列聯表
列聯表
列聯表(contingency table)是觀測數據按兩個或更多屬性(定性變數)分類時所列出的頻數表。它是由兩個以上的變數進行交叉分類的頻數分佈表。
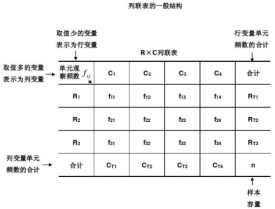
一般,若總體中的個體可按兩個屬性A與B分類,A有r個等級A1,A2,…,Ar,B有c個等級B1,B2,…,Bc,從總體中抽取大小為n的樣本,設其中有nij個個體的屬性屬於等級Ai和Bj,nij稱為頻數,將r×c個nij排列為一個r行c列的二維列聯表,簡稱r×c表。若所考慮的屬性多於兩個,也可按類似的方式作出列聯表,稱為多維列聯表。
列聯表又稱交互分類表,所謂交互分類,是指同時依據兩個變數的值,將所研究的個案分類。交互分類的目的是將兩變數分組,然後比較各組的分佈狀況,以尋找變數間的關係。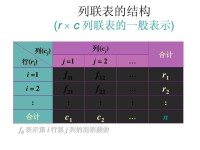
列聯表
特徵1
觀測數據按兩個或更多屬性(定性變數)分類時所列出的頻數表。例如,對隨機抽取的1000人按性別(男或女)及色覺(正常或色盲)兩個屬性分類,得到二行二列的列聯表(表1),又稱2×2表或四格表。
特徵2
一般,若總體中的個體可按兩個屬性A與B分類,A有r個等級A1,A2,…,Ar;B有с個等級B1,B2,…,Bc,從總體中抽取大小為n的樣本設其中有nij個屬於等級Ai和Bj,nij稱為頻數,將r×с個nij(i=1,2,…,r;j=1,2,…,с)排列為一個r行с列的二維列聯表(表2),簡稱r×с表。
特徵3
若所考慮的屬性多於兩個,也可按類似的方式作出列聯表,稱為多維列聯表。由於屬性或定性變數的取值是離散的,因此多維列聯表分析屬於離散多元分析的範疇,列聯表分析在應用統計,特別在醫學、生物學及社會科學中,有重要的應用。
列聯表分析的基本問題是,判明所考察的各屬性之間有無關聯,即是否獨立。如在前例中,問題是:一個人是否色盲與其性別是否有關?在r×с表中,若以pi·、p·j和pij分別表示總體中的個體屬於等級Ai,屬於等級Bj和同時屬於Ai、Bj的概率(pi·,p·j稱邊緣概率,pij稱格概率),“A、B兩屬性無關聯”的假設可以表述為H0:pij=pi·p·j,(i=1,2,…,r;j=1,2,…,с),未知參數pij、pi·、p·j的最大似然估計(見點估計)分別為行和及列和(統稱邊緣和)
為樣本大小。根據K.皮爾森(1904)的擬合優度檢驗或似然比檢驗(見假設檢驗),當h0成立,且一切pi·>0和p·j>0時,統計量
的漸近分佈是自由度為(r-1)(с-1)的Ⅹ分佈,式中Eij=ni·n·j/n稱為期望頻數。當n足夠大,且表中各格的Eij都不太小時,可以據此對h0作檢驗:若Ⅹ值足夠大,就拒絕假設h0,即認為A與B有關聯。在前面的色覺問題中,曾按此檢驗,判定出性別與色覺之間存在某種關聯。
需要注意
若樣本大小n不很大,則上述基於漸近分佈的方法就不適用。對此,在四格表情形,R.A.費希爾(1935)提出了一種適用於所有n的精確檢驗法。其思想是在固定各邊緣和的條件下,根據超幾何分佈(見概率分佈),可以計算觀測頻數出現任意一種特定排列的條件概率。把實際出現的觀測頻數排列,以及比它呈現更多關聯跡象的所有可能排列的條件概率都算出來並相加,若所得結果小於給定的顯著性水平,則判定所考慮的兩個屬性存在關聯,從而拒絕h0。
在判定變數之間存在關聯性后,可用多種定量指標來刻畫其關聯程度。例如,對一般的r×с表,可用列聯繫數表示之。
對一般的r×с表,特別是在多維表分析中,若無關聯性(即獨立性)的假設被拒絕,則通常還需要檢驗進一步的假設。例如對三維表,可能需要考慮一個變數是否與另外兩個變數獨立。對這類局部獨立性的檢驗仍可用大樣本的Ⅹ檢驗法。但是在多維情形,變數之間的關聯性可能相當複雜。許多假設,直接用格概率表示是不方便的。一種處理方法是仿照線性統計模型,將格概率(或期望頻數)的對數表示成各變數的主效應及各階交互效應等未知參數的線性形式。這種模型稱為對數線性模型,在此模型下,變數獨立性的假設等價於交互效應等於零的假設。此外,還可以利用對數線性模型,根據實際觀測頻數,對各種具體模型進行擬合,並對各未知參數進行估計。估計的方法一般採用最大似然方法。由於這一類似然方程的解常無顯式表示,通常需用迭代法求解,計算工作量很大。因此,多維列聯表分析只在近代高速電子計算機的使用日益普及的情況下,才得到較為充分的發展,逐漸達到可以實際應用的程度。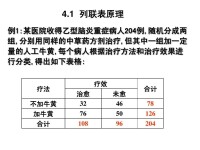
列聯表