GREP
文本搜索工具
grep(縮寫來自GloballysearchaRegularExpressionandPrint)是一種強大的文本搜索工具,它能使用特定模式匹配(包括正則表達式)搜索文本,並默認輸出匹配行。Unix的grep家族包括grep、egrep和fgrep。Windows系統下類似命令FINDSTR。
egrep和fgrep的命令只跟grep有很小不同。egrep和fgrep都是grep的擴展,支持更多的re元字元,fgrep就是fixedgrep或fastgrep,它們把所有的字母都看作單詞,也就是說,正則表達式中的元字元表示回其自身的字面意義,不再特殊。linux使用GNU版本的grep。它功能更強,可以通過-G、-E、-F命令行選項來使用egrep和fgrep的功能。
grep的工作方式是這樣的,它在一個或多個文件中搜索字元串模板。如果模板包括空格,則必須被引用,模板后的所有字元串被看作文件名。搜索的結果被送到屏幕,不影響原文件內容。
grep可用於shell腳本,因為grep通過返回一個狀態值來說明搜索的狀態,如果模板搜索成功,則返回0,如果搜索不成功,則返回1,如果搜索的文件不存在,則返回2。我們利用這些返回值就可進行一些自動化的文本處理工作。
Grep命令中允許指定的串語句是一個規則表達式,這是一種允許使用某些特殊鍵盤字元的指定字元串的方法,這種方法中的特殊鍵盤字元可以用於代表其他字元也可以進一步定義模式匹配工作方式。例如:grep".*hood"essay1。該命令將在文件essay1中搜索,顯示出包含帶有字元串hood的字的每一行。命令行中的點表示的是hood之前可以有任意字元,星號指的是在字元串之前點號所表示的任意字元可以有任意個(其中的雙引號是可有可無的,但是當語句中包含短語或者空格時就必須加雙引號)。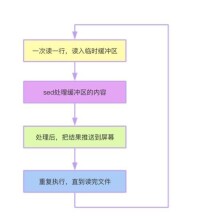
GREP
^
錨定行的開始如:'^grep'匹配所有以grep開頭的行。
$
錨定行的結束如:'grep$'匹配所有以grep結尾的行。
.
匹配一個非換行符('\n')的字元如:'gr.p'匹配gr後接一個任意字元,然後是p。
*
匹配零個或多個先前字元如:'*grep'(注意*前有空格)匹配所有零個或多個空格后緊跟grep的行,需要用egrep或者grep帶上-E選項。.*一起用代表任意字元。
[]
匹配一個指定範圍內的字元,如'[Gg]rep'匹配Grep和grep。
[^]
匹配一個不在指定範圍內的字元,如:'[^A-FH-Z]rep'匹配不包含A-F和H-Z的一個字母開頭,緊跟rep的行。
\(..\)
標記匹配字元,如'\(love\)',love被標記為1。
\<
錨定單詞的開始,如:'\
\>
錨定單詞的結束,如'grep\>'匹配包含以grep結尾的單詞的行。
x\{m\}
重複字元x,m次,如:'o\{5\}'匹配包含5個o的行。
x\{m,\}
重複字元x,至少m次,如:'o\{5,\}'匹配至少有5個o的行。
x\{m,n\}
重複字元x,至少m次,不多於n次,如:'o\{5,10\}'匹配5--10個o的行。
\w
匹配文字和數字字元,也就是[A-Za-z0-9],如:'G\w*p'匹配以G後跟零個或多個文字或數字字元,然後是p。
\W
\w的反置形式,匹配一個或多個非單詞字元,如點號句號等。
\b
單詞鎖定符,如:'\bgrep\b'只匹配grep。
用於egrep和grep-E的元字元擴展集
\+
匹配一個或多個先前的字元。如:'[a-z]\+able',匹配一個或多個小寫字母後跟able的串,如loveable,enable,disable等。
\?
匹配零個或一個先前的字元。如:'gr\?p'匹配gr後跟一個或沒有字元,然後是p的行。
a\|b\|c
匹配a或b或c。如:grep|sed匹配grep或sed
\(\)
分組符號,如:love\(ab\le\|rs\)ov\+匹配loveable或lovers,匹配一個或多個ov。
POSIX字元類
為了在不同國家的字元編碼中保持一至,POSIX(ThePortableOperatingSystemInterface)增加了特殊的字元類,如[:alnum:]是A-Za-z0-9的另一個寫法。要把它們放到[]號內才能成為正則表達式,如[A-Za-z0-9]或[[:alnum:]]。在linux下的grep除fgrep外,都支持POSIX的字元類。
GREP
[:alnum:]
文字數字字元
[:alpha:]
文字字元
[:digit:]
數字字元
[:graph:]
非空字元(非空格、控制字元)
[:lower:]
小寫字元
[:cntrl:]
控制字元
[:print:]
非空字元(包括空格)
[:punct:]
標點符號
[:space:]
所有空白字元(新行,空格,製表符)
[:upper:]
大寫字元
[:xdigit:]
十六進位數字(0-9,a-f,A-F)
-?
同時顯示匹配行上下的?行,如:grep-2patternfilename同時顯示匹配行的上下2行。
-a,--text
等價於匹配text,用於(Binaryfile(standardinput)matches)報錯
-b,--byte-offset
列印匹配行前面列印該行所在的塊號碼。
-c,--count
只列印匹配的行數,不顯示匹配的內容。
-fFile,--file=File
從文件中提取模板。空文件中包含0個模板,所以什麼都不匹配。
-h,--no-filename
當搜索多個文件時,不顯示匹配文件名前綴。
-i,--ignore-case
忽略大小寫差別。
-o,--only-matching
只顯示正則表達式匹配的部分。(showonlythepartofalinematchingPATTERN)
-q,--quiet
取消顯示,只返回退出狀態。0則表示找到了匹配的行。
-l,--files-with-matches
列印匹配模板的文件清單。
-L,--files-without-match
列印不匹配模板的文件清單。
-n,--line-number
在匹配的行前面列印行號。
-s,--silent
不顯示關於不存在或者無法讀取文件的錯誤信息。
-v,--revert-match
反檢索,只顯示不匹配的行。
-w,--word-regexp
如果被\<和\>引用,就把表達式做為一個單詞搜索。
-R,-r,--recursive
遞歸的讀取目錄下的所有文件,包括子目錄。比如grep-R'pattern'test會在test及其子目錄下的所有文件中,匹配pattern。
-V,--version
顯示軟體版本信息。
-A6
查找某些字元的內容,並下延伸6行
-B6
查找某些字元的內容,並上延伸6行
-C1
查找某些字元的內容,並上和向下各延伸1行
這幾行後面的數字直接影響延伸數量,並以--符號分割搜索行的結果
要用好grep這個工具,其實就是要寫好正則表達式,所以這裡不對grep的所有功能進行實例講解,只列幾個例子,講解一個正則表達式的寫法。
$ls-l|grep'^a'
通過管道過濾ls-l輸出的內容,只顯示以a開頭的行。
$grep'test'd*
顯示所有以d開頭的文件中包含test的行。
$grep'test'aabbcc
顯示在aa,bb,cc文件中匹配test的行。
$grep'[a-z]\{5\}'aa
顯示所有包含每個字元串有5個連續小寫字元的字元串的行。
$grep'w\(es\)t.*\1'aa
如果west被匹配,則es就被存儲到內存中,並標記為1,然後搜索任意個字元(.*),這些字元後面緊跟著另外一個es(\1),找到就顯示該行。如果用egrep或grep-E,就不用"\"號進行轉義,直接寫成'w(es)t.*\1'就可以了。
在某些機器上,要使用-E參數才能夠進行邏輯匹配(詳見下)
grep"a|b"(匹配包含字元樣式為"a|b"的行)
grep-E"a|b"(匹配包含字元樣式為"a"或"b"的行)
mangrep裡面關於-E參數的說明是
-E
Treatseachpatternspecifiedasanextendedregularexpression(ERE).ANULLvaluefortheEREmatcheseveryline.
Note:Thegrepcommandwiththe-Eflagisthesameastheegrepcommand,exceptthaterrorandusagemessagesaredifferentandthe-sflagfunctionsdifferently.
egrep命令,搜索文件獲得模式。
egrep命令會在輸入文件(預設值為標準輸入)中搜索與用Pattern參數指定的模式相匹配的行。這些模式是完整的正則表達式就像在ed命令中的那樣(除了\(反斜杠)和\\(雙反斜杠))。下列規則也應用於egrep命令:
*一個正則表達式後面帶一個+(加號)會匹配一個或多個的正則表達式。
*一個正則表達式後面帶一個?(問號)會匹配零個或一個該正則表達式。
*由|(豎線)或者換行符隔開的多個正則表達式會匹配與任何一個正則表達式所匹配的字元串。
*一個正則表達式可以被包括在“()”(括弧)中進行分組。
換行符將不會被正則表達式匹配。
運算符的優先順序是[,],*,?,+,合併,|和換行符。
注意:egrep命令與grep命令帶-E標誌是一樣的,除了錯誤消息和使用消息不同以及-s標誌的功能不同之外。
egrep命令會顯示包含該匹配行的文件,如果您指定了多於一個File參數的話。
對shell有特殊含義的字元($,*,[,|,^,(,),\)出現在Pattern參數中時必須帶雙引號。如果Pattern參數不是簡單字元串,通常必須用單引號將整個模式括起來。在表達式中比如[a-z],減號表示通過當前整理序列。整理序列可以定義等價的類以供在字元範圍中使用。它使用了快速確定性的演演算法,有時需要外部空間。
fgrep命令,為文件搜索文字字元串。
fgrep命令搜索File參數指定的輸入文件(預設為標準輸入)中的匹配模式的行。fgrep命令特別搜索Pattern參數,它們是固定的字元串。如果在File參數中指定一個以上的文件fgrep命令將顯示包含匹配行的文件。
fgrep命令於grep和egrep命令不同,因為它搜索字元串而不是搜索匹配表達式的模式。fgrep命令使用快速的壓縮演演算法。$,*,[,|,(,)和\等字元串被fgrep命令按字面意思解釋。這些字元並不解釋為正則表達式,但它們在grep和egrep命令中解釋為正則表達式。
因為這些字元對於shell有特定的含義,完整的字元串應該加上單引號(‘...’)。
如果沒有指定文件,fgrep命令假定標準輸入。一般,找到的每行都複製到標準輸出中去。如果不止一個輸入文件,則在找到的每行前列印文件名。

基本信息
- 外文名
- Globally search a Regular Expression and Print
- 縮寫
- grep
- 原作者
- Ken Thompson
- 公開時間
- 1974
目錄