共找到2條詞條名為TFS的結果 展開
- 為外部提供高併發的存儲引擎
- 美國塔盧拉弗中學
TFS
為外部提供高併發的存儲引擎
TFS(Team Foundation Server)是一個工作流協作的引擎。是一個高可擴展、高可用、高性能、面向網際網路服務的分散式文件系統,主要針對海量的非結構化數據,它構築在普通的Linux機器集群上,可為外部提供高可靠和高併發的存儲訪問。
TFS(Team Foundation Server)是一個工作流協作的引擎,它允許一個團隊使用他們自定義的流程,並使用在項目歷史中實時收集起來的一個集中的數據倉庫。
我們的方法是唯一的,因為前端的設計有良好的可用性,而後端的設計集成了整個生命周期。我們主要關注於可用性,以及為個人和團隊以一種無縫的方式進入軟體開發周期。
客戶關心的另外一個方面是靈活性和審核。Team Foundation Server支持Software Engineering Institute的CapaBIlity Maturity Model(CMMI)的報表和審核的功能。通過Team Foundation Server,組織可以自動收集必要的信息,並生成自定義的報表,它可以幫助在工業管理中定位增長點。
解決方案許多合作夥伴已經宣布他們將把他們的產品與 Team Foundation Server 的功能相結合。 Teamprise 宣布了他們即將發布的解決方案,Teamprise Client Suite 1.0。Teamprise Client Suite允許軟體開發團隊在異構的環境和其它的操作系統中,包括Linux和 MAC OS X,在EClipse Integrated Development Environment(IDE)中使用Team Foundation Server的源代碼控制和工作項目跟蹤的功能。Ravenflow宣布了RAVEN ProfESsional,建立在公司的REVEN Scenario產品的成功之上的一個工具包。REVEN Scenario是唯一一個可以從英文文本自動生成統一建模語言(UML)圖的工具,它允許公司在開發開始前驗證需求。 EDS和Fujitsu正在演示他們的開發方法論,並且在為他們的客戶開發解決方案時擴展Visual Studio Team System。這些都期望在Team Foundation Server中調節BI和報表的能力,並通過收集實時的數據來影響分析和計劃。仿液壓成型TFS是仿液壓成型的簡稱,英文為:Techo Forming System,採用了3D立體特殊成型技術,是屬於美利達自行車特有的專利技術。TFS是仿照HFS,用比較簡單的工藝製造出的,貌似HFS車架的東東。而HFS車架,則是真正有技術含量的;獨特的;能與其他品牌真正抗衡的美利達車架。HFS是Hydraulic Horming System的縮寫,就是運用特殊的Hydraulic Horming System液壓成型技術,美利達在6066 prolite的鋁合金車架管刻劃出絕美的3D立體線條,將車架減到不可思議的程度(18"車架約1.4kg),卻同時保有美利達一貫堅持的特性:超高的剛性強度。而所謂管件液壓成形技術,適用於異厚異形之中空結構管件,顧名思義是先將管材置於具形狀的模具中,藉由管件內部加入高壓流體(目前主要以水為主),搭配軸向施加壓力補償管料,把管料壓入到模具腔體內成形。使用這樣的技術,可以讓HFS車架的管壁更加的薄,從而減輕重量,提高強度。但是由於這種加工方式設備昂貴、廢品率高,造成HFS車架的成本居高不下。薄膜存儲器薄膜存儲器thin film storage,簡稱TFS,薄膜存儲是在集成電路工藝上發展起來的新存儲技術。其原理是通過改變硅基底上的薄膜的物理性質,實現數字信息的存儲。薄膜存儲器目前有鐵電薄膜存儲器和有機薄膜存儲器等。文件系統TFS(Taobao FileSystem)是一個高可擴展、高可用、高性能、面向網際網路服務的分散式文件系統,其設計目標是支持海量的非結構化數據。淘蝌蚪項目主頁:code#taobao#org/project/view/366/(#修改為.)其他解釋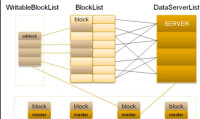 Tactical Fighter Squadron(TFS)戰術戰鬥機中隊高等學校法語專業考試等級證書:TFS韓國化妝品牌子:The face shop簡稱“TFS"偽後宮動漫小說:THE Felicità Story(TFS)同步發電機型號:TFS系列三次諧波同步發電機是蘭州電機有限責任公司生產的國產電機產品美利達山地車車架名稱:TFS特性1.採用扁平化的數據組織結構2.使用HA架構和平滑擴容3.支持多種客戶端4.支持大小文件存儲5.可為外部提供高可靠和高併發的存儲訪問6.支持大文件功能7.Resource Center Server,用於管理TFS集群的用戶資源配置8.TFS服務程序開發框架,統一TFS網路客戶端庫,並新增非同步回調功能9.優化數據流,讓寫請求儘可能均勻的分佈在不同的DataServer總體結構一個TFS集群由兩個NameServer節點(一主一備)和多個!DataServer節點組成。這些服務程序都是作為一個用戶級的程序運行在普通Linux機器上的DataServer進程會給Block中的每個文件分配一個ID(File ID,該ID在每個Block中唯一),並將每個文件在Block中的信息存放在和Block對應的Index文件中。這個Index文件一般都會全部load在內存,除非出現DataServer伺服器內存和集群中所存放文件平均大小不匹配的情況。文件名結構TFS的文件名由塊號和文件號通過某種對應關係組成,最大長度為18位元組。文件名固定以T開始,第二位元組為該集群的編號(可以在配置項中指定,取值範圍1~9)。餘下的位元組由Block ID和File ID通過一定的編碼方式得到。文件名由客戶端程序進行編碼和解碼,它映射方式如下圖:TFS客戶程序在讀文件的時候通過將文件名轉換為BlockID和FileID信息,然後可以在!NameServer取得該塊所在!DataServer信息(如果客戶端有該Block與!DataServere的緩存,則直接從緩存中取),然後與!DataServer進行讀取操作。
Tactical Fighter Squadron(TFS)戰術戰鬥機中隊高等學校法語專業考試等級證書:TFS韓國化妝品牌子:The face shop簡稱“TFS"偽後宮動漫小說:THE Felicità Story(TFS)同步發電機型號:TFS系列三次諧波同步發電機是蘭州電機有限責任公司生產的國產電機產品美利達山地車車架名稱:TFS特性1.採用扁平化的數據組織結構2.使用HA架構和平滑擴容3.支持多種客戶端4.支持大小文件存儲5.可為外部提供高可靠和高併發的存儲訪問6.支持大文件功能7.Resource Center Server,用於管理TFS集群的用戶資源配置8.TFS服務程序開發框架,統一TFS網路客戶端庫,並新增非同步回調功能9.優化數據流,讓寫請求儘可能均勻的分佈在不同的DataServer總體結構一個TFS集群由兩個NameServer節點(一主一備)和多個!DataServer節點組成。這些服務程序都是作為一個用戶級的程序運行在普通Linux機器上的DataServer進程會給Block中的每個文件分配一個ID(File ID,該ID在每個Block中唯一),並將每個文件在Block中的信息存放在和Block對應的Index文件中。這個Index文件一般都會全部load在內存,除非出現DataServer伺服器內存和集群中所存放文件平均大小不匹配的情況。文件名結構TFS的文件名由塊號和文件號通過某種對應關係組成,最大長度為18位元組。文件名固定以T開始,第二位元組為該集群的編號(可以在配置項中指定,取值範圍1~9)。餘下的位元組由Block ID和File ID通過一定的編碼方式得到。文件名由客戶端程序進行編碼和解碼,它映射方式如下圖:TFS客戶程序在讀文件的時候通過將文件名轉換為BlockID和FileID信息,然後可以在!NameServer取得該塊所在!DataServer信息(如果客戶端有該Block與!DataServere的緩存,則直接從緩存中取),然後與!DataServer進行讀取操作。
tfs
1。 全部扁平化的數據組織結構, 遺棄了傳統文件系統的目錄結構
2。 使用HA架構和平滑擴容
3。 支持多種客戶端
4。 支持大小文件存儲
5。 可為外部提供高可靠和高併發的存儲訪問
6。 支持大文件功能
7。 Resource Center Server,用於管理TFS集群的用戶資源配置
8。 TFS服務程序開發框架,統一TFS網路客戶端庫,並新增非同步回調功能
9。 優化數據流,讓寫請求儘可能均勻的分佈在不同的DataServer
一個TFS集群由兩個NameServer節點(一主一備)和多個DataServer節點組成。這些服務程序都是作為一個用戶級的程序運行在普通Linux機器上的。
圖1 TFS總體架構
同時為了考慮容災,NameServer採用了HA結構,即兩台機器互為熱備,同時運行,一台為主,一台為備,主機綁定到對外vip,提供服務;當主機器宕機后,迅速將vip綁定至備份NameServer,將其切換為主機,對外提供服務。圖1中的HeartAgent就完成了此功能。
TFS的設計目標是海量小文件的存儲,所以在TFS中,將大量的小文件(實際數據文件)合併成為一個大文件,這個大文件稱為塊(Block), 每個Block擁有在集群內唯一的編號(BlockId),Block Id在NameServer在創建Block的時候分配, NameServer維護block與DataServer的關係。Block中的實際數據都存儲在DataServer上。而一台DataServer伺服器一般會有多個獨立DataServer進程存在,每個進程負責管理一個掛載點,這個掛載點一般是一個獨立磁碟上的文件目錄,以降低單個磁碟損壞帶來的影響。
NameServer
NameServer主要功能是: 管理維護Block和DataServer相關信息,包括DataServer加入,退出, 心跳信息, block和DataServer的對應關係建立,解除。
正常情況下,一個塊會在DataServer上存在, 主NameServer負責Block的創建,刪除,複製,均衡,整理, NameServer不負責實際數據的讀寫,實際數據的讀寫由DataServer完成。
DataServer
DataServer主要功能是: 負責實際數據的存儲和讀寫。
TFS的塊大小可以通過配置項來決定,通常使用的塊大小為64M。TFS的設計目標是海量小文件的存儲,所以每個塊中會存儲許多不同的小文件。DataServer進程會給Block中的每個文件分配一個ID(File ID,該ID在每個Block中唯一),並將每個文件在Block中的信息存放在和Block對應的Index文件中。這個Index文件一般都會全部存放在內存,除非出現DataServer伺服器內存和集群中所存放文件平均大小不匹配的情況。
另外,還可以部署一個對等的TFS集群,作為當前集群的輔集群。輔集群不提供來自應用的寫入,只接受來自主集群的寫入。當前主集群的每個數據變更操作都會重放至輔集群。輔集群也可以提供對外的讀,並且在主集群出現故障的時候,可以接管主集群的工作。
Block的存儲方式
在TFS中,將大量的小文件(實際用戶文件)合併成為一個大文件,這個大文件稱為塊(Block)。TFS以Block的方式組織文件的存儲。每一個Block在整個集群內擁有唯一的編號,這個編號是由NameServer進行分配的,而DataServer上實際存儲了該Block。在NameServer節點中存儲了所有的Block的信息,一個Block存儲於多個DataServer中以保證數據的冗餘。對於數據讀寫請求,均先由NameServer選擇合適的DataServer節點返回給客戶端,再在對應的DataServer節點上進行數據操作。NameServer需要維護Block信息列表,以及Block與DataServer之間的映射關係,其存儲的元數據結構如下:
存儲的元數據結構
在DataServer節點上,在掛載目錄上會有很多物理塊,物理塊以文件的形式存在磁碟上,並在DataServer部署前預先分配,以保證後續的訪問速度和減少碎片產生。為了滿足這個特性,DataServer現一般在EXT4文件系統上運行。物理塊分為主塊和擴展塊,一般主塊的大小會遠大於擴展塊,使用擴展塊是為了滿足文件更新操作時文件大小的變化。每個Block在文件系統上以“主塊+擴展塊”的方式存儲。每一個Block可能對應於多個物理塊,其中包括一個主塊,多個擴展塊。
在DataServer端,每個Block可能會有多個實際的物理文件組成:一個主Physical Block文件,N個擴展Physical Block文件和一個與該Block對應的索引文件。Block中的每個小文件會用一個block內唯一的fileid來標識。DataServer會在啟動的時候把自身所擁有的Block和對應的索引文件載入進來。
文件名結構
TFS的文件名由塊號和文件號通過某種對應關係組成,最大長度為18位元組。文件名固定以T開始,第二位元組為該集群的編號(可以在配置項中指定,取值範圍 1~9)。餘下的位元組由Block ID和File ID通過一定的編碼方式得到。文件名由客戶端程序進行編碼和解碼,它映射方式如下圖:
映射方式
TFS客戶程序在讀文件的時候通過將文件名轉換為BlockID和FileID信息,然後可以在NameServer取得該塊所在DataServer信息(如果客戶端有該Block與DataServere的緩存,則直接從緩存中取),然後與DataServer進行讀取操作。
對於同一個文件來說,多個用戶可以併發讀。
現有TFS並不支持併發寫一個文件。一個文件只會有一個用戶在寫。這在TFS的設計裡面對應著是一個block同時只能有一個寫或者更新操作。
集群容錯
TFS可以配置主輔集群,一般主輔集群會存放在兩個不同的機房。主集群提供所有功能,輔集群只提供讀。主集群會把所有操作重放到輔集群。這樣既提供了負載均衡,又可以在主集群機房出現異常的情況不會中斷服務或者丟失數據。
NameServer容錯
Namserver主要管理了DataServer和Block之間的關係。如每個DataServer擁有哪些Block,每個Block存放在哪些DataServer上等。同時,NameServer採用了HA結構,一主一備,主NameServer上的操作會重放至備NameServer。如果主NameServer出現問題,可以實時切換到備NameServer。
另外NameServer和DataServer之間也會有定時的heartbeat,DataServer會把自己擁有的Block發送給NameServer。NameServer會根據這些信息重建DataServer和Block的關係。
DataServer容錯
TFS採用Block存儲多份的方式來實現DataServer的容錯。每一個Block會在TFS中存在多份,一般為3份,並且分佈在不同網段的不同DataServer上。對於每一個寫入請求,必須在所有的Block寫入成功才算成功。當出現磁碟損壞DataServer宕機的時候,TFS啟動複製流程,把備份數未達到最小備份數的Block儘快複製到其他DataServer上去。 TFS對每一個文件會記錄校驗crc,當客戶端發現crc和文件內容不匹配時,會自動切換到一個好的block上讀取。此後客戶端將會實現自動修復單個文件損壞的情況。
原有TFS集群運行一定時間后,集群容量不足,此時需要對TFS集群擴容。由於DataServer與NameServer之間使用心跳機制通信,如果系統擴容,只需要將相應數量的新DataServer伺服器部署好應用程序后啟動即可。這些DataServer伺服器會向NameServer進行心跳彙報。NameServer會根據DataServer容量的比率和DataServer的負載決定新數據寫往哪台DataServer的伺服器。根據寫入策略,容量較小,負載較輕的伺服器新數據寫入的概率會比較高。同時,在集群負載比較輕的時候,NameServer會對DataServer上的Block進行均衡,使所有DataServer的容量儘早達到均衡。
進行均衡計劃時,首先計算每台機器應擁有的blocks平均數量,然後將機器劃分為兩堆,一堆是超過平均數量的,作為移動源;一類是低於平均數量的,作為移動目的。
移動目的的選擇:首先一個block的移動的源和目的,應該保持在同一網段內,也就是要與另外的block不同網段;另外,在作為目的的一定機器內,優先選擇同機器的源到目的之間移動,也就是同台DataServer伺服器中的不同DataServer進程。
當有伺服器故障或者下線退出時(單個集群內的不同網段機器不能同時退出),不影響TFS的服務。此時NameServer會檢測到備份數減少的Block,對這些Block重新進行數據複製。
在創建複製計劃時,一次要複製多個block, 每個block的複製源和目的都要儘可能的不同,並且保證每個block在不同的子網段內。因此採用輪換選擇(roundrobin)演演算法,並結合加權平均。
由於DataServer之間的通信是主要發生在數據寫入轉發的時候和數據複製的時候,集群擴容基本沒有影響。假設一個Block為64M,數量級為1。那麼NameServer上會有 1 * 1024 * 1024 * 1024 / 64 = 16。7M個block。假設每個Block的元數據大小為0.1K,則佔用內存不到2G。
