了帶有C/C++表達式的內聯彙編代碼,格式如下(參考《AT&T ASM Syntax》):
__asm__ __volatile__("Instruction List" : Output : Input : Clobber/Modify);
__asm__ __volatile__指示編譯器原封不動保留表達式中的彙編指令系列,不要考慮優化處理。涉及的約束還包括:
⒈ 等號約束(=):只能用於輸出操作表達式約束,說明括弧內的左值表達式v->counter是write-only的。
⒉ 內存約束(m):表示使用不需要藉助寄存器,直接使用內存方式進行輸入或輸出。
⒊立即數約束(i):表示輸入表達式是一個立即數(整數),不需要藉助任何寄存器。
⒋ 寄存器約束(r):表示使用一個通用寄存器,由GCC在%eax/%ax/%al、%ebx/%bx/%bl、%ecx/%cx/%cl和%edx/%dx/%dl中選取一個合適的。
{
__asm__ __volatile__(
LOCK "addl %1,%0"
:"=m" (v->counter)
:"ir" (i),"m" (v->counter));
}
* static __inline__ int atomic_sub_and_test(int i,atomic_t *v)
從v 指向的原子變數減去i,並測試是否為0。若為0,返回真,否則返回假。由於x86的subl指令會在結果為0時設置CPU的zero標誌位,而且這個標誌位是CPU私有的,不會被其它CPU影響。因此,可以執行一次加鎖的減操作,再根據CPU的zero標誌位來設置本地變數c,並相應返回。
{
__asm__ __volatile__(
LOCK "subl %2,%0; sete %1"
:"=m" (v->counter),"=qm" (c)
:"ir" (i),"m" (v->counter) : "memory");
return c;
}
#define atomic_read(v) ((v)->counter)
讀取v指向的原子變數的值。
#define atomic_set(v,i) (((v)->counter) = (i))
設置v指向的原子變數的值為i。
static __inline__ void atomic_sub(int i,atomic_t *v)
從v指向的原子變數減去i。
static __inline__ void atomic_inc(atomic_t *v)
遞增v指向的原子變數。
static __inline__ void atomic_dec(atomic_t *v)
遞減v指向的原子變數。
static __inline__ int atomic_dec_and_test(atomic_t *v)
遞減v指向的原子變數,並測試是否為0。若為0,返回真,否則返回假。
static __inline__ int atomic_inc_and_test(atomic_t *v)
遞增v指向的原子變數,並測試是否為0。若為0,返回真,否則返回假。
static __inline__ int atomic_add_negative(int i,atomic_t *v)
將v指向的原子變數加上i,並測試結果是否為負。若為負,返回真,否則返回假。這個操作用於實現semaphore。