共找到2條詞條名為進程調度的結果 展開
- 進程調度
- 低級調度
進程調度
進程調度
無論是在批處理系統還是分時系統中,用戶進程數一般都多於處理機數、這將導致它們互相爭奪處理機。另外,系統進程也同樣需要使用處理機。這就要求進程調度程序按一定的策略,動態地把處理機分配給處於就緒隊列中的某一個進程,以使之執行。
1.多態性 從誕生、運行,直至消滅。
進程調度
3.三種基本狀態 它們之間可進行轉換
4.併發性併發執行的進程輪流佔用處理器
高級、中級和低級調度作業從提交開始直到完成,往往要經歷下述三級調度:
高級調度:(High-Level Scheduling)又稱為作業調度,它決定把後備作業調入內存運行;
低級調度:(Low-Level Scheduling)又稱為進程調度,它決定把就緒隊列的某進程獲得CPU;
中級調度:(Intermediate-Level Scheduling)又稱為在虛擬存儲器中引入,在內、外存對換區進行進程對換。
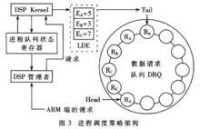
進程調度
某事件而阻塞時,才把處理機分配給另一個進程。
當一個進程正在運行時,系統可以基於某種原則,剝奪已分配給它的處理機,將之分配給其它進程。剝奪原則有:優先權原則、短進程優先原則、時間片原則。
例如,有三個進程P1、P2、P3先後到達,它們分別需要20、4和2個單位時間運行完畢。
假如它們就按P1、P2、P3的順序執行,且不可剝奪,則三進程各自的周轉時間分別為20、24、
26個單位時間,平均周轉時間是23.33個時間單位。
假如用時間片原則的剝奪調度方式,可得到:
可見:P1、P2、P3的周轉時間分別為26、10、6個單位時間(假設時間片為2個單位時間),平均周轉時間為14個單位時間。
衡量進程調度性能的指標有:周轉時間、響應時間、CPU-I/O執行期。
實時系統與其他操作系統不同在於計算機要能及時響應外
進程調度
1.基於優先順序的進程調度
最簡單最直觀的進程調度策略是基於優先順序的調度,多數實時系統採用基於優先順序的調度,每個進程根據它重要程度的不同被賦予不同的優先順序,調度器在每次調度時,總選擇優先順序最高的進程開始執行。首先要考慮的問題是如何分配優先順序,對於進程優先順序的分配可以採用靜態和動態兩種方式,靜態優先順序調度演演算法:這種調度演演算法給那些系統中得到運行的所有進程都靜態地分配一個優先順序。靜態優先順序的分配可以根據應用的屬性來進行,比如進程的周期,用戶優先順序,或者其它的預先確定的策略。單調率演演算法(RM)調度演演算法是一種典型的靜態優先順序調度演演算法,它根據進程的執行周期的長短來決定調度優先順序,那些具有小的執行周期的進程具有較高的優先順序。動態優先順序調度演演算法:這種調度演演算法根據進程的資源需求來動態地分配進程的優先順序,其目的就是在資源分配和調度時有更大的靈活性。在實時系統中,最早期限優先演演算法(EDF)演演算法是使用最多的一種動態優先順序調度演演算法,該演演算法給就緒隊列中的各個進程根據它們的截止期限(Deadline)來分配優先順序,具有最近的截止期限的進程具有最高的優先順序。分配好優先順序之後下一個要考慮的問題是何時讓高優先順序進程掌握CPU的使用權,這取決於操作系統的內核,有不可搶佔式和可搶佔式兩種。不可搶佔式內核要求每個進程自我放棄CPU的所有權,各個進程彼此合作共享一個CPU.非同步事件還是由中斷服務來處理。中斷服務可以使一個高優先順序的進程由掛起狀態變為就緒狀態。但中斷服務以後控制權還是回到原來被中斷了的那個進程,直到該進程主動放棄CPU的使用權時,那個高優先順序的進程才能獲得CPU的使用權。這就出現了響應時間的問題,高優先順序的進程已經進入了就緒狀態但不能執行,這樣進程的響應時間變得不再確定這與實時系統的要求不符,因此一般的實時操作系統都要求是可搶佔式的內核,當一個運行著的進程使一個比它優先順序高的進程進入了就緒態,當前進程的CPU使用權就被剝奪了,或者說被掛起了,那個高優先順序的進程立刻得到了CPU的控制權,如果是中斷服務子程序使一個高優先順序的進程進入就緒態,中斷完成時,中斷了的進程被掛起,優先順序高的那個進程開始運行。在這種內核設置下,多個進程可能處於併發的狀態,這就出現了多個進程
進程調度
2.基於比例共享的進程調度
雖然基於優先順序的調度簡單而且易於實現,是目前使用最廣泛的實時系統的進程調度策略,但對於一些軟實時系統而言這種方法不再適用,比如實時多媒體會議,在這種情況下我們可以選擇基於共享的進程調度演演算法,其基本思想就是按照一定的權重(比例)對一組需要調度的進程進行調度,讓它們的執行時間與它們的權重完全成正比。我們可以通過兩種方法來實現比例共享調度演演算法:第一種方法是調節各個就緒進程出現在調度隊列隊首的頻率,並調度隊首的進程執行;第二種做法就是逐次調度就緒隊列中的各個進程投入運行,但根據分配的權重調節分配個每個進程的運行時間片。比例共享調度演演算法的一個問題就是它沒有定義任何優先順序的概念;所有的進程都根據它們申請的比例共享CPU資源,當系統處於過載狀態時,所有的進程的執行都會按比例地變慢。所以為了保證系統中實時進程能夠獲得一定的CPU處理時間,一般採用一種動態調節進程權重的方法.
3. 基於時間的進程調度
對於那些具有穩定,已知輸入的簡單系統,可以使用時間驅動的調度演演算法,它能夠為數據處理提供很好的預測性。這種調度演演算法本質上是一種設計時就確定下來的離線的靜態調度方法。在系統的設計階段,在明確系統中所有的處理情況下,對於各個進程的開始,切換,以及結束時間等就事先做出明確的安排和設計。這種調度演演算法適合於那些很小的嵌入式系統,自控系統,感測器等應用環境。這種調度演演算法的優點是進程的執行有很好的可預測性,但最大的缺點是缺乏靈活性,並且會出現有進程需要被執行而 CPU 卻保持空閑的情況。對於不同要求下的實時系統可以採用不同的進程調度策略來進行設計,也可以將這些方法進行綜合之後得到更適合的調度策略.
一、進程調度依據
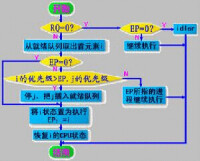
進程調度
Linux用函數goodness()來衡量一個處於可運行狀態的進程值得運行的程度。該函數綜合了以上提到的四項,還結合了一些其他的因素,給每個處於可運行狀態的進程賦予一個權值(weight),調度程序以這個權值作為選擇進程的唯一依據。關於goodness()的情況在後面將會詳細分析。
二、linux內核的三種調度方法:
1,SCHED_OTHER 分時調度策略,
2,SCHED_FIFO實時調度策略,先到先服務
3,SCHED_RR實時調度策略,時間片輪轉
實時進程將得到優先調用,實時進程根據實時優先順序決定調度權值,分時進程則通過nice和counter值決定權值,nice越小,counter越大,被調度的概率越大,也就是曾經使用了cpu最少的進程將會得到優先調度。
SHCED_RR和SCHED_FIFO的不同:
當採用SHCED_RR策略的進程的時間片用完,系統將重新分配時間片,並置於就緒隊列尾。放在隊列尾保證了所有具有相同優先順序的RR任務的調度公平。
SCHED_FIFO一旦佔用cpu則一直運行。一直運行直到有更高優先順序任務到達或自己放棄。
如果有相同優先順序的實時進程(根據優先順序計算的調度權值是一樣的)已經準備好,FIFO時必須等待該進程主動放棄后才可以運行這個優先順序相同的任務。而RR可以讓每個任務都執行一段時間。
相同點:
RR和FIFO都只用於實時任務。
創建時優先順序大於0(1-99)。
按照可搶佔優先順序調度演演算法進行。
就緒態的實時任務立即搶佔非實時任務。
所有任務都採用linux分時調度策略時。
1,創建任務指定採用分時調度策略,並指定優先順序nice值(-20~19)。
2,將根據每個任務的nice值確定在cpu上的執行時間(counter)。
3,如果沒有等待資源,則將該任務加入到就緒隊列中。
4,調度程序遍歷就緒隊列中的任務,通過對每個任務動態優先順序的計算(counter+20-nice)結果,選擇計算結果最大的一個去運行,當這個時間片用完后(counter減至0)或者主動放棄cpu時,該任務將被放在就緒隊列末尾(時間片用完)或等待隊列(因等待資源而放棄cpu)中。
5,此時調度程序重複上面計算過程,轉到第4步。
6,當調度程序發現所有就緒任務計算所得的權值都為不大於0時,重複第2步。
所有任務都採用FIFO時,
1,創建進程時指定採用FIFO,並設置實時優先順序rt_priority(1-99)。
2,如果沒有等待資源,則將該任務加入到就緒隊列中。
3,調度程序遍歷就緒隊列,根據實時優先順序計算調度權值(1000+rt_priority),選擇權值最高的任務使用cpu,該FIFO任務將一直佔有cpu直到有優先順序更高的任務就緒(即使優先順序相同也不行)或者主動放棄(等待資源)。
4,調度程序發現有優先順序更高的任務到達(高優先順序任務可能被中斷或定時器任務喚醒,再或被當前運行的任務喚醒,等等),則調度程序立即在當前任務堆棧中保存當前cpu寄存器的所有數據,重新從高優先順序任務的堆棧中載入寄存器數據到cpu,此時高優先順序的任務開始運行。重複第3步。
5,如果當前任務因等待資源而主動放棄cpu使用權,則該任務將從就緒隊列中刪除,加入等待隊列,此時重複第3步。
所有任務都採用RR調度策略時
1,創建任務時指定調度參數為RR,並設置任務的實時優先順序和nice值(nice值將會轉換為該任務的時間片的長度)。
2,如果沒有等待資源,則將該任務加入到就緒隊列中。
3,調度程序遍歷就緒隊列,根據實時優先順序計算調度權值(1000+rt_priority),選擇權值最高的任務使用cpu。
4,如果就緒隊列中的RR任務時間片為0,則會根據nice值設置該任務的時間片,同時將該任務放入就緒隊列的末尾。重複步驟3。
5,當前任務由於等待資源而主動退出cpu,則其加入等待隊列中。重複步驟3。
系統中既有分時調度,又有時間片輪轉調度和先進先出調度
1,RR調度和FIFO調度的進程屬於實時進程,以分時調度的進程是非實時進程。
2,當實時進程準備就緒后,如果當前cpu正在運行非實時進程,則實時進程立即搶佔非實時進程。
3,RR進程和FIFO進程都採用實時優先順序做為調度的權值標準,RR是FIFO的一個延伸。FIFO時,如果兩個進程的優先順序一樣,則這兩個優先順序一樣的進程具體執行哪一個是由其在隊列中的未知決定的,這樣導致一些不公正性(優先順序是一樣的,為什麼要讓你一直運行?),如果將兩個優先順序一樣的任務的調度策略都設為RR,則保證了這兩個任務可以循環執行,保證了公平。
三、進程調度策略
調度程序運行時,要在所有處於可運行狀態的進程之中選擇最值得運行的進程投入運行。選擇進程的依據是什麼呢?在每個進程的task_struct 結構中有這麼四項:
policy, priority , counter, rt_priority
這四項就是調度程序選擇進程的依據。其中,policy是進程的調度策略,用來區分兩種進程-實時和普通;priority是進程(實時和普通)的優先順序;counter 是進程剩餘的時間片,它的大小完全由priority決定;rt_priority是實時優先順序,這是實時進程所特有的,用於實時進程間的選擇。
首先,Linux 根據policy從整體上區分實時進程和普通進程,因為實時進程和普通進程度調度是不同的,它們兩者之間,實時進程應該先於普通進程而運行,然後,對於同一類型的不同進程,採用不同的標準來選擇進程:
對於普通進程,Linux採用動態優先調度,選擇進程的依據就是進程counter的大小。進程創建時,優先順序priority被賦一個初值,一般為0~70之間的數字,這個數字同時也是計數器counter的初值,就是說進程創建時兩者是相等的。字面上看,priority是“優先順序”、counter是“計數器”的意思,然而實際上,它們表達的是同一個意思-進程的“時間片”。Priority代表分配給該進程的時間片,counter表示該進程剩餘的時間片。在進程運行過程中,counter不斷減少,而priority保持不變,以便在counter變為0的時候(該進程用完了所分配的時間片)對counter重新賦值。當一個普通進程的時間片用完以後,並不馬上用priority對counter進行賦值,只有所有處於可運行狀態的普通進程的時間片(p->;;counter==0)都用完了以後,才用priority對counter重新賦值,這個普通進程才有了再次被調度的機會。這說明,普通進程運行過程中,counter的減小給了其它進程得以運行的機會,直至counter減為0時才完全放棄對CPU的使用,這就相對於優先順序在動態變化,所以稱之為動態優先調度。至於時間片這個概念,和其他不同操作系統一樣的,Linux的時間單位也是“時鐘滴答”,只是不同操作系統對一個時鐘滴答的定義不同而已(Linux為10ms)。進程的時間片就是指多少個時鐘滴答,比如,若priority為20,則分配給該進程的時間片就為20個時鐘滴答,也就是20*10ms=200ms。Linux中某個進程的調度策略(policy)、優先順序(priority)等可以作為參數由用戶自己決定,具有相當的靈活性。內核創建新進程時分配給進程的時間片預設為200ms(更準確的,應為210ms),用戶可以通過系統調用改變它。
對於實時進程,Linux採用了兩種調度策略,即FIFO(先來先服務調度)和RR(時間片輪轉調度)。因為實時進程具有一定程度的緊迫性,所以衡量一個實時進程是否應該運行,Linux採用了一個比較固定的標準。實時進程的counter只是用來表示該進程的剩餘時間片,並不作為衡量它是否值得運行的標準。實時進程的counter只是用來表示該進程的剩餘時間片,並不作為衡量它是否值得運行的標準,這和普通進程是有區別的。上面已經看到,每個進程有兩個優先順序,實時優先順序就是用來衡量實時進程是否值得運行的。
這一切看來比較麻煩,但實際上Linux中的實現相當簡單。Linux用函數goodness()來衡量一個處於可運行狀態的進程值得運行的程度。
Linux根據policy的值將進程總體上分為實時進程和普通進程,提供了三種調度演演算法:一種傳統的Unix調度程序和兩個由POSIX.1b(原名為POSIX.4)操作系統標準所規定的“實時”調度程序。但這種實時只是軟實時,不滿足諸如中斷等待時間等硬實時要求,只是保證了當實時進程需要時一定只把CPU分配給實時進程。
非實時進程有兩種優先順序,一種是靜態優先順序,另一種是動態優先順序。實時進程又增加了第三種優先順序,實時優先順序。優先順序是一些簡單的整數,為了決定應該允許哪一個進程使用CPU的資源,用優先順序代表相對權值-優先順序越高,它得到CPU時間的機會也就越大。
?靜態優先順序(priority)-不隨時間而改變,只能由用戶進行修改。它指明了在被迫和其他進程競爭CPU之前,該進程所應該被允許的時間片的最大值(但很可能的,在該時間片耗盡之前,進程就被迫交出了CPU)。
?動態優先順序(counter)-只要進程擁有CPU,它就隨著時間不斷減小;當它小於0時,標記進程重新調度。它指明了在這個時間片中所剩餘的時間量。
?實時優先順序(rt_priority)-指明這個進程自動把CPU交給哪一個其他進程;較高權值的進程總是優先於較低權值的進程。如果一個進程不是實時進程,其優先順序就是0,所以實時進程總是優先於非實時進程的(但實際上,實時進程也會主動放棄CPU)。
當policy分別為以下值時:
1) SCHED_OTHER:這是普通的用戶進程,進程的預設類型,採用動態優先調度策略,選擇進程的依據主要是根據進程goodness值的大小。這種進程在運行時,可以被高goodness值的進程搶先。
2) SCHED_FIFO:這是一種實時進程,遵守POSIX1.b標準的FIFO(先入先出)調度規則。它會一直運行,直到有一個進程因I/O阻塞,或者主動釋放CPU,或者是CPU被另一個具有更高rt_priority的實時進程搶先。在Linux實現中,SCHED_FIFO進程仍然擁有時間片-只有當時間片用完時它們才被迫釋放CPU。因此,如同POSIX1.b一樣,這樣的進程就象沒有時間片(不是採用分時)一樣運行。Linux中進程仍然保持對其時間片的記錄(不修改counter)主要是為了實現的方便,同時避免在調度代碼的關鍵路徑上出現條件判斷語句 if (!(current->;;policy&;;SCHED_FIFO)){...}-要知道,其他大量非FIFO進程都需要記錄時間片,這種多餘的檢測只會浪費CPU資源。(一種優化措施,不該將執行時間佔10%的代碼的運行時間減少到50%;而是將執行時間佔90%的代碼的運行時間減少到95%。0.9+0.1*0.5=0.95>;;0.1+0.9*0.9=0.91)
3) SCHED_RR:這也是一種實時進程,遵守POSIX1.b標準的RR(循環round-robin)調度規則。除了時間片有些不同外,這種策略與SCHED_FIFO類似。當SCHED_RR進程的時間片用完后,就被放到SCHED_FIFO和SCHED_RR隊列的末尾。
只要系統中有一個實時進程在運行,則任何SCHED_OTHER進程都不能在任何CPU運行。每個實時進程有一個rt_priority,因此,可以按照rt_priority在所有SCHED_RR進程之間分配CPU。其作用與SCHED_OTHER進程的priority作用一樣。只有root用戶能夠用系統調用sched_setscheduler,來改變當前進程的類型(sys_nice,sys_setpriority)。
此外,內核還定義了SCHED_YIELD,這並不是一種調度策略,而是截取調度策略的一個附加位。如同前面說明的一樣,如果有其他進程需要CPU,它就提示調度程序釋放CPU。特別要注意的就是這甚至會引起實時進程把CPU釋放給非實時進程。
四、主要的進程調度的函數分析
真正執行調度的函數是schedule(void),它選擇一個最合適的進程執行,並且真正進行上下文切換,使得選中的進程得以執行。而reschedule_idle(struct task_struct *p)的作用是為進程選擇一個合適的CPU來執行,如果它選中了某個CPU,則將該CPU上當前運行進程的need_resched標誌置為1,然後向它發出一個重新調度的處理機間中斷,使得選中的CPU能夠在中斷處理返回時執行schedule函數,真正調度進程p在CPU上執行。在schedule()和reschedule_idle()中調用了goodness()函數。goodness()函數用來衡量一個處於可運行狀態的進程值得運行的程度。此外,在schedule()函數中還調用了schedule_tail()函數;在reschedule_idle()函數中還調用了reschedule_idle_slow()。這些函數的實現對理解SMP的調度非常重要,下面一一分析這些函數。先給出每個函數的主要流程圖,然後給出源代碼,並加註釋。
goodness()函數分析
goodness()函數計算一個處於可運行狀態的進程值得運行的程度。一個任務的goodness是以下因素的函數:正在運行的任務、想要運行的任務、當前的CPU。goodness返回下面兩類值中的一個:1000以下或者1000以上。1000或者1000以上的值只能賦給“實時”進程,從0到999的值只能賦給普通進程。實際上,在單處理器情況下,普通進程的goodness值只使用這個範圍底部的一部分,從0到41。在SMP情況下,SMP模式會優先照顧等待同一個處理器的進程。不過,不管是UP還是SMP,實時進程的goodness值的範圍是從1001到1099。
goodness()函數其實是不會返回-1000的,也不會返回其他負值。由於idle進程的counter值為負,所以如果使用idle進程作為參數調用goodness,就會返回負值,但這是不會發生的。
goodness()是個簡單的函數,但是它是linux調度程序不可缺少的部分。運行隊列中的每個進程每次執行schedule時都要調度它,因此它的執行速度必須很快。
//在/kernel/sched.c中
static inline int goodness(struct task_struct * p, int this_cpu, struct mm_struct *this_mm)
{ int weight;
if (p->;;policy != SCHED_OTHER) {
weight = 1000 + p->;;rt_priority;
goto out;
}
weight = p->;;counter;
if (!weight)
goto out;
#ifdef __SMP__
if (p->;;processor == this_cpu)
weight += PROC_CHANGE_PENALTY;
#endif
if (p->;;mm == this_mm)
weight += 1;
weight += p->;;priority;
out:
return weight;
}
schedule()函數分析
schedule()函數的作用是,選擇一個合適的進程在CPU上執行,它僅僅根據'goodness'來工作。對於SMP情況,除了計算每個進程的加權平均運行時間外,其他與SMP相關的部分主要由goodness()函數來體現。
流程:
①將prev和next設置為schedule最感興趣的兩個進程:其中一個是在調用schedule時正在運行的進程(prev),另外一個應該是接著就給予CPU的進程(next)。注意:prev和next可能是相同的-schedule可以重新調度已經獲得cpu的進程.
②中斷處理程序運行“下半部分”.
③內核實時系統部分的實現,循環調度程序(SCHED_RR)通過移動“耗盡的”RR進程-已經用完其時間片的進程-到隊列末尾,這樣具有相同優先順序的其他RR進程就可以獲得CPU了。同時,這補充了耗盡進程的時間片。
④由於代碼的其他部分已經決定了進程必須被移進或移出TASK_RUNNING狀態,所以會經常使用schedule,例如,如果進程正在等待的硬體條件已經發生,所以如果必要,這個switch會改變進程的狀態。如果進程已經處於TASK_RUNNING狀態,它就無需處理了。如果它是可以中斷的(等待信號),並且信號已經到達了進程,就返回TASK_RUNNING狀態。在所以其他情況下(例如,進程已經處於TASK_UNINTERRUPTIBLE狀態了),應該從運行隊列中將進程移走。
⑤將p初始化為運行隊列的第一個任務;p會遍歷隊列中的所有任務。
⑥c記錄了運行隊列中所有進程最好的“goodness”-具有最好“goodness”的進程是最易獲得CPU的進程。goodness的值越高越好。
⑦遍歷執行任務鏈表,跟蹤具有最好goodness的進程。
⑧這個循環中只考慮了唯一一個可以調度的進程。在SMP模式下,只有任務不在cpu上運行時,即can_schedule宏返回為真時,才會考慮該任務。在UP情況下,can_schedule宏返回恆為真.
⑨如果循環結束后,得到c的值為0。說明運行隊列中的所有進程的goodness值都為0。goodness的值為0,意味著進程已經用完它的時間片,或者它已經明確說明要釋放CPU。在這種情況下,schedule要重新計算進程的counter;新counter的值是原來值的一半加上進程的靜態優先順序(priortiy),除非進程已經釋放CPU,否則原來counter的值為0。因此,schedule通常只是把counter初始化為靜態優先順序。(中斷處理程序和由另一個處理器引起的分支在schedule搜尋goodness最大值時都將增加此循環中的計數器,因此由於這個原因計數器可能不會為0。顯然,這很罕見。)在counter的值計算完成後,重新開始執行這個循環,找具有最大goodness的任務。
⑩如果schedule已經選擇了一個不同於前面正在執行的進程來調度,那麼就必須掛起原來的進程並允許新的進程運行。這時調用switch_to來進行切換。