scrapy
Python開發的的抓取框架
Scrapy是Python開發的一個快速、高層次的屏幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的數據。Scrapy用途廣泛,可以用於數據挖掘、監測和自動化測試。
Scrapy吸引人的地方在於它是一個框架,任何人都可以根據需求方便的修改。它也提供了多種類型爬蟲的基類,如BaseSpider、sitemap爬蟲等,最新版本又提供了web2.0爬蟲的支持。
Scrapy是一個為爬取網站數據、提取結構性數據而設計的應用程序框架,它可以應用在廣泛領域:Scrapy 常應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。通常我們可以很簡單的通過 Scrapy 框架實現一個爬蟲,抓取指定網站的內容或圖片。
儘管Scrapy原本是設計用來屏幕抓取(更精確的說,是網路抓取),但它也可以用來訪問API來提取數據。
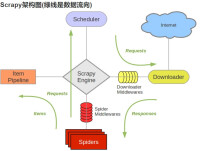
scrapy
Scheduler(調度器):它負責接受引擎發送過來的Request請求,並按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎。
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理。
Spider(爬蟲):它負責處理所有Responses,從中分析提取數據,獲取Item欄位需要的數據,並將需要跟進的URL提交給引擎,再次進入Scheduler(調度器)。
Item Pipeline(管道):它負責處理Spider中獲取到的Item,並進行進行後期處理(詳細分析、過濾、存儲等)的地方。
Downloader Middlewares(下載中間件):一個可以自定義擴展下載功能的組件。
Spider Middlewares(Spider中間件):一個可以自定擴展和操作引擎和Spider中間通信的功能組件。
● ● 製作 Scrapy 爬蟲 一共需要四步:
● ● 新建項目 :新建一個新的爬蟲項目
● ● 明確目標 (編寫items.py):明確你想要抓取的目標
● ● 製作爬蟲 (spiders/xxspider.py):製作爬蟲開始爬取網頁
● ● 存儲內容 (pipelines.py):設計管道存儲爬取內容
具體如下:
選擇一個網站,如果你需要從某個網站提取一些信息,但是網站不提供API或者其他可編程的訪問機制,那麼Scrapy可以幫助你提取信息。
定義你要抓取的數據,第一件事情就是定義你要抓取的數據,在Scrapy這個是通過定義Scrapy Items來實現的。
這就是要定義的Item
from scrapy.item import Item, Fieldclass Torrent(Item): url = Field() name = Field() description = Field() size = Field()
撰寫一個蜘蛛來抓取數據
下一步是寫一個指定起始網址的蜘蛛,包含follow鏈接規則和數據提取規則。
例如/tor/\d+.來提取規則
使用Xpath,從頁面的HTML Source裡面選取要要抽取的數據,選取眾多數據頁面中的一個。
通過帶可以看到
Home[2009][Eng]XviD-ovd
name屬性包含在H1 標籤內,使用 XPath expression提取:
//h1/text()
description在id=”description“的div中
Description:
"HOME" - a documentary film by Yann Arthus-Bertrand
***
"We are living in exceptional times. Scientists tell us that we have 10 years to change the way we live, avert the depletion of natural resources and the catastrophic evolution of the Earth's climate. ...
***
"We are living in exceptional times. Scientists tell us that we have 10 years to change the way we live, avert the depletion of natural resources and the catastrophic evolution of the Earth's climate. ...
XPath提取
//div[@id='description']
size屬性在第二個
tag,id=specifications的div內
Category: Movies > Documentary
Total size: 699.79 megabyte
XPath expression提取
//div[@id='specifications']/p[2]/text()[2]
如果要了解更多的XPath 參考這裡 XPath reference.
蜘蛛代碼如下:
class MininovaSpider(CrawlSpider): name = '參考閱讀4' allowed_domains = ['參考閱讀4'] start_urls = ['參考閱讀1'] rules = [Rule(SgmlLinkExtractor(allow=['/tor/\d+']), 'parse_torrent')] def parse_torrent(self, response): x = HtmlXPathSelector(response) torrent = TorrentItem() torrent['url'] = response.url torrent['name'] = x.select("//h1/text()").extract() torrent['description'] = x.select("//div[@id='description']").extract() torrent['size'] = x.select("//div[@id='info-left']/p[2]/text()[2]").extract() yield torrent
因為很簡單的原因,我們有意把重要的數據定義放在了上面。
運行蜘蛛來抓取數據
我們需要創建一個運行文件,放在setting同級目錄下,用來單獨運行蜘蛛:
from scrapy.cmdline import executeexecute('scrapy crawl 所創建的py文件名'.split())
最後,運行這個文件,可以看到相應的數據就輸出了出來。
查看一下數據:scraped_data.json。
關注一下數據,你會發現,所有欄位都是lists(除了url是直接賦值),這是因為selectors返回的就是lists格式,如果你想存儲單獨數據或者在數據上增加一些解釋或者清洗,可以使用Item Loaders
你也看到了如何使用Scrapy從一個網站提取和存儲數據,實際上,Scrapy提供了許多強大的特性,讓它更容易和高效的抓取:
1>內建 selecting and extracting,支持從HTML,XML提取數據
2>內建Item Loaders,支持數據清洗和過濾消毒,使用預定義的一個過濾器集合,可以在所有蜘蛛間公用
4>針對抓取對象,具有自動圖像(或者任何其他媒體)下載automatically downloading images的管道線
5>支持擴展抓取extending Scrap,使用signals來自定義插入函數或者定義好的API(middlewares, extensions, and pipelines)
6>大範圍的內建中間件和擴展,基於但不限於cookies and session handling
HTTP compression
HTTP authentication
HTTP cache
user-agent spoofing
robots.txt
crawl depth restriction
and more
7>強壯的編碼支持和自動識別機制,可以處理多種國外的、非標準的、不完整的編碼聲明等等
8>可擴展的統計採集stats collection,針對數十個採集蜘蛛,在監控蜘蛛性能和識別斷線斷路?方面很有用處
9>一個可交互的XPaths腳本命令平台介面Interactive shell console,在調試撰寫蜘蛛上是非常有用
10>一個系統服務級別的設計,可以在產品中非常容易的部署和運行你的蜘蛛
11>內建的Web service,可以監視和控制你的機器人
12>一個Telnet控制台Telnet console,可以鉤入一個Python的控制台在你的抓取進程中,以便內視或者調試你的爬蟲
13>支持基於Sitemap的網址發現的爬行抓取
14>具備緩存DNS和resolver功能

基本信息
- 中文名
- scrapy抓取框架
- 外文名
- scrapy
- 特點
- 應用框架
- 基本功能
- 數據挖掘
- 應用
- 數據挖掘、監測和自動化測試
- 運行蜘蛛
- 抓取
目錄