有損壓縮
有損壓縮
有損壓縮是對利用了人類是絕對圖像或聲波中的某些頻率成分不敏感的特性,允許壓縮過程中損失一定的信息;雖然不能完全回復原始數據,但是所損失的部分對理解原始圖像的影響縮小有損壓縮,卻換來了大得多的壓縮比。有損壓縮廣泛應用於語音,圖像和視頻數據的壓縮。
目錄
在多媒體應用中,常見的壓縮方法有:PCM(脈衝編碼調製),預測編碼,變換編碼,插值和外推法,統計編碼,矢量量化和子帶編碼等,混合編碼是近年來廣泛採用的方法。mp3 divX Xvid jpeg rm rmvb wma wmv等都是有損壓縮。
有損壓縮
有損數據壓縮都會有generationloss:壓縮與解壓文件都會帶來漸進的質量下降。有損壓縮可以減少圖像在內存和磁碟中佔用的空間,在屏幕上觀看圖像時,不會發現它對圖像的外觀產生太大的不利影響。因為人的眼睛對光線比較敏感,光線對景物的作用比顏色的作用更為重要,這就是有損壓縮技術的基本依據。有損壓縮的特點是保持顏色的逐漸變化,刪除圖像中顏色的突然變化。生物學中的大量實驗證明,人類大腦會利用與附近最接近的顏色來填補所丟失的顏色。例如,對於藍色天空背景上的一朵白雲,有損壓縮的方法就是刪除圖像中景物邊緣的某些顏色部分。當在·屏幕上看這幅圖時,大腦會利用在景物上看到的顏色填補所丟失的顏色部分。利用有損壓縮技術,某些數據被有意地刪除了,而被取消的數據也不再恢復。無可否認,利用有損壓縮技術可以大大地壓縮文件的數據,但是會影響圖像質量。如果使用了有損壓縮的圖像僅在屏幕上顯示,可能對圖像質量影響不太大,至少對於人類眼睛的識別程度來說區別不大。可是,如果要把一幅經過有損壓縮技術處理的圖像用高解析度印表機列印出來,那麼圖像質量就會有明顯的受損痕迹。
有兩種基本的有損壓縮機制:一種是有損變換編解碼,首先對圖像或者聲音進行採樣、切成小塊、變換到一個新的空間、量化,然後對量化值進行熵編碼。另外一種是預測編解碼,先前的數據以及隨後解碼數據用來預測當前的聲音採樣或者或者圖像幀,預測數據與實際數據之間的誤差以及其它一些重現預測的信息進行量化與編碼些系統中同時使用這兩種技術,變換編解碼用於壓縮預測步驟產生的誤差信號。
有損方法的一個優點就是在有些情況下能夠獲得比任何已知無損方法小得多的文件大小,同時又能滿足系統的需要。有損方法經常用於壓縮聲音、圖像以及視頻。有損視頻編解碼幾乎總能達到比音頻或者靜態圖像好得多的壓縮率(壓縮率是壓縮文件與未壓縮文件的比值)。
音頻能夠在沒有察覺的質量下降情況下實現10:1的壓縮比,視頻能夠在稍微觀察質量下降的情況下實現如300:1這樣非常大的壓縮比。有損靜態圖像壓縮經常如音頻那樣能夠得到原始大小的1/10,但是質量下降更加明顯,尤其是在仔細觀察的時候。當用戶得到有損壓縮文件的時候,譬如為了節省下載時間,解壓文件與原始文件在數據位的層面上看可能會大相徑庭,但是對於多數實用目的來說,人耳或者人眼並不能分辨出二者之間的區別。一些方法將人體解剖方面的特質考慮進去,例如人眼只能看到一定頻率的光線。心理聲學模型描述的是聲音如何能夠在不降低聲音感知質量的前提下實現最大的壓縮。人眼或人耳能夠察覺的有損壓縮帶來的缺陷稱為壓縮失真(en:compressionartifact)。
——MP3(MP3PRO\MP3SURROUND)、AAC(*.3gp/*.mp4/*.m4v)、ATRAC3/ATRAC3+(*.aa3)。先來明白音頻壓縮的原理:利用人耳聽覺的心理聲學特性(頻譜掩蔽特性和時間掩蔽特性等)以及人耳對信號幅度、頻率、時間的有限分辨能力,編碼時凡是人耳感覺不到的頻率不編碼、不傳送,即凡是對人耳辨別聲音信號的強度、聲調、方位沒有貢獻的部分(稱為不相關部分或無關部分)都不編碼和傳送。對感覺不到的部分進行編碼時,允許有較大的量化失真、並使其處於聽閾(即人耳所能聽到的最低音量)以下,人耳仍然感覺不到。音頻的壓縮就是利用這些特點來工作的。
1、等響度曲線人的聽覺的靈敏度隨著頻率而改變。即通常兩個功率一樣但頻率不同的音調聽起來並不一樣響。通過等響度曲線,我們可以看出,人耳對4KHz的頻率最靈敏,即在4KHz下能被察覺出來的聲音壓力水平(響度),在其他頻率下並不能被察覺。這就給在一些不太靈敏的頻率下失真提供了條件。
2、屏蔽我們上高中物理時學過屏蔽。就是強的聲音信號把弱的聲音信號覆蓋,導致我們無法察覺。而且,當兩個聲音在時間和頻率上很接近時,屏蔽效應就會很強。因此,我們可以在編碼時對被屏蔽的部分不編碼、不傳送。這樣,音質依然沒有大的損失,人耳也不易察覺。
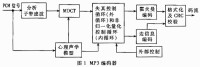
3、臨界頻帶對於人類的聽覺來說,對聲音的感知特性並不是以線形頻率為尺度來變化的(人的聽覺還沒那麼好),而是可以用被稱為臨界頻帶的一系列有限的頻段來表達。簡單的說,把整個頻帶劃分成幾段,在這每個頻段里,人耳的聽覺感知是相同的,即心理聲學特性都是一樣的。言歸正傳,編碼的精髓就是演演算法。主流編碼及其演演算法1、MP3(MP3PRO\MP3SURROUND)MP3應該算目前應用最廣泛的有損壓縮數字音頻格式了。它的全稱是MPEG(MovingPictureExpertsGroup)AudioLayer-3。1987年德國Fraunhofer研究院研製成功的一種有損壓縮數字音頻格式,並於1989年取得專利。起初,它並不完善,它更像一個編碼標準框架,留待人們去完善。1992年,這一技術併入了MPEG規範,並有了正式名號——MP3。MP3文件是由幀(frame)構成的,幀是MP3文件最小的組成單位。什麼是幀?還記得最初的動畫是怎麼做的嗎?不同的連續畫面切換以達到動態效果,每幅畫面就是一個“幀”,不同的是MP3裡面的幀記錄的是音頻數據而不是圖形數據。MP3的幀速度大概是30幀/秒。每個幀又由幀頭和幀數據組成,幀頭記錄著該幀的基本信息,包括位率索引和採樣率索引(這對理解ABR和VBR編碼方式很重要)。幀數據,顧名思義就是記錄著主體音頻數據。上面說的都是MP3編碼的基礎,但事實上,早期的編碼器都非常不完善,壓縮演演算法近於粗暴,音質很不理想。MP3的音質達到現在的水平有兩次飛躍:人體聽覺心理學模型(PerceptualModel)的導入和VBR技術的應用。PS:VBR是variablebitrate的縮寫,意思是可變比率,就是MP3文件壓制的時候聲音元素較多,比率較高時,將自動減低壓縮比特率,在比特率需求比較低時自動升高比特率,這樣做的目的是在保證音質基本不被損害的情況下增加文件在線播放時的速度,和減少在本機播放時所佔的系統資源……這是Xing發展的演演算法,他們將一首歌的複雜部分用高Bitrate編碼,簡單部分用低Bitrate編碼。主意雖然不錯,可惜Xing編碼器的VBR演演算法很差,音質與CBR相去甚遠。幸運的是,Lame完美地優化了VBR演演算法,使之成為MP3的最佳編碼模式。這是以質量為前提兼顧文件大小的方式,推薦編碼模式。MP3能生存到今天,它的發展仍未止步。2001年6月14日,法國湯姆森與美國RCA兩家公司聯合推出了一種新的壓縮格式:MP3PRO。MP3PRO是基於MP3技術改良而來,它利用了CodingTechnologies公司開發的編解碼增強技術,
有損壓縮
2、AAC(*.3gp/*.mp4/*.m4v)AAC是高級音頻編碼(AdvancedAudioCoding)的縮寫,它是由Fraunhofer研究院、杜比和AT&T共同研發的。AAC是MPEG-2規範的一部分,它適用於從速率8Kbps的單聲道電話音質到160Kbps多聲道的超高質量音頻範圍內的編碼。AAC與MP3相比,增加了諸如對立體聲的完美再現、碼流效果音掃描、多媒體控制、降噪優化等MP3音頻格式所沒有的特性,使得在音頻壓縮后仍能完美地再現CD音質。它還同時支持多達48個音軌、15個低頻音軌、更多種採樣率和比特率、多種語言的兼容性、更高的解碼效率。總之,AAC可以在比MP3文件縮小30%的前提下提供更好的音質。現將其中的幾個模塊作一些說明:增益控制(Gaincontrol)增益控制模塊用在可變採樣率配置中,它由多相正交濾波器PQF(polyphasequadraturefilter)、增益檢測器(gaindetector)和增益修正器(gainmodifier)組成。這個模塊把輸入信號分離到4個相等帶寬的頻帶中。在解碼器中也有增益控制模塊,通過忽略PQF的高子帶信號獲得低採樣率輸出信號。濾波器組(FilterBank) 濾波器組是把輸入信號從時域變換到頻域的轉換模塊,它是MPEG-2AAC系統的基本模塊。這個模塊採用了改進離散餘弦變換MDCT,它是一種線性正交交迭變換,使用了一種稱為時域混迭取消TDAC(timedomainaliasingcancellation)技術。MDCT使用KBD(Kaiser-Besselderived)窗口或者使用正弦(sine)窗口,
正向MDCT變換可使用下式表示:逆向MDCT變換可使用下式表示:其中,n=樣本號,N=變換塊長度,i=塊號,以上兩個離散餘弦變換公式在《離散函數》和《數理方程》中有詳細介紹,只為幫助有興趣的玩家了解,不必深究。瞬時雜訊定形TNS在感知聲音編碼中,TNS模塊是用來控制量化雜訊的瞬時形狀的一種方法,解決掩蔽閾值和量化雜訊的錯誤匹配問題。這種技術的基本想法是,在時域中的音調聲信號在頻域中有一個瞬時尖峰,TNS使用這種雙重性來擴展已知的預測編碼技術,把量化雜訊置於實際的信號之下以避免錯誤匹配。聯合立體聲編聯合立體聲編碼(jointstereocoding)是一種空間編碼技術,其目的是為了去掉空間的冗餘信息。MPEG-2AAC系統包含兩種空間編碼技術:M/S編碼(Mid/Sideencoding)和聲強/耦合(Intensity/Coupling)。M/S編碼使用矩陣運算,因此把M/S編碼稱為矩陣立體聲編碼(matrixedstereocoding)。M/S編碼不傳送左右聲道信號,而是使用標稱化的“和”信號與“差”信號,前者用於中央M(middle)聲道,後者用於邊S(side)聲道,因此M/S編碼也叫做“和-差編碼(sum-differencecoding)”。聲強/耦合編碼的名稱也很多,有的叫做聲強立體聲編碼(intensitystereocoding),或者叫做聲道耦合編碼(channelcouplingcoding),它們探索的基本問題是聲道間的不相關性(irrelevance)。預測(Prediction)這是在話音編碼系統中普遍使用的一種技術,它主要用來減少平穩(stationary)信號的冗餘度。量化器(Quantizer)使用了非均勻量化器。無雜訊編碼(Noiselesscoding)無雜訊編碼實際上就是霍夫曼編碼,它對被量化的譜係數、比例因子和方向信息進行編碼。PS:我個人比較喜歡AAC,所以寫的較為詳細,大家也不妨試試,絕對比MP3優秀。大家可以使用iTunes6來轉換AAC(*.m4v)。iTunes6下載地址:http://www.apple.com.cn/itunes/download/AAC的操作很簡單,你可以直接把AAC(*.3gp\*.mp4\*.m4v)拷貝到[MUSIC]就能播。
3、ATRAC3/ATRAC3+(*.aa3)早年玩MD的朋友都知道SONY專為MD量身定做的ATRAC音頻格式演演算法,後來又廣泛應用於SONY的NetworkWalkman和其他便攜音頻設備。“ATRAC3plus”代表“自適應轉換聲音編碼3+”,是一套基於心理聲學原理的音頻壓縮技術,從ATRAC3格式發展而來,到2002年這項技術才日趨完美。這一技術是把md隨身聽的體積縮小到很小的理論基礎。要分析ATRAC3/ATRAC3+,我們先要談談它的大哥——ATRAC演演算法。當數字音頻數據被壓縮時,通常都會把一定數量的量化噪音帶入信號。為了不讓這些信號被人耳感知,通常的做法是,音頻編碼把信號分解為一組單元,每組單元都對應著特定的時間頻率範圍。編碼器會依據前文提到的心理聲學原理來分析,對重要的單元進行高精度編碼,對不敏感的單元可以保留一些量化的噪音但不影響人耳的感知質量。解碼時,量化頻譜會根據比特分配重新建立,然後合成音頻信號。ATRAC也不例外,但有一些改進。ATRAC還應用了子頻帶解碼和轉換解碼技術,輸入的信號被分配得到不均勻的強調重要低音區的頻率分割。另外,ATRAC使用一個可變塊長度改變輸入的信號,這可以確保在穩定通過時高效的解碼,不會在瞬間通過時影響時間的解析度。具體說,輸入的信號在5.5125KHz和11.025KHz被分為3個頻帶。子頻帶的分解使用QMF(QuadratureMirrorFilters積分映射過濾器)來完成;
有損壓縮
4、AAL(ATRACAdvancedLossless)AAL是ATRACAdvancedLossless(自適應聲學轉換高級無損編碼)的縮寫,是SONY新開發的一個音頻壓縮格式其特點是無損壓縮,不損失一點音頻信息,一張CD可以壓縮到原來的30%--80%但目前PSP還不支持ATRACAdvancedLossless,但我相信在PSP3.0里極有可能對其支持。目前,其技術資料我還沒有見到,所以暫不作分析。
一個音樂文件從錄製到播放,有3個重要環節:編碼(演演算法)、解碼(硬體解碼器)、輸出(耳機、耳塞)。這每個環節都對最終我們聆聽到的聲音音質有著重要的意義,缺一不可。今天,我談的是基礎的編碼(演演算法),希望大家能找到最適合你的編碼,我個人的看法是AAC256Kbps和ATRAC3plus256Kbps。AAC的演演算法是“精緻”,ATRAC的演演算法是“巧妙”。