msxml
微軟的xml語言解析器
msxml指微軟的xml語言解析器,用來解釋xml語言的。就好像html文本下載到本地,瀏覽器會檢查html的語法,解釋html文本然後顯示出來一樣。要使用xml文件就一定要用到xml parser。不過不僅僅微軟有,像ibm,sun都有自己的xml parser。
MSXML包含SDK軟體開發套件,這是微軟公司所出的語言解析器,它已經被應用於最新的遊戲。
那麼,什麼是MSXML呢?它的全名是:「Microsoft XML Core Services」,主要是用來執行或開發經由XML所設計的最新應用程序。
微軟正式發布了其XML的核心服務組件---MSXML 4.0。和MSXML 3.0相比,MSXML 4.0提供了大量的新功能和功能改進。其中包括:對XML模式語言的支持,更快的分析器和XSLT引擎,對XML流更好的處理,更好的一致性支持。MSXML 4.0並不是MSXML 3.0的替代產品,因為在3.0中的一些過時功能已經在4.0中徹底去除了。所以4.0可以和3.0(甚至更早的版本)同時安裝。
MSXML 4.0 Service Pack 2 (SP2)是MSXML 4.0和MSXML 4.0 Service Pack 1(SP1)的完全取代版本。它提供了大量的安全和程序錯誤修復。
MSXML 4.0 SP2並不能取代MSXML 3.0,因為它已不再支持一些舊的以及不一致的功能。所以用戶可能必須同時運行MSXML 4.0和MSXML 3.0或更前版本。
MSXML 6.0 將與 MSXML3.0 和 MSXML4.0 一起安裝,並且不會影響使用MSXML3.0和MSXML4.0的現有應用程序(不受版本限制的ProgID不會指向MSXML6.0)。
2001年9月發行的Microsoft XML Core Services(MSXML)4.0版
之後發行了6.0版
引言
當前Web上流行的腳本語言是以HTML為主的語言結構,HTML是一種標記語言,而不是一種編程語言,主要的標記是針對顯示,而不是針對文檔內容本身結構的描述的。也就是說,機器本身是不能夠解析它的內容的,所以就出現了XML語言。XML(eXtensible Markup Language)語言是SGML語言的子集,它保留了SGML主要的使用功能,同時大大縮減了SGML的複雜性。XML語言系統建立的目的就是使它不僅能夠表示文檔的內容,而且可以表示文檔的結構,這樣在同時能夠被人類理解的同時,也能夠被機器所理解。XML要求遵循一定的嚴格的標準。XML分析程序比HTML瀏覽器更加要挑剔語法和結構,XML要求正在創建的網頁正確地使用語法和結構,而不是像HTML一樣,通過瀏覽器推測文檔中應該是什麼東西來實現HTML的顯示,XML使得分析程序不論在性能還是穩定性方面都更容易實現。XML文檔每次的分析結果都是一致的,不像HTML,不同的瀏覽器可能對同一個HTML作出不同的分析和顯示。同時因為分析程序不需要花時間重建不完整的文檔,所以它們能比同類HTML能更有效地執行其任務。它們能全力以赴地根據已經包含在文檔中的那個樹結構建造出相應的樹來,而不用在信息流中的混合結構的基礎上進行顯示。XML標準是對數據的處理應用,而不是只針對Web網頁的。任何類型的應用都可以在分析程序的上面進行建造,瀏覽器只是XML的一個小的組成部分。當然,瀏覽仍舊極其重要,因為它為XML工作人員提供用於閱讀信息的友好工具。但對更大的項目來說它就不過是一個顯示窗口。因為XML具有嚴格的語法結構,所以我們甚至可以用XML來定義一個應用層的通訊協議,比如網際網路開放貿易協議(Internet Open Trading Protocol)就是用XML來定義的。從某種意義上說,以前我們用BNF範式定義的一些協議和格式從原則上說都可以用XML來定義。實際上,如果我們有足夠的耐心,我們完全可以用XML來定義一個C++語言的規範。
當然,XML允許大量HTML樣式的形式自由地開發,但是它對規則的要求更加嚴格。XML主要有三個要素:DTD(Document Type Declaration—文檔類型聲明)或XML Schema(XML大綱)、XSL(eXtensible Stylesheet Language—可擴展樣式語言)和XLink(eXtensible Link Language—可擴展鏈接語言)。DTD和XML大綱規定了XML文件的邏輯結構,定義了XML文件中的元素、元素的屬性以及元素和元素的屬性之間的關係;Namespace(名域)實現統一的XML文檔數據表示以及數據的相互集成;XSL是用於規定XML文檔呈現樣式的語言,它使得數據與其表現形式相互獨立,比如XSL能使Web瀏覽器改變文檔的表示法,例如數據的顯示順序的變化,不需要再與伺服器進行通訊。通過改變樣式表,同一個文檔可以顯示得更大,或者經過摺疊只顯示外面的一層,或者可以變為列印的格式。而XLink將進一步擴展目前Web上已有的簡單鏈接。
如何實現XML解析
當然,從理論上說,根據XML的格式定義,我們可以自己編寫一個XML的語法分析器,但是實際上微軟已經給我們提供了一個XML語法解析器,如果你安裝了IE5.0以上版本的話,實際上你就已經安裝了XML語法解析器。可以從微軟官網下載最新的MSXML的SDK和Parser文件。它是一個叫做MSXML.DLL的動態鏈接庫,最新版本為msxml6,實際上它是一個COM對象庫,裡面封裝了所有進行XML解析所需要的所有必要的對象。因為COM是一種以二進位格式出現的和語言無關的可重用對象。所以你可以用任何語言(比如VB,VC,DELPHI,C++ Builder甚至是腳本語言等等)對它進行調用,在你的應用中實現對XML文檔的解析。下面的關於XML文檔對象模型的介紹是基於微軟最新的msxml3來進行的。
XML文檔對象模型分析
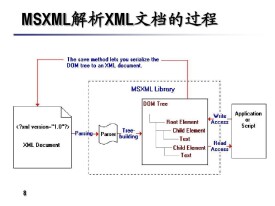
XML DOM對象提供了一個標準的方法來操作存儲在XML文檔中的信息,DOM應用編程介面(API)用來作為應用程序和XML文檔之間的橋樑。
DOM可以認為是一個標準的結構體系用來連接文檔和應用程序(也可以是劇本語言)。MSXML解析器允許你裝載和創建一個文檔,收集文檔的錯誤信息,得到和操作文檔中的所有的信息和結構,並把文檔保存在一個XML文件中。DOM提供給用戶一個介面來裝載、到達和操作並序列化XML文檔。DOM提供了對存儲在內存中的XML文檔的一個完全的表示,提供了可以隨機訪問整個文檔的方法。DOM允許應用程序根據MSXML解析器提供的邏輯結構來操作XML文檔中的信息。利用MSXML所提供的介面來操作XML。
實際上MSXML解析器根據XML文檔生成一個DOM樹結構,它能夠讀XML文檔並根據XML文檔內容創建一個節點的邏輯結構,文檔本身被認為是一個包含了所有其他節點的節點。
DOM使用戶能夠把文檔看成是一個有結構的信息樹,而不是簡單的文本流。這樣即使不知道XML的語義細節,應用程序或者是腳本也能夠方便地操作該結構。DOM包含兩個關鍵的抽象:一個樹狀的層次、另一個是用來表示文檔內容和結構的節點集合。樹狀層次包括了所有這些節點,節點本身也可以包含其他的節點。這樣的好處是對於開發人員來說,他可以通過這個層次結構來找到並修改相應的某一個節點的信息。DOM把節點看成是一個通常的對象,這樣就有可能創建一個劇本來裝載一個文檔,然後遍歷所有的節點,顯示感興趣的節點的信息。注意節點可以有很多種具體的類型,比如元素、屬性和文本都可以認為是一個節點。
微軟的MSXML解析器讀一個XML文檔,然後把它的內容解析到一個抽象的信息容器中稱為節點(NODES)。這些節點代表文檔的結構和內容,並允許應用程序來讀和操作文檔中的信息而不需要顯示知道的XML的語義。在一個文檔被解析以後,它的節點能夠在任何時候被瀏覽而不需要保持一定的順序。
對開發人員來說,最重要的編程對象是DOMDocument。DOMDocument對象通過暴露屬性和方法來允許瀏覽、查詢和修改XML文檔的內容和結構,每一個接下來的對象暴露自己的屬性和方法,這樣就能夠收集關於對象實例的信息,操作對象的值和結構,並導航到樹的其他對象上去。
MSXML.DLL所包括的主要的COM介面有:
DOM Document
DOMDocument對象是XML DOM的基礎,你可以利用它所暴露的屬性和方法來允許你瀏覽、查詢和修改XML文檔的內容和結構。DOMDocument表示了樹的頂層節點。它實現了DOM文檔的所有的基本的方法並且提供了額外的成員函數來支持XSL和XSLT。它創建了一個文檔對象,所有其他的對象都可以從這個文檔對象中得到和創建。
IXML DOMNode
IXMLDOMNode是文檔對象模型(DOM)中的基本的對象,元素,屬性,註釋,過程指令和其他的文檔組件都可以認為是IXMLDOMNode,事實上,DOMDocument對象本身也是一個IXMLDOMNode對象。
IXML DOM NodeList
IXMLDOMNodeList實際上是一個節點(Node)對象的集合,節點的增加、刪除和變化都可以在集合中立刻反映出來,可以通過“for...next”結構來遍歷所有的節點。
IXMLDOMParseError
IXMLDOMParseError介面用來返回在解析過程中所出現的詳細的信息,包括錯誤號,行號,字元位置和文本描述。
下面主要描述一個DOMDocument對象的創建過程,這裡用VC描述創建一個文檔對象的過程。
HRESULT hr;
IXMLDomDocument* pXMLDoc;
IXMLDOMNode* pXDN;
Hr=CoInitialize(NULL); //COM的初始化
//得到關於IXMLDOMDocument介面的指針pXMLDOC。
hr=CoCreateInstance(CLSID_DOM Document,NULL,CLSCTX_INPPROC_SERVER,
IID_IXMLDOMDocument,(void**) &pXMLDoc);
//得到關於IXMLDOMNode介面的指針pXDN。
hr=pXMLDoc->QueryInterface (IID_IXMLDOMNode,(void**)&pXDN);
解析標誌
在MSXML解析器使用過程中,我們可以使用文檔中的createElement方法來創建一個節點裝載和保存XML文件。通過load或者是loadXML方法可以從一個指定的URL來裝載一個XML文檔。Load(LoadXML)方法帶有兩個參數:第一個參數xmlSource表示需要被解析的文檔,第二個參數isSuccessful表示文檔裝載是否成功。Save方法是用來把文檔保存到一個指定的位置。Save方法有一個參數destination用來表示需要保存的對象的類型,對象可以是一個文件,一個ASP Response方法,一個XML文檔對象,或者是一個能夠支持持久保存(persistence)的客戶對象。
同時,在解析過程中,我們需要得到和設置解析標誌。利用不同的解析標誌,我們可能以不同的方法來解析一個XML文檔。XML標準允許解析器驗證或者不驗證文檔,允許不驗證文檔的解析過程跳過對外部資源的提取。另外,你可能設置標誌來表明你是否要從文檔中移去多餘的空格。
為了達到這個目的,DOMDocument對象暴露了下面幾個屬性,允許用戶在運行的時候改變解析器的行為:
(1)Async(相對於C++是兩個方法,分別為get_async和put_async)
(2)ValidateOnparse(相對於C++是兩個方法,分別為get_validateOnParse和 put_validateOnParse)
(3)ResolveExternals(相對於C++是兩個方法,分別為get_ ResolveExternals和put_ ResolveExternals)
(4)PersercveWhiteSpace(相對於C++是兩個方法,分別為get_ PersercveWhiteSpace和put_ Persercve WhiteSpace)
每一個屬性可以接受或者返回一個Boolean(布爾)值。預設的,anync,vali dateOnParse,resolveExternals的值為TRUE,perserveWhiteSpace的值跟XML文檔的設置有關,如果XML文檔中設置了xml:space屬性的話,該值為FALSE。
文檔信息的信息
同時在文檔解析過程中可以收集一些和文檔信息的信息,實際上在文檔解析過程中可以得到以下的信息:
(1)doctype(文檔類型):實際上是和用來定義文檔格式的DTD文件。如果XML文檔沒有相關的DTD文檔的話,它就返回NULL。
(2)implementation(實現):表示該文檔的實現,實際上就是用來指出當前文檔所支持的XML的版本。
(3)parseError(解析錯誤):在解析過程中最後所發生的錯誤。
(4)readyState(狀態信息):表示XML文檔的狀態信息,readyState對於非同步使用微軟的XML解析器來說的重要作用是提高了性能,當非同步裝載XML文檔的時候,你的程序可能需要檢查解析的狀態,MSXML提供了四個狀態,分別為正在狀態,已經狀態,正在解析和解析完成。
(5)url(統一資源定位):關於正在被裝載和解析的XML文檔的URL的情況。注意如果該文檔是在內存中建立的話,這個屬性返回NULL值。
在得到文檔樹結構以後,我們可以操作樹中的每一個節點,可以通過兩個方法得到樹中的節點,分別為nodeFromID和getElementsByTagName。
nodeFromID包括兩個參數,第一個參數idString用來表示ID值,第二個參數node返回指向和該ID相匹配的NODE節點的介面指針。注意根據XML的技術規定,每一個XML文檔中的ID值必須是唯一的,而且一個元素(element)僅且只能和一個ID相關聯。
getElementsByTagName方法有兩個參數,第一個參數tagName表示需要查找的元素(Element)的名稱,如果tagName為“*”的話返迴文檔中所有的元素(Element)。第二個參數為resultList,它實際是指向介面IXMLDOMNodeList的指針,用來返回和tagName(標籤名字)相關的所有的Node的集合。
最後討論一下如何來創建新的節點,實際上可以通過方法createNode來創建一個新的節點。CreateNode包括四個參數,第一個參數Type表示要創建的節點的類型,第二個參數name表示新節點的nodeName的值,第三個參數namespaceURI表示該節點相關的名字空間,第四個參數node表示新創建的節點。注意可以通過使用已經提供的類型(Type),名稱(name)和名字空間(nodeName)來創建一個節點。
當一個節點被創建的時候,它實際上是在一個命名空間範圍(如果已經提供了命名空間的話)內創建的。如果沒有提供名字空間的話,它實際上是在文檔的名字空間範圍內創建的。
XML文檔因為有著比HTML嚴格的多的語法要求,所以使用和編寫一個XML解析器要比編寫一個HTML的解析器要容易得多。同時因為XML文檔不僅可以標記文檔的顯示屬性,更重要的是它標記了文檔的結構和包含信息的特徵,所以可以方便地通過XML解析器來獲取特定節點的信息並加以顯示或修改,方便了用戶對XML文檔的操作和維護。同時我們需要注意的是XML是一種開放的結構體系並不依賴於任何一家公司,所以開發基於XML的應用必然會得到絕大多數軟體開發平台的支持。另外,可以看到,像微軟這樣的軟體開發主流企業也把目光定位在基於XML+COM的體繫上,無論是微軟的Office系列、Web伺服器和瀏覽器還是資料庫產品(SQL Server)都已經開始支持基於XML的應用。通過XML來定製應用程序的前端,COM來實現具體的業務對象和資料庫對象,使系統具有更加靈活的擴展性和維護性
基本信息
- 發行時間
- 2001年9月
- 使用類型
- 語言解析器