碼字
利用Huffman碼編碼后的信號
碼字(Code Word)是指利用Huffman碼編碼后的信號。
一幀包含m個數據位(即報文)和r個冗餘位(校驗位)。幀的總長度=數據位+冗餘位,包含數據和校驗位的第X位單元通常成為X位碼字(codeword)。碼字由若干個碼元組成,計算機通信中通信表現為若干位二進位代碼。
碼字(Code Word)是指利用Huffman(哈夫曼)碼編碼后的信號。
由於電子設備只能表示0、1兩種狀態,因此用電子方式處理符號是,需要對符號進行二進位編碼。例如,在計算機中使用的ASCII碼,就是計算機中常用符號的8位二進位編碼,在實際中,也可以根據情況對字元進行特定的編碼。
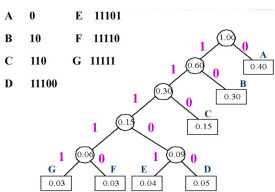
設某信源產生有五種符號u1、u2、u3、u4和u5,對應概率P1=0.4,P2=0.1,P3=P4=0.2,P5=0.1。首先,將符號按照概率由大到小排隊,如圖所示。編碼時,從最小概率的兩個符號開始,可選其中一個支路為0,另一支路為1。這裡,我們選上支路為0,下支路為1。再將已編碼的兩支路的概率合併,並重新排隊。多次重複使用上述方法直至合併概率歸一時為止。從圖(a)和(b)可以看出,兩者雖平均碼長相等,但同一符號可以有不同的碼長,即編碼方法並不唯一,其原因是兩支路概率合併后重新排隊時,可能出現幾個支路概率相等,造成排隊方法不唯一。一般,若將新合併后的支路排到等概率的最上支路,將有利於縮短碼長方差,且編出的碼更接近於等長碼。這裡圖(a)的編碼比(b)好。
赫夫曼碼的碼字(各符號的代碼)是異前置碼字,即任一碼字不會是另一碼字的前面部分,這使各碼字可以連在一起傳送,中間不需另加隔離符號,只要傳送時不出錯,收端仍可分離各個碼字,不致混淆。
實際應用中,除採用定時清洗以消除誤差擴散和採用緩衝存儲以解決速率匹配以外,主要問題是解決小符號集合的統計匹配,例如黑(1)、白(0)傳真信源的統計匹配,採用0和1不同長度遊程組成擴大的符號集合信源。遊程,指相同碼元的長度(如二進碼中連續的一串0或一串1的長度或個數)。按照CCITT標準,需要統計2×1728種遊程(長度),這樣,實現時的存儲量太大。事實上長遊程的概率很小,故CCITT還規定:若l表示遊程長度,則l=64q+r。其中q稱主碼,r為基碼。編碼時,不小於64的遊程長度由主碼和基碼組成。而當l為64的整數倍時,只用主碼的代碼,已不存在基碼的代碼。
長遊程的主碼和基碼均用赫夫曼規則進行編碼,這稱為修正赫夫曼碼,其結果有表可查。該方法已廣泛應用於文件傳真機中。
基本信息
- 中文名
- 碼字
- 外文名
- Code Word
- 術語類別
- 通信術語
- 定義
- 利用Huffman碼編碼后的信號