數據抽取
數據抽取
數據抽取是從數據源中抽取數據的過程。
實際應用中,數據源較多採用的是關係資料庫。從資料庫中抽取數據一般有以下幾種方式。
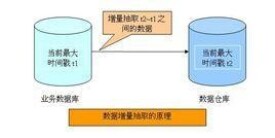
增量抽取指抽取自上次抽取以來資料庫中要抽取的表中新增、修改、刪除的數據。在ETL使用過程中。增量抽取較全量抽取應用更廣。如何捕獲變化的數據是增量抽取的關鍵。對捕獲方法一般有兩點要求:準確性,能夠將業務系統中的變化數據準確地捕獲到;性能,盡量減少對業務系統造成太大的壓力,影響現有業務。目前增量數據抽取中常用的捕獲變化數據的方法有:
a.觸發器:在要抽取的表上建立需要的觸發器,一般要建立插入、修改、刪除三個觸發器,每當源表中的數據發生變化,就被相應的觸發器將變化的數據寫入一個臨時表,抽取線程從臨時表中抽取數據。觸發器方式的優點是數據抽取的性能較高,缺點是要求在業務資料庫中建立觸發器,對業務系統有一定的性能影響。
b.時間戳:它是一種基於遞增數據比較的增量數據捕獲方式,在源表上增加一個時間戳欄位,系統中更新修改表數據的時候,同時修改時間戳欄位的值。當進行數據抽取時,通過比較系統時間與時間戳欄位的值來決定抽取哪些數據。有的資料庫的時間戳支持自動更新,即表的其它欄位的數據發生改變時,自動更新時間戳欄位的值。有的資料庫不支持時間戳的自動更新,這就要求業務系統在更新業務數據時,手工更新時間戳欄位。同觸發器方式一樣,時間戳方式的性能也比較好,數據抽取相對清楚簡單,但對業務系統也有很大的傾入性(加入額外的時間戳欄位),特別是對不支持時間戳的自動更新的資料庫,還要求業務系統進行額外的更新時間戳操作。另外,無法捕獲對時間戳以前數據的delete和update操作,在數據準確性上受到了一定的限制。
c.全表比對:典型的全表比對的方式是採用MD5校驗碼。ETL工具事先為要抽取的表建立一個結構類似的MD5臨時表,該臨時表記錄源表主鍵以及根據所有欄位的數據計算出來的MD5校驗碼。每次進行數據抽取時,對源表和MD5臨時表進行MD5校驗碼的比對,從而決定源表中的數據是新增、修改還是刪除,同時更新MD5校驗碼。MD5方式的優點是對源系統的傾入性較小(僅需要建立一個MD5臨時表),但缺點也是顯而易見的,與觸發器和時間戳方式中的主動通知不同,MD5方式是被動的進行全表數據的比對,性能較差。當表中沒有主鍵或唯一列且含有重複記錄時,MD5方式的準確性較差。
d.日誌對比:通過分析資料庫自身的日誌來判斷變化的數據。Oracle的改變數據捕獲(CDC,Changed Data Capture)技術是這方面的代表。CDC 特性是在Oracle9i資料庫中引入的。CDC能夠幫助你識別從上次抽取之後發生變化的數據。利用CDC,在對源表進行insert、update或 delete等操作的同時就可以提取數據,並且變化的數據被保存在資料庫的變化表中。這樣就可以捕獲發生變化的數據,然後利用資料庫視圖以一種可控的方式提供給目標系統。CDC體系結構基於發布者/訂閱者模型。發布者捕捉變化數據並提供給訂閱者。訂閱者使用從發布者那裡獲得的變化數據。通常,CDC系統擁有一個發布者和多個訂閱者。發布者首先需要識別捕獲變化數據所需的源表。然後,它捕捉變化的數據並將其保存在特別創建的變化表中。它還使訂閱者能夠控制對變化數據的訪問。訂閱者需要清楚自己感興趣的是哪些變化數據。一個訂閱者可能不會對發布者發布的所有數據都感興趣。訂閱者需要創建一個訂閱者視圖來訪問經發布者授權可以訪問的變化數據。CDC分為同步模式和非同步模式,同步模式實時的捕獲變化數據並存儲到變化表中,發布者與訂閱都位於同一資料庫中。非同步模式則是基於Oracle的流複製技術。
ETL處理的數據源除了關係資料庫外,還可能是文件,例如txt文件、excel文件、xml文件等。對文件數據的抽取一般是進行全量抽取,一次抽取前可保存文件的時間戳或計算文件的MD5校驗碼,下次抽取時進行比對,如果相同則可忽略本次抽取。
DMCTextFilter 是HYFsoft開發的純文本抽出通用程序庫,本產品可以從各種各樣的文檔格式的數據中或從插入的OLE對象中,完全除掉特殊控制信息,快速抽出純文本數據信息。便於用戶實現對多種文檔數據資源信息進行統一管理,編輯,檢索和瀏覽。
DMCTextFilter採用了先進的多語言、多平台、多線程的設計理念,支持多國語言(英語,中文簡體,中文繁體,日本語,韓國語),多種操作系統(Windows,Solaris,Linux,IBM AIX,Macintosh,HP-UNIX),多種文字集合代碼(GBK,GB18030,Big5,ISO-8859-1,KS X 1001,Shift_JIS,WINDOWS31J,EUC-JP,ISO-10646-UCS-2,ISO-10646-UCS-4,UTF-16,UTF-8等)。提供了多種形式的API功能介面(文件格式識別函數,文本抽出函數,文件屬性抽出函數,頁抽出函數,設定User Password的PDF文件的文本抽出函數等),便於用戶方便使用。用戶可以十分便利的將本產品組裝到自己的應用程序中,進行二次開發。通過調用本產品的提供的API功能介面,實現從多種文檔格式的數據中快速抽出純文本數據。本產品在國內外得到了廣泛的應用,在產品性能和質量上都得到了用戶高度的好評。
1. 文件格式自動識別功能
本產品通過解析文件內部的信息,自動識別生成文件的應用程序名和其版本號,不依賴於文件的擴展名,能夠正確識別文件格式和相應的版本信息。可以識別的文件格式如下:支持Microsoft Office、RTF、PDF、Visio、Outlook EML和MSG、Lotus1-2-3、HTML、AutoCAD DXF和DWG、IGES、PageMaker、ClarisWorks、AppleWorks、XML、WordPerfect、Mac Write、Works、Corel Presentations、QuarkXpress、DocuWorks、WPS、壓縮文件的LZH/ZIP/RAR以及一太郎、OASYS等文件格式
2. 文本抽出功能
即使系統中沒有安裝作成文件的應用程序,可以從指定的文件或插入到文件中的OLE中抽出文本數據。
3. 文件屬性抽出功能
從指定的文件中,抽出文件屬性信息。
4. 頁抽出功能
從文件中,抽出指定頁中文本數據。
5. 對加密的PDF文件文本抽出功能
從設有打開文檔口令密碼的PDF文件中抽出文本數據。
6. 流(Stream)抽出功能
從指定的文件、或是嵌入到文件中的OLE對象中向流里抽取文本數據。
7. 支持的語言種類
本產品支持以下語言:英語,中文簡體,中文繁體,日本語,韓國語
8. 支持的字符集合的種類
抽出文本時,可以指定以下的字符集合作為文本文件的字符集(也可指定任意特殊字符集,但需要另行定製開發):GBK,GB18030,Big5,ISO-8859-1,KS X 1001,Shift_JIS,WINDOWS31J,EUC-JP,ISO-10646-UCS-2,ISO-10646-UCS-4,UTF-16,UTF-8等。
基本信息
- 中文名
- 數據抽取
- 外文名
- Data extraction
- 方式
- 全量抽取
- 功能
- 頁抽出功能
- 要求
- 準確性