流處理器數量
流處理器數量
流處理器單元是統一架構GPU內通用標量著色器的稱謂。流處理單元直接影響處理能力,因為流處理單元是顯卡的核心。流處理單元個數越多則處理能力越強,一般成正比關係,但這僅限於NVIDIA自家的核心或者AMD自家的核心比較範疇。NVIDIA和AMD的流處理單元比較不可採取近似比較,實際上AMD的應該叫流處理器單元,它每5個單元配一個數據收發的,這才是一個完整的流處理器,這樣算一個流處理器。而NVIDIA的1個流處理單元卻只有1個單元。這是A卡與N卡的構造區別。形象點說,這個流處理單元相當於神經元,神經元越多大腦越發達,流處理單元越多顯卡處理性能也就越強。
賣場中,一位裝機技術員侃侃而談:“ NVIDIA最新的GTX295顯卡核心只有2*240個流處理器, ATI的HD5970顯卡核心卻有3200個流處理器,你要最高性能的顯卡,當然要選HD5970顯卡。”
AMD-ATI顯卡(以下簡稱A卡)和NVIDIA(以下簡稱N卡)在流處理器數量上的巨大差異給許多讀者造成巨大的困惑。其實,這個情況和不同廠商、相當於CPU的二級緩存數量存在差異情況類似,簡單來說就是“不同架構的GPU,流處理器的作用不盡相同,不能直接比較數量。”深入的解釋請看下文說明。
早在微軟推出的DirectX 7當中就曾經提出過一個概念——T&L(中文名稱是坐標轉換和光源),它可以看做是流處理器的鼻祖,隨著顯卡核心晶元技術的發展,在DirectX 8中。由微軟首次提出了Shader的概念。並且將Shader分為Vertex Shader(頂點著色器,又稱VS單元)和Pixel Shader(像素著色器,又稱PS單元)。
一副遊戲畫面是怎麼顯示的呢?其中,3D物體的幾何形狀、光亮和陰影的控制是由Vertex Shader來實現的,而Pixel Shader是對象素資料進行操作運算的指令程序。其中包括了像素的色彩、深度坐標等資料,在GeForce 8之前,Pixel Shader和 Vetex Shader這兩個參數非常重要,這兩個部分的多少完全決定了顯卡的性能表現,N卡和A卡雙方都為了提升Pixel Shader和Vetex Shader的數量而想盡一切辦法。但是,在DirectX 10這一代顯卡中,業界提出了一個新的概念——統一渲染架構,就是把原有的VS單元和PS單元統一起來,統稱為Shader運算單元。這也就是我們所說的流處理器(Stream Processor)。因此,上述任務就由流處理器統一執行了,既然流處理器是來自於VS單元和PS單元的統一渲染架構。那麼,流處理器的作用於VS單元+PS單元的合作用就是基本相同的。只是添加了全新的處理單元——Geometry Shader(幾何渲染器,又稱GS單元)。
同一架構的顯卡,流處理器的個數自然是越多越好。相信讀者也在各大網站了解到這樣的信息——“同價位的產品中,N卡的流處理器數量要少於A卡”。比如本文開頭的裝機技術員提到ATI Radeon HD5970顯卡比NVIDIA GeForce GTX295顯卡的流處理器數量多數倍,這是正確的。但是前者性能只是略強於後者。這是為什麼呢,其實在“流處理器”的名稱上A卡和N卡存在細微的差別,N卡的流處理器全稱為Stream Processing,而A卡的流處理器全稱為Stream Processing Units,一詞之差卻讓兩者的的性能差距有著天壤之別。而且因為A卡和N卡的GPU架構存在根本性的差異,所以流處理器的工作方式和用途也有所差異,故不能直接比較流處理器的數量。這就可以解決許多讀者的疑問了。A卡的GPU流處理器數量多很多,但A卡的一個流處理器單元和N卡的一個流處理器相比N卡更強。下面我們來分析A卡和N卡的GPU架構及流處理器的工作方式,看看有什麼不同。
流處理器數量
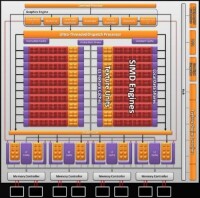
NVIDIA方面,GeForce GTX200核心架構分為四個層。最上面一層包括幾何著色器(Geometry Shader)、頂點著色器(Vetex Shader)和像素著色器(Pixel Shader),中間一層包括了10組TPCs(計算處理器群集)。每組TPC裡面又包含了3組SMs(流處理器組) ,每組SM裡面就包含了8個流處理器單元或計算單元,這樣一來,GeForce GTX 200顯卡就一共包含了240個流處理器單元或計算單元。流處理器是直接將多媒體的圖形數據流映射到流處理器上進行處理的,有可編程和不可編程兩種。1995年公布的名為Cheops中的流處理器,是針對某一個特定的視頻處理功能而設計的一種不可編程的流處理器。但為了得到一定的靈活性,系統中也包含一個通用的可編程處理器。
從1996年到2001年,MIT和Standford針對圖像處理的應用,研製了名為Imagine的可編程流處理器。Imagine流處理器沒有採用cache,而是採用一個流寄存器文件SRF(Stream Register File),作為流(主)存儲器與處理器寄存器之間的緩衝存儲器,來解決存儲器帶寬問題的。流存儲器與SRF之間的帶寬是2GB/s,SRF與處理器寄存器之間的帶寬是32GB/s,ALU簇(ALU Cluster)內寄存器與ALU之間的帶寬是544GB/s,三種帶寬的比例關係為1:16:272。
抗鋸齒是3D特效中最重要的效果之一,它經過多年的發展,變為一個龐大的家庭,有必要獨立開來說明一下。
作用:去除物體邊緣的鋸齒現象,廣州話稱之為“狗牙”,大家可以想像一下狗牙是如何的凹凸不平。
過程:我們在真實世界看到的物體,由無限的像素組成,不會看到有鋸齒現象,而顯示器沒有足夠多的點來表現圖形,點與點之間的不連續就造成了鋸齒。
抗鋸齒通過採樣演演算法,在像素與像素之間進行平均值計算,增加像素的數目,達到像素之間平滑過渡的效果。去掉鋸齒后,還可以模擬高解析度遊戲的精緻畫面。它是目前最熱門的特效,主要用於1600 * 1200以下的低解析度。理論上來說,在17寸顯示器上,1600 * 1200解析度已經很難看到鋸齒,無須使用抗鋸齒演演算法。如此類推,在21.6寸顯示器上,必須使用1920 x 1080解析度,總之,越大的顯示器,解析度越高,才越不會看到抗鋸齒1920 x 1200。由於RAMDAC(Random Access Memory Digital to Analog Converter,隨機存儲器數/模轉換器)頻率和顯示器製造技術的限制,我們不可能永無止境地提升顯示器和顯卡的解析度,抗鋸齒技術變得很有必要了。
超級採樣抗鋸齒
最早期的全屏抗鋸齒,方法簡單直接。首先,圖像創建到一個分離的緩衝區,緩衝區圖像解析度高於屏幕解析度,假設是2*1(或2x),那麼緩衝區場景的水平尺寸比屏幕解析度高兩倍,若是2*2(或4x)抗鋸齒,緩衝區圖像的水平和垂直均比顯示圖像大兩倍。像素計算加倍之後,選取2個或4個鄰近像素,此過程稱為採樣。把這些採樣混合起來后,生成的最終像素,擁有鄰近像素的特徵,那麼像素與像素之間的過渡色彩,就變得更為近似,整個圖像的色彩過渡趨於平滑。再把最終像素輸出到幀緩衝,作為一幅圖像存儲起來,然後發到顯示器,顯示出一幀畫面。每幀都進行抗鋸齒處理,遊戲過程中的所有畫面都變得帶有抗鋸齒效果了。
遊戲卡曼奇四中採用的4X抗鋸齒演演算法,Commanche 4 4xs
邊緣超級採樣抗鋸齒

流處理器數量
在進入統一渲染架構時代后,提高Shader運行頻率與效率是NVIDIA主導的設計思路,而AMD則維持龐大的流處理器數量。兩種思路各有優劣。
1、N的優勢和A的劣勢
N卡的GPU中每個流處理器都具有完整的ALU(算術邏輯單元)功能,在發出一條操作指令時每個流處理器都能充分工作。而A卡的GPU中每個流處理器的5個流處理單元都是固定的,不能拆開重組,如果在處理純4D指令的時候,每個流處理器只能處理一條4D指令,有一個流處理器單元閑置,但卻無法加入其他組合來共同工作。
簡單地說,一個指令任務派發下來的時候,N卡的GPU是需要1個“人”獨立工作即可完成。而A卡的GPU則需要5個“人”。結組工作才能完成ATI的人數雖然多,但這5個“人”中有可能會有4個“人”閑置,因為這4個“人”不具有獨立完整的ALU功能,不能執行函數運算,浮點運算和Multipy運算。
2、N的劣勢和A的優勢
ATI的設計也有其顯著的特點——浮點運算能力強大。也就是說如果單純比拼顯示核心在浮點運算上的能力的話,可能ATI則要強一些,在GPGPU(通用圖形處理器)項目應用比較多的科學計算方面,理論上能適應GPU和CPU融合的趨勢。
3、結論
開篇提到的,因為N卡的一個流處理器等於五個A卡的流處理單元,也即HD5970的3200個流處理單元相當於640(3200/5)個流處理器。
